Haskell手撸Softmax回归实现MNIST手写识别
前言
初学Haskell,看的书是Learn You a Haskell for Great Good, 才刚看到Making Our Own Types and Typeclasses这一章。 为了加深对Haskell的理解,便动手写了个Softmax回归。纯粹造轮子,只用了base。 显示图片虽然用了OpenGL,但是本文不会提到关于OpenGL的内容。虽说是造轮子, 但是这轮子造得还是使我受益匪浅。Softmax回归方面的内容参考了Tensorflow的新手教程。
- 读取MNIST数据集
- 相关符号解释
- Softmax回归
- Cross Entropy
- Gradient Descent
- 实验结果
读取MNIST数据集
读取数据集很简单,用openBinaryFile打开文件,mallocBytes申请内存空间, 再用hGetBuf将文件中的内容写入内存,然后使用peekByteOff将指定地址中的像素值取出, 放到[[Double]]里返回即可。因为惰性求值并不会在你用到相关数据前就提前就将文件内容全部读取, 所以建议一张一张读取图片放入[[Double]]返回,而不是一次性读取所有图片放入[[[Double]]]返回。
相关符号解释
- \\(X\\) 为输入数据的向量,由图片的像素点组成,在MNIST的例子中有784个分量
- \\(W\\) 为权重矩阵,大小为784*10
- \\(B\\) 为偏置量矩阵,有10个分量
- \\(Y\\) 为预测值的向量,有10个分量,对应10个数字的取值概率
- \\(T\\) 为真实值的向量,也是10个分量,由MNIST的Label制得
Softmax回归
对于Haskell来讲,行向量要比列向量效率更高,因为行向量可以直接用一个列表来存储, 而列向量就不得不存储为[[Double]],所以在这里我把\\(X\\) 当成一个784维的行向量, \\(W\\) 为一个784*10的矩阵。同时\\(evidence\\) 为
\[evidence = XW+B \]
Softmax为
\[Y = softmax\left( evidence \right) = normalize\left( exp\left( evidence \right) \right) \]
这里在实现代码时要注意一些问题,指数函数很容易造成运算溢出, 第一个问题是 \\(\lim _{x\rightarrow-\infty}{{e}^{x}}=0\\)。 所以当exp的运算结果超出了Double类型所能表示的最小值时,exp函数的返回值是0。 这听起来似乎没什么问题,但是当我们对十个全是0的数字normalize时,其总和也为0, 将总和作为分母来计算,自然就会溢出。
针对这一问题,我自以为能够通过平移来解决。因为
\[\frac {{e}^{a+b}}{\sum {e}^{c+b}} = \frac {{e}^{a}{e}^{b}}{{e}^{b}\sum{{e}^{c}}} = \frac {{e}^{a}}{\sum{e}^{c}} \]
所以,我们可以让evidence的每一个分量减去其平均数,这样就可以避免\\(exp(evidence)\\) 的元素全为零的问题, 同时计算结果和本来理论上的结果,也是一致的。
第二个问题是 \\(\lim _{x\rightarrow+\infty}{{e}^{x}}=+\infty\\) 。 如果evidence全体的取值总体偏大,也可以通过减去其平均数的方法来解决,但有些时候, y的某个分量非常逼近1.0,这就说明evidence的平均数非常接近0,如果那个分量的evidence非常大, 使得exp运算溢出,就无法通过减平均数的方法来解决。exp使得evidence的各分量中, 正数之间的差距变得非常巨大,而负数之间的差距要比线性的差距更小。因此我们可以把evidence整体向左偏移, 那些特别小的数值,就直接作为0计算,只要分量的最大值不会使exp运算溢出就可以了。 因此,evidence和softmax之间还要有一个中间阶段来解决这两个问题。
\[z = evi - \bar{evi} \] \[z := z - c \quad \left(until \quad max \{{z}\} < c \right) \]
上式中的c为exp所能计算的最大数值,直到z向量中的所有元素都小于这个值时,再将z放入Softmax中计算
以下为上述内容的实现代码
type Vector a = [a]
type Mat a = [Vector a]
-- 图方便,所以直接返回空矩阵表示运算出错,而没用Maybe
matMul :: (Num a) => Mat a -> Mat a -> Mat a
mat1 `matMul` mat2 =
if matCols mat1 == matRows mat2
then [[vectorDot vec1 vec2 | vec2 <- transpose mat2] | vec1 <- mat1]
else [[]]
matToVector :: Mat a -> Vector a
matToVector = concat
vectorToMat :: Vector a -> Mat a
vectorToMat vec = [vec]
layer :: Vector Double -> Mat Double -> Vector Double
