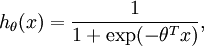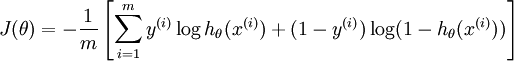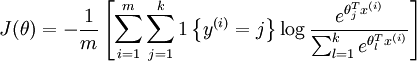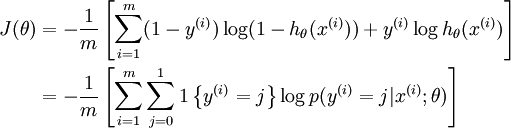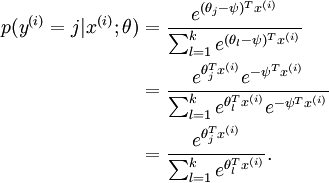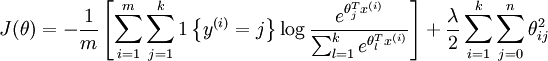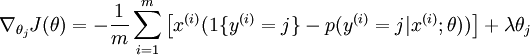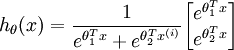标签:des style http io os ar strong for sp
This model generalizes logistic regression to classification problems where the class label y can take on more than two possible values.
Softmax regression is a supervised learning algorithm, but we will later be using it in conjuction with our deep learning/unsupervised feature learning methods.
With logistic regression, we were in the binary classification setting, so the labels were
. Our hypothesis took the form:
and the model parameters θ were trained to minimize the cost function
In the softmax regression setting, we are interested in multi-class classification (as opposed to only binary classification), and so the label y can take on k different values, rather than only two.
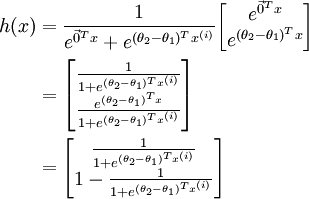
Given a test input x, we want our hypothesis to estimate the probability that p(y = j | x) for each value of 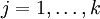 . I.e., we want to estimate the probability of the class label taking on each of the k different possible values. Thus, our hypothesis will output a k dimensional vector (whose elements sum to 1) giving us our k estimated probabilities. Concretely, our hypothesis hθ(x) takes the form:
. I.e., we want to estimate the probability of the class label taking on each of the k different possible values. Thus, our hypothesis will output a k dimensional vector (whose elements sum to 1) giving us our k estimated probabilities. Concretely, our hypothesis hθ(x) takes the form:
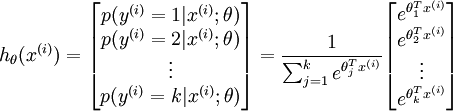
Here 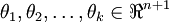 are the parameters of our model. Notice that the term
are the parameters of our model. Notice that the term 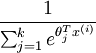 normalizes the distribution, so that it sums to one.
normalizes the distribution, so that it sums to one.
For convenience, we will also write θ to denote all the parameters of our model. When you implement softmax regression, it is usually convenient to represent θ as a k-by-(n + 1) matrix obtained by stacking up  in rows, so that
in rows, so that
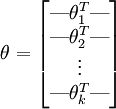 theta 为k*(n+1)维的矩阵
theta 为k*(n+1)维的矩阵
Our cost function will be:
Notice that this generalizes the logistic regression cost function, which could also have been written:
is the indicator function, so that 1{a true statement} = 1, and 1{a false statement} = 0.
The softmax cost function is similar, except that we now sum over the k different possible values of the class label. Note also that in softmax regression, we have that
.
Softmax regression has an unusual property that it has a "redundant" set of parameters. To explain what this means, suppose we take each of our parameter vectors θj, and subtract some fixed vector ψ from it, so that every θj is now replaced withθj ? ψ (for every
In other words, subtracting ψ from every θj does not affect our hypothesis‘ predictions at all! This shows that softmax regression‘s parameters are "redundant." More formally, we say that our softmax model is overparameterized, meaning that for any hypothesis we might fit to the data, there are multiple parameter settings that give rise to exactly the same hypothesis function hθ mapping from inputs x to the predictions.
