1. Spark 程序在运行的时候分为 Driver 和 Executor 两部分;
2. Spark 的程序编写是基于 SparkContext 的,具体来说包含两方面:
a) Spark 编程的核心基础 RDD, 是由 SparkContext 来最初创建
b) Spark 程序的调度优化也是基于 SparkContext
3. Spark 程序的注册是通过 SparkContext 实例化时候生成的对象来完成的(其实是 SchedulerBackend 来注册程序的)
4. Spark 程序运行的时候要通过 ClusterManager 获得具体的计算资源,计算资源的获取也是通过 SparkContext 产生的对象来申请的(其实是 SchedulerBackend 来获取计算资源的)。
5. SparkContext 崩溃或者结束的是候整个 Spark 程序也结束了。
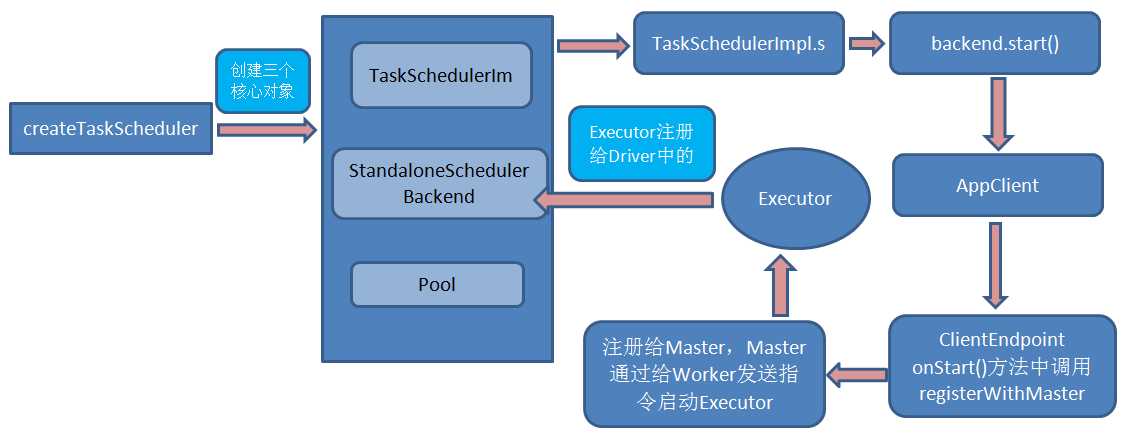
6. SparkContext 构建的项级三大核心对象:DAGScheduler 、TaskScheduler、SchedulerBackend。其中:
a) DAGScheduler 是面向 Job 的 Stage 的高层调度器
b) TaskScheduler 是一个接口,根据具体地 Cluster Manager 的不同会有不同的实现,Standalone 模式下具体的实现是 TaskSchedulerImpl ;
c) SchedulerBacken 是一个接口;根据具体的 Cluster Manager 的不同会有不同的实现,Standalone 模式下具体的实现是 SparkDeploySchedulerBackend (它是被TaskSchedulerImpl 管理的); 其核心功能是:
(1)负责与 Master 链接注册当前程序;
(2)接收集群中为当前应用程序而分配的计算资源 Executor 的注册并管理 Executors;
(3)负责发送 Task 到具体的 Executor 执行。
从整个程序运行的角度来讲,SparkContext 包含四大核心对象:DAGScheduler 、TaskScheduler、SchedulerBackend、MapOutputTrackerMaster
大体的流程: