CNN中减少参数的2两个规则:
1、局部感知。生物学中,视觉皮层的神经元是局部感知信息的,只响应某些特定区域的刺激;图像的空间联系中,局部的像素联系较为紧密,距离较远的像素相关性较弱。
这个对应于算法中卷积核的大小,mnist手写识别在28*28的像素中取patch为5*5。
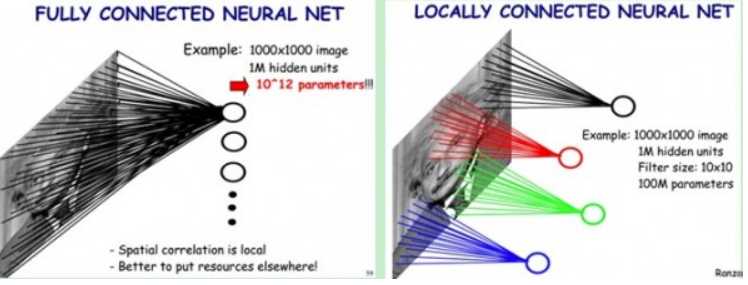
上图中:左边是全连接,右边是局部连接。
2、权值共享。每个神经元对应的参数(权值)都相等。隐含的原理是:图像的一部分的统计特性与其他部分是一样的。那么在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,都能使用同样的学习特征。
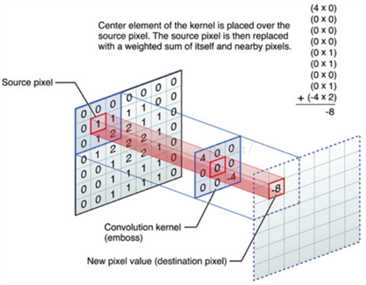
注:卷积可参考数字图像处理中的滤波处理,滤波就是对于大矩阵中的每个像素, 计算它周围像素和滤波器(卷积核)矩阵对应位置元素的乘积, 然后把结果相加到一起, 最终得到的值就作为该像素的新值, 这样就完成了一次滤波。该过程也叫卷积,区别在于,图像卷积计算,需要先翻转卷积核, 也就是绕卷积核中心旋转 180度。
以下转自http://blog.csdn.net/mao_xiao_feng/article/details/78004522
1)tf卷积函数
惯例先展示函数:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)除去name参数用以指定该操作的name,与方法有关的一共五个参数:
-
input:
指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一 -
filter:
相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维 -
strides:卷积时在图像每一维的滑动步长,这是一个一维的向量,长度4
-
padding:
string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同的卷积方式(“SAME”允许卷积核停留在图像边缘,保证输入与输出大小相同;“valid”则卷积核不能停留在图像边缘,输出图像会变小,若输入5*5,使用3*3卷积核,则输出3*3) -
use_cudnn_on_gpu:
bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map。
2)tf最大值池化函数
tf.nn.max_pool(value, ksize, strides, padding, name=None)
参数是四个,和卷积很类似:
第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape
第二个参数ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1
第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]
第四个参数padding:和卷积类似,可以取‘VALID‘ 或者‘SAME‘
返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式。
总结:卷积或池化后特征图谱的大小主要取决于滑动步长(strides)和padding(边距处理方式)。strides=1,padding=‘SAME’,则输入与输出大小相同;strides=2或padding=‘valid’都会使输出图像变小。