博主本人在以前就挺好奇知乎那群答主的答案数据从哪里的, 别人说是从网上爬的(搞安全的同学例外)。由于本人最近比较闲的,所以就起了学习写网络爬虫的心思(所以兴趣很重要!)。打开浏览器,百度了下网络爬虫,什么用python写网络爬虫的的比较多,所以就用它了(好随便的赶脚). 然后我开始搜索有关用python写的网络爬虫的网络博客(主要是入门的教程指导类 ),看了下博客,怎么说呢,网上各博客主个个实力都不错,知识结构都非常的清晰,讲解的都非常细致,非常浅显易懂,但总感觉少了点什么,仔细想了下应该是大部分博客都注重知识本身,而轻视获取知识的过程(我觉得这个最有意思),没啥成就感,自我感觉挺无聊(总感觉有天朝教育的影子,我写你抄)。所以准备换个角度,从学习者角度写一些自认为有意思的东西。
言归正传,在接触网络爬虫这个名词,我的第一反应是它是啥东东,它能干啥,该怎么做(。。。怎么感觉像在读书时在写论文。。。)。当然你可以百度,想了下还是不要贴百度的定义(不要打我),先说下自己对这个专业术语的理解吧,由于博主也才学几天理解非常浅薄,希望各位读者理解,我个人认为:网络爬虫就是个定制化的互联网信息采集程序(当然,以后可能有不同的理解,认知总不断变化地。)。它能够针对性对各网站的信息进行提取和分类(比如我要想知道淘宝有多少家店铺,各店主都是些谁怎么办,你就运用爬虫技术爬取整个淘宝网)。说了这么多废话,主要是希望大家对新事物有自己的见解,也希望读者老爷们多点耐心(这个话痨。。。。)
这次是真的“言归正传”,作为一个目标驱动型的学习者,我十分喜欢在学习一个新东西前制定“作战计划”,在做的过程中去学习,而不是学完后在做。比如我想去爬取糗事百科所有用户的用户名,我该怎么做呢?有人说,先把python语法会用后,在学urllib或 requests之类的库学会http请求的啥,然后去学正则表达或 Beautiful Soup,lxml 之类的库去解析啥,可能你还有去学一些前端的一些东西,比如html css,xml 之类的东东,接着还要去学一些mysql 或oracle,sqlite ,sqlserver之类数据库操作一些东东,我的天啊 ,我只是想知道知道怎么爬糗事百科网的用户名,怎么还要学这么多,许多人看着这长长的学习路线傻眼了,然后就gg了。所以,让我们回到最初的起点,从实际问题出发。首先,不去管用啥语言,会啥语法,不要去学啥urllib, lxml,xml ,mysql 之类的东东,先仔细分析下如何去爬取糗事百科所有用户的用户名这个实际问题。
先想一下你是如何知道糗事百科网的别人的用户名,有人说,那还不简单,百度搜下糗事百科,打开糗事百科官网 https://www.qiushibaike.com/ ,不就看到了吗。对!就是这样简单,所有爬虫程序所干的事情都是这样的,它也是打开一个网站,然后根据所设规则提取出我们所需要的信息,然后保存下来 ,只不过一个是通过人眼看到,一个是爬虫程序自动提取信息,一个是记在脑子里(可能过下就忘了),一个是保存在磁盘中(你只要不删除,估计大概可能能保持20,30年)。虽然方式有所不同,但是他们的思想是共通的。简单来讲,就三步,打开网页-提取信息-保存信息。
那么,如何让程序能打开我们想要的网站呢?你可以试着通过百度搜下,比如什么“如何用python打开网站之类的”,"python 打开网站的几种方式“ 之类的关键字,当然,你也可以去论坛csdn,知乎等论坛提问。我当时试着搜索下,搜到了这个网站 http://blog.csdn.net/Winterto1990/article/details/47660543 。这个网站介绍了四种方法,这里就第一种为例子 ,代码如下:
import urllib url="http://www.baidu.com" #这里是需要获取的网页 content=urllib.open(url).read() #使用urllib模块获取网页内容 print content #输出网页的内容 功能相当于查看网页源代码
在运行之前 ,先简单说下,我的python版本是2.7.12,所用的ide(集成开发环境)是pycharm,至于如何下载这两软件可以参考下面两个网站:一个是python的官网: https://www.python.org/downloads/ ;一个是pycharm的官网: https://www.jetbrains.com/pycharm/ ,下载教程链接:http://blog.csdn.net/qq_29883591/article/details/52664478
好了。运行开始。。。。。。,怎么运行不起!,这不科学啊!

