测试小结:
1.如果只需要对数据集进行过滤,筛选则只需要编写Mapper类,不需要Reduce类,此时要执行下面一条语句:job.setNumReduceTesk(0);
2.如果需要对处理的数据进行分组(group by)、排序(order by)、表连接(join)、排重(distinct)等操作则需要编写Reducer类,因为这些操作都是基于MapTask的输出键(Key)来完成的;
3.如果既有分组又有排序只能使用两个MapReduce作业来串接完成,因为分组和排序会涉及到两次Shuffle过程;
分组与排序的本质何在?
分组是基于排序来完成,也就是说在分组之前其实上已经经过排序,从MapTask到ReduceTask的Shuffle的过程所使用的默认排序是升序,排序就是比较值的大小。
数字类型:直接根据数值大小进行比较;
字符串类型:根据字典序列(ASCII码值大小)进行比较;
Combiner产生原因:
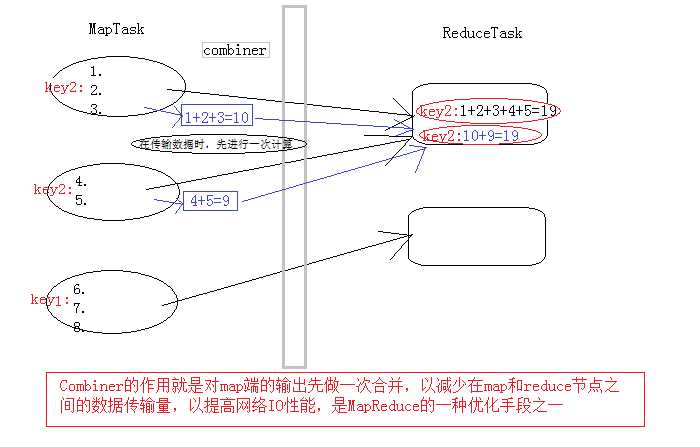
每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段之一。Combiner是继承自Reducer类。
Combiner组件:
1.是在每个 map task 的本地运行,能收到map输出的每一个key的valuelist,所以可以做局部汇总处理
2.因为map task 的本地进行了局部汇总,就会让map端的输出数据大幅精简,减少shuffle过程的网络IO
3.Combiner其实就是一个reduce组件,与reduce的区别在于:Combiner运行maptask的本地
4.Combiner在使用时需要注意,输入输出KV数据类型要跟map和reduce的相应数据类型匹配
5.要注意业务逻辑不能因为Combiner的加入而受影响。
那么在程序中的使用是:
可以直接在Runner类中main方法中:
在指定reduce类后,指定Combiner类即可:语句 wcjob.setCombinerClass(WordCountReducer.class);
因为Combiner实际就是reduce组件,所以可以使用之前指定的reduce即可。
Job wcjob = Job.getInstance(conf); 所以wcjob是job的实现类。
使用场景:即第五条中所述的情况;
不能使用场景:在求取平均数时,因为添加的Combiner组件是与reduce组件具有相同的逻辑,会提前求一次平均值后传给reduce类,导致求取的平均值错误。
使用卡宾类需要注意问题:
1.combiner类与普通的Reducer类都一样,继承于Reducer类;
2.combiner类的统计算法对于ReduceTask而言必须具有可拆解性,否则不能使用combiner;
3.如果你的conbiner类的算法与Reduce的算法完全一致,则可直接编写的Reducer类作为combiner;
Hadoop中的分布缓存:基于磁盘IO进行迭代,消耗较大,但是磁盘存储数据的性价比更高;
Spark是基于内存进行迭代的,对于实时处理数据和处理稍微小点的数据更具有优势;
当内存的容量能够达到很高并且购买内存花费也不高,即性价比和磁盘差距不大时,那么hadoop就将会面临被淘汰的危机。