基于数据集的处理:从物理存储上加载数据,然后操作数据,然后写入物理存储设备。比如Hadoop的MapReduce。
缺点:1.不适合大量的迭代 2. 交互式查询 3. 不能复用曾经的结果或中间计算结果
基于工作集的处理:如Spark的RDD。
RDD具有如下的弹性:
1. 自动的进行内存和磁盘数据存储的切换
2. 基于Lineage的高效容错
3. Task如果失败会自动进行特定次数的重试
4. Stage如果失败会自动进行特定次数的重试,而且只会计算失败的分片
5. Checkpoint和persist (用于计算结果复用)
6. 数据分片的高度弹性
RDD的写操作是粗粒度的,读操作既可以是粗粒度的也可以是细粒度的.
RDD是分布式函数式编程的抽象。
RDD通过记录数据更新的方式为何高效?
1. RDD是不可变的 + lazy
创建RDD的几种方式:1. 程序中的集合(主要用于测试) 2. 使用本地文件系统(主要用于测试较大量的数据) 3. 使用HDFS 4. 基于DB。5. 基于S3 6. 基于数据流
RDD 依赖分为宽依赖和窄依赖
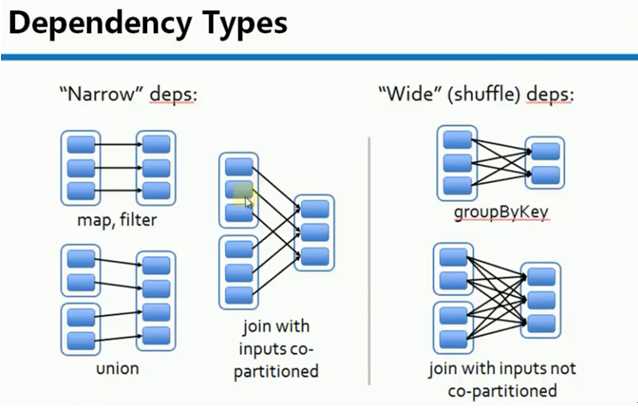
1. 窄依赖是指每个父RDD的Partition最多被子RDD的一个Partition使用。例如:map, filter等会产生窄依赖
2. 宽依赖是指一个父RDD的Partition会被多个子RDD的Partition使用。例如:groupByKey,reduceByKey等会产生宽依赖
宽依赖会产生Shuffle
特别说明:对于join操作有两种情况,如果说join的时候,每个Partition仅仅和已知的Partition进行join,则此时的join操作就是窄依赖;其它情况是宽依赖.
窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖(也就是说对父RDD的依赖的Partition的数量不会随着RDD数据规模的改变而改变)
Stage的划分:
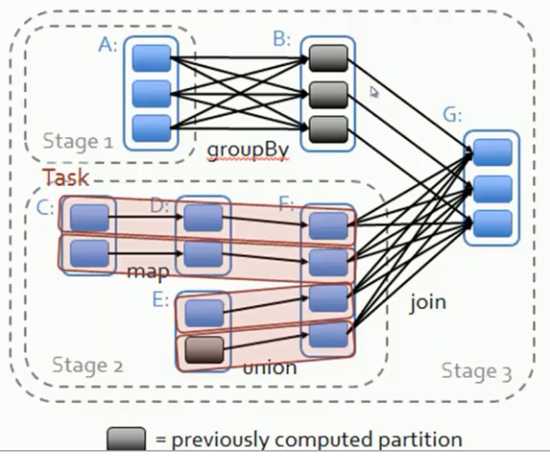
1. 从后往前推,遇到宽依赖就断开,遇到窄依赖就把当前RDD加入到Stage中
2. 每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的。
3. 最后一个Stage里面的任务类型是ResultTask,前面其它所有的Stage里面的任务的类型是ShuffleMapTask