交叉熵损失:
给定两个概率分布p和q,通过q来表示p的交叉熵为: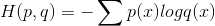
从上述公式可以看出交叉熵函数是不对称的,即H(p,q)不等于H(q,p)。
交叉熵刻画的是两个概率分布之间的距离,它表示通过概率分布q来表示概率分布p的困难程度。所以使用交叉熵作为
神经网络的损失函数时,p代表的是正确答案,q代表的是预测值。当两个概率分布越接近时,它们的交叉熵也就越小。
由于神经网络的输出并不是一个概率分布,所以需要先使用softmax将网络输出变成一个概率分布,再计算交叉熵。
比如,原始的神经网络输出为y1,y2,……,yn,那么经过softmax处理后的输出为:
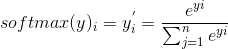
小例子:
以一个三分类为例,比如某个样本正确答案为(1,0,0)。某模型经过softmax回归后的预测答案为(0.5,0.4,0.1),则这个预测值和正确答案之间的交叉熵为:
H((1,0,0),(0.5,0.4,0.1))=-(1*log0.5+0*log0.4+0*log0.1))=0.3
假设另外一个模型的预测值是(0.8,0.1,0.1),则该预测值和真实值之间的交叉熵为:
H((1,0,0),(0.8,0.1,0.1))=-(1*log0.8+0*log0.1+0*log0.1)=0.1
从上述结果可以看出第二个预测答案要由于第一个。
tensorflow中实现交叉熵,如下所示:
cross_entropy=-tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0)))
其中y_代表正确结果,y代表预测结果。tf.clip_by_value函数可以将一个张量中的数值限制在一个范围内,这样可以避免
一些运算错误(比如log0是无效的)。下面讲解使用tf.clip_by_value函数的简单样例。
v=tf.constant([[1.0,2.0,3.0],[4.0,5.0,6.0]]) with tf.Session() as sess: print(tf.clip_by_value(v,2.5,4.5).eval())
‘‘‘
输出为
[[ 2.5 2.5 3. ]
[ 4. 4.5 4.5]]
‘‘‘
# tensorflow中提供的直接计算交叉熵损失的函数,y代表神经网络的输出结果,y_表示真实类别
cross_entropy=tf.nn.softmax_cross_entropy_with_logits(logits=y,y_)
均方误差(MSE,mean squared error):
常用于回归问题中。它的具体定义如下:
$MES(y,y^{‘})=\frac{\sum _{i=1}^{n}(y_{i}-y_{i}^{‘})^{2}}{n}$
其中,yi表示一个batch中第i个样本的真实类别,yi‘为神经网络输出的预测值。tensorflow代码实现如下:
mse=tf.reduce_mean(tf.square(y_-y))
自定义损失函数:
tensorlfow支持自定义损失函数,以下演示一个简单的示例:
首先定义一个分段损失函数,然后提供它的代码实现:
$Loss(y,y^{‘})=\sum_{i=1}^{n}f(y_{i},y_{i}^{‘}), f(x,y)=\left\{\begin{matrix}a(x-y)
& x>y \\
b(y-x) & x\leqslant y
\end{matrix}\right. $
loss=tf.recue_sum(tf.where(tf.greater(v1,v2),(v1-v2)*a,(v2-v1)*b))
tf.where和tf.greater函数用法如下:
# tf.where和tf.greater函数的用法 v1=tf.constant([1.0,2.0,3.0,4.0]) v2=tf.constant([4.0,3.0,2.0,1.0]) with tf.Session() as sess: print(tf.greater(v1,v2).eval()) # 输出 [False False True True] print(.where(tf.greater(v1,v2),v1,v2).eval()) # 输出 [ 4. 3. 3. 4.]
使用自定义损失函数实现一个简单的神经网络
该网络只有两个输入节点和一个输出节点,相当于实现了一个回归。
import tensorflow as tf from numpy.random import RandomState batch_size=8 # 定义两个输入节点 x=tf.placeholder(tf.float32,shape=(None,2),name=‘x-input‘) # 回归问题一般只有一个输出节点 y_=tf.placeholder(tf.float32,shape=(None,1),name=‘y-input‘) # 定义一个单层的神经网络 w1=tf.Variable(tf.random_normal([2,1],stddev=1,seed=1)) y=tf.matmul(x,w1) # 使用上述自己定义的损失函数 a=1;b=10 loss=tf.reduce_sum(tf.where(tf.greater(y,y_),(y-y_)*a,(y_-y)*b)) train_step=tf.train.AdamOptimizer(0.001).minimize(loss) # 随机生成一个模拟数据集 rdm=RandomState(1) dataset_size=128 X=rdm.rand(dataset_size,2) # 设置随机噪声,范围在-0.05~0.05 Y = [[x1+x2+rdm.rand()/10.0-0.05] for (x1,x2) in X] # 训练神经网路 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) STEPS=5000 for i in range(STEPS): start=(i*batch_size) % dataset_size end = min(start+batch_size,dataset_size) sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]}) print(sess.run(w1))