layer xs ws = matToVector ( (vectorToMat xs) `matMul` ws )
biasLayer :: Vector Double -> Vector Double -> Vector Double
biasLayer xs bias = zipWith (+) xs bias
evidence :: Vector Double -> Mat Double -> Vector Double -> Vector Double
evidence xs ws bias = biasLayer (layer xs ws) bias
softmax :: Vector Double -> Vector Double
softmax vec = map (\x -> exp x / sum (map exp safeVec)) safeVec
where
safeVec = maxSafe $ minusMean vec
minusMean v = map (\x -> x - mean v) v
maxSafe v = if maximum v > 500
then maxSafe $ map (flip (-) 500) v
else v
-- 虽然我并没有确切地去寻找exp所能计算的最大自变量值为多少,但只要小于500,exp就不会溢出
Cross Entropy
我个人对于交叉熵的理解并不深入,时至今日都不是很明白其原理,如果有机会,最想去学一下信息论
\[H = -\sum T .* log\left(Y\right) \]
实际上这个步骤只存在于我们的推导过程中,它不需要被实现,因为我们训练模型和使用模型的过程中都用不着它。 但我还是写了代码来实现它。实现过程需要注意的是,这里也很容易出现运算溢出的问题。因为很有可能Y的某个分量为0。 从数学上来讲,exp函数计算出来的值是不可能为0的,但谁叫我们是和计算机打交道的,浮点数的表示是有范围限制的, 所以我们就不得不防其为0的情况出现。这里我也没有好办法,\\(\lim _{x\rightarrow0}{log x = -\infty}\\) , 那么我们就拿一个非常小同时又不会使log溢出的数来替代0 使用好了,当Y的分量小于那个数时, 就返回那个非常小的数,否则就返回原值。因为实在没有想到好办法,所以我也就只能去忍受误差了。
具体的代码实现如下
vectorDot :: (Num a) => Vector a -> Vector a -> a
vectorDot vec1 vec2 = sum $ zipWith (*) vec1 vec2
crossEntropy :: Vector Double -> Vector Double -> Double
crossEntropy real hypo = -(vectorDot real $ map log $ check hypo)
where
check v = map (\x -> if x < 1.0e-300 then 1.0e-300 else x) v
-- 虽然1.0e-300并不是log所能计算的最小自变量,但是这也算是够小了
Gradient Descent
这是整个过程中最难的一步,求导并不是最难的,思考如何实现代码可真是烧了我不少脑细胞
Gradient Descent
\[{w}_{ij} := {w}_{ij} - \alpha \frac {\partial H} {\partial {w}_{ij}} \] \[\frac {\partial H} {\partial {w}_{ij}} = \frac {\partial \left(-\sum _{k=1}^{10}{t}_{k}\times log({y}_{k})\right)} {\partial {w}_{ij}} \\ = \sum _{k=1}^{m}{\frac{\partial \left( -{t}_{k} log \frac{e^{z}_{k}}{\sum _{l=1}^{m}{{e}^{{z}_{l}}}} \right)}{\partial {w}_{ij}}} \\ = \sum _{k=1}^{m}{\frac{\partial {t}_{k} \left( log \sum _{l=1}^{m}{{e}^{{z}_{l}}} -{z}_{k} \right)}{\partial {w}_{ij}}} \\ = \sum _{k=1}^{m}{tk \left( \frac{\partial log \sum _{l=1}^{m}{{e}^{l}}}{\partial{w}_{ij}} - \frac{\partial {z}_{k}}{\partial {w}_{ij}} \right) } \\ = \sum _{k=1}^{m}{tk \left(\frac {{e}^{{z}_{i}}}{\sum _{l=1}^{m}{{e}^{{z}_{l}}}} \frac{\partial {z}_{i}}{\partial{w}_{ij}} - \frac{\partial {z}_{k}}{\partial {w}_{ij}} \right) } \\ = \sum _{k=1}^{m}{tk ({y}_{i} - u) \frac{\partial {z}_{i}}{\partial {w}_{ij}}} ,\quad u = \begin{Bmatrix} 1 , k = i \\ 0 , k \neq i \end{Bmatrix} \]