Further, if the cost function J(θ) is minimized by some setting of the parameters
, then it is also minimized by
for any value of ψ. Thus, the minimizer of J(θ) is not unique. (Interestingly, J(θ) is still convex, and thus gradient descent will not run into a local optima problems. But the Hessian is singular/non-invertible, which causes a straightforward implementation of Newton‘s method to run into numerical problems.)
Notice also that by setting ψ = θ1, one can always replace θ1 with
(the vector of all 0‘s), without affecting the hypothesis. Thus, one could "eliminate" the vector of parameters θ1 (or any other θj, for any single value of j), without harming the representational power of our hypothesis. Indeed, rather than optimizing over the k(n + 1) parameters
), one could instead set
and optimize only with respect to the (k ? 1)(n + 1)remaining parameters, and this would work fine. 降一维
In practice, however, it is often cleaner and simpler to implement the version which keeps all the parameters
, without arbitrarily setting one of them to zero. But we will make one change to the cost function: Adding weight decay. This will take care of the numerical problems associated with softmax regression‘s overparameterized representation.
We will modify the cost function by adding a weight decay term
which penalizes large values of the parameters. Our cost function is now
With this weight decay term (for any λ > 0), the cost function J(θ) is now strictly convex, and is guaranteed to have a unique solution. The Hessian is now invertible, and because J(θ) is convex, algorithms such as gradient descent, L-BFGS, etc. are guaranteed to converge to the global minimum.
To apply an optimization algorithm, we also need the derivative of this new definition of J(θ). One can show that the derivative is:
In the special case where k = 2, one can show that softmax regression reduces to logistic regression. This shows that softmax regression is a generalization of logistic regression. Concretely, when k = 2, the softmax regression hypothesis outputs
Taking advantage of the fact that this hypothesis is overparameterized and setting ψ = θ1, we can subtract θ1 from each of the two parameters, giving us
Thus, replacing θ2 ? θ1 with a single parameter vector θ‘, we find that softmax regression predicts the probability of one of the classes as
, and that of the other class as
, same as logistic regression.
Suppose you are working on a music classification application, and there are k types of music that you are trying to recognize. Should you use a softmax classifier, or should you build k separate binary classifiers using logistic regression?
This will depend on whether the four classes are mutually exclusive. For example, if your four classes are classical, country, rock, and jazz, then assuming each of your training examples is labeled with exactly one of these four class labels, you should build a softmax classifier with k = 4. (If there‘re also some examples that are none of the above four classes, then you can set k = 5 in softmax regression, and also have a fifth, "none of the above," class.) 相互独立 —— softmax
If however your categories are has_vocals, dance, soundtrack, pop, then the classes are not mutually exclusive; for example, there can be a piece of pop music that comes from a soundtrack and in addition has vocals. In this case, it would be more appropriate to build 4 binary logistic regression classifiers. This way, for each new musical piece, your algorithm can separately decide whether it falls into each of the four categories. 不相互独立(之间有交集) —— k binary logistic regression classifiers
Now, consider a computer vision example, where you‘re trying to classify images into three different classes. (i) Suppose that your classes are indoor_scene, outdoor_urban_scene, and outdoor_wilderness_scene. Would you use sofmax regression or three logistic regression classifiers? (ii) Now suppose your classes are indoor_scene, black_and_white_image, and image_has_people. Would you use softmax regression or multiple logistic regression classifiers?
In the first case, the classes are mutually exclusive, so a softmax regression classifier would be appropriate. In the second case, it would be more appropriate to build three separate logistic regression classifiers.
标签:des style http io os ar strong for sp
原文地址:http://www.cnblogs.com/sprint1989/p/3974364.html