先别急,看一下ide提示啥(哈 都是e文,和我一样英文弱的同学快去背单词吧,你会收益终身),大概意思是这个文件不是 ascii,没有设置文件编码 。打开百度 ,输入如下关键字”如何为python设置文件编码“之类,你就可以知道在文件开头原来还需要设置这一句”# -*- coding: utf-8 -*-“
让我们加上这一句开始运行,代码如下:
# -*- coding: utf-8 -*- import urllib url="http://www.baidu.com" #这里是需要获取的网页 content=urllib.open(url).read() #使用urllib模块获取网页内容 print content #输出网页的内容 功能相当于查看网页源代码
坑啊 ,怎么还是运行不起来 。。。我了个擦

冷静,冷静, 冷静啊 ,看一下ide提示啥 AttributeError: ‘module‘ object has no attribute ‘open‘ ,大概意思是说属性错误:“模块”对象没有属性“open” ,这他喵的啥意思。这个时候你应该想这还不简单,直接把这句话复制到百度里搜下不就行了,我当时就是这样想在,然后浪费了10几分钟一无所获,最后只能自己解决了。 我又是怎么解决的呢?首先 ,通过这个ide提示我知道了错误出在这一句代码上 content=urllib.open(url).read() , 然后我开始重新审视这端代码 ,从字面上看,这句话的意思是用urlib这个东西打开这个网站 ,然后在读取这个网站的内容,所以问题要么出在打开这个网站 上,要么是在读取上。接着 ,我就手动输入urllib. ,神奇的事情发生了(后来才知道是代码自动补全),出现了如下界面,我看了这个urlopen 想了想, 试不试可以用这个来试下,果然成功了!(兴奋了)
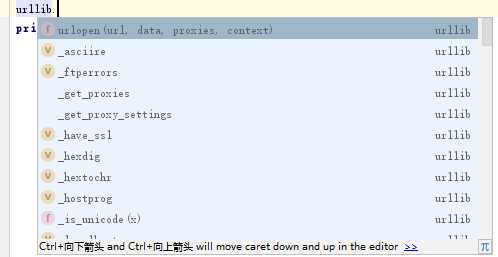
完整代码:
# -*- coding: utf-8 -*- import urllib url="http://www.baidu.com" #这里是需要获取的网页 content=urllib.urlopen(url).read() #使用urllib模块获取网页内容 print content #输出网页的内容 功能相当于查看网页源代码
接着,我们开始打开糗事百科页面,替换下网址就行:
# -*- coding: utf-8 -*- import urllib url="https://www.qiushibaike.com/" #这里是需要获取的网页 content=urllib.urlopen(url).read() #使用urllib模块获取网页内容 print content #输出网页的内容 功能相当于查看网页源代码
开始运行。 又有错了 !
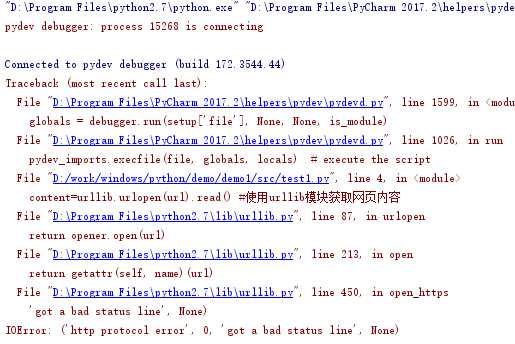
老规矩,先看提示