同理可得偏置量的更新方式
\[\frac {\partial H} {\partial {b}_{i}} = \sum _{k=1}^{m}{tk ({y}_{i} - u) \frac{\partial {z}_{i}}{\partial {b}_{i}}} ,\quad u = \begin{Bmatrix} 1 , k = i \\ 0 , k \neq i \end{Bmatrix} \]
具体实现代码如下,我的实现方式十分拙劣,应该说是太拙劣了,对Haskell的理解也不够,如果再多深入一些,代码应该就不会这样了。 而且,这里gradient descent停止更新参数是以偏导数矩阵的平均值小于0.05为判断依据的, 我自知这种做法很不好,相对用矩阵最大值小于0.05更好,效率又高效果又好,但是后来忘了改了。。。
matRows :: Mat a -> Int
matRows mat
| matCols mat == 0 = 0
| matCols mat /= 0 = length mat
matCols :: Mat a -> Int
matCols = length . (!!0)
matMap :: (a -> a) -> Mat a -> Mat a
matMap f = map (map f)
-- 同上,为了偷懒而没用Maybe
matZipWith :: (a -> b -> c) -> Mat a -> Mat b -> Mat c
matZipWith f mat1 mat2 =
if matRows mat1 == matRows mat2 && matCols mat1 == matCols mat2
then zipWith (zipWith f) mat1 mat2
else [[]]
diffWs :: Vector Double -> Vector Double -> Vector Double -> Int -> Int -> Double
diffWs ts zs xs i j = sum $ zipWith (\t k -> t*(xs!!i)*((softmax zs !! j) - if j == k then 1 else 0)) ts [0..9]
diffBias :: Vector Double -> Vector Double -> Int -> Double
diffBias ts zs i = sum $ zipWith (\t k -> t*((softmax zs !! i) - if i == k then 1 else 0)) ts [0..9]
diffWsMat :: Vector Double -> Vector Double -> Vector Double -> Mat Double -> Mat Double
diffWsMat ts zs xs ws = matZipWith (diffWs ts zs xs) rows cols
where
cols = replicate (matRows ws) [0..(matCols ws - 1)]
rows = transpose $ replicate (matCols ws) [0..(matRows ws - 1)]
diffBiasVec :: Vector Double -> Vector Double -> Vector Double -> Vector Double
diffBiasVec ts zs bias = map (diffBias ts zs) [0..9]
gradientDescent :: Vector Double -> Vector Double -> Mat Double -> Vector Double -> Double -> (Mat Double, Vector Double)
gradientDescent ts xs ws bias alpha
| matMean dWsMat < 0.05 && mean dBiasVec < 0.05 = (trainedWs, trainedBias)
| otherwise = gradientDescent ts xs trainedWs trainedBias alpha
where
trainedWs = matZipWith (-) ws $ matMap (*alpha) dWsMat
trainedBias = zipWith (-) bias $ map (*alpha) dBiasVec
zs = evidence xs ws bias
dWsMat = diffWsMat ts zs xs ws
dBiasVec = diffBiasVec ts zs bias
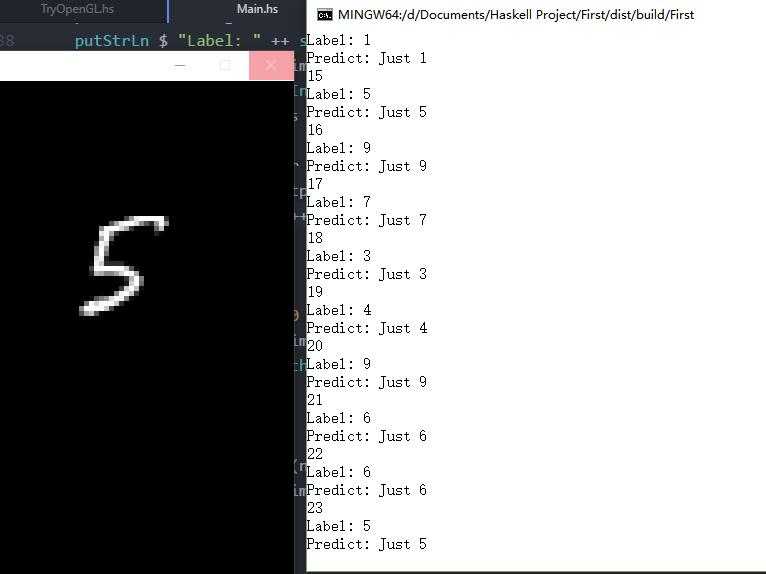
实验结果
速度还是挺差的,和TensorFlow当然是没得比,60000张图片训练了5个小时左右。 用测试数据集的10000张图片进行测试,效果还是挺差的,正确率为86.07%,TensorFlow教程的正确率为91%。 正确率较低的原因,我猜测大体应该在这么两个方面,一是教程中的batch为100,我这里为1; 二是,ws和bias的偏导数矩阵的平均值小于0.05并不能保证每个元素都小于0.05,因此导致收敛效果较差。 因为训练一次耗时太久,所以这东西我也就懒得继续去优化它了。
通过Haskell的FFI应该可以调用CUDA,以后如果有机会,再去尝试,现在应该去应付期末考试了。