参考:
作者:milter
链接:https://www.zhihu.com/question/35866596/answer/139485548
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题主说要用简单易懂的例子来说明,那我就来强答一发。 理解条件随机场最好的办法就是用一个现实的例子来说明它。但是目前中文的条件随机场文章鲜有这样干的,可能写文章的人都是大牛,不屑于举例子吧。于是乎,这件事只能由我这样的机器学习小白来干了。希望对其他的小白同学有所帮助。最近在刷李航的《统计学习方法》,翻阅目录,发现就后三章内容没有接触过,分别是EM算法、隐马尔可夫模型和条件随机场,其他内容在林轩田的两门公开课里都学过。以我的尿性,必须是先攻克后三章!EM算法和隐马尔可夫模型不费太大劲就理解了,在我乘胜前进,准备一举拿下条件随机场时,我懵逼了!这本书讲解得TTMD精炼了,上来就是卡卡卡的公式,背景、例子等人民群众喜闻乐见的东西一个没有!这对没有相关知识背景的我来说,简直就是灭绝人性!后来,在全球最大的同性互动交友平台上,找到了一篇文章,虽然也是英文,但是相比100多页的文章,算是很短的了,关键是,这篇文章就是用一个活生生的例子来说明条件随机场的,十分的通俗易懂!甚合我意!看完之后,再去看李航的书,顿时感觉神清气爽!于是,我果断决定翻译这篇文章。原文在这里[Introduction to Conditional Random Fields]想直接看英文的朋友可以直接点进去了。我在翻译时并没有拘泥于原文,许多地方都加入了自己的理解,用学术点的话说就是意译。(画外音:装什么装,快点开始吧。)好的,下面开始翻译!假设你有许多小明同学一天内不同时段的照片,从小明提裤子起床到脱裤子睡觉各个时间段都有(小明是照片控!)。现在的任务是对这些照片进行分类。比如有的照片是吃饭,那就给它打上吃饭的标签;有的照片是跑步时拍的,那就打上跑步的标签;有的照片是开会时拍的,那就打上开会的标签。问题来了,你准备怎么干?一个简单直观的办法就是,不管这些照片之间的时间顺序,想办法训练出一个多元分类器。就是用一些打好标签的照片作为训练数据,训练出一个模型,直接根据照片的特征来分类。例如,如果照片是早上6:00拍的,且画面是黑暗的,那就给它打上睡觉的标签;如果照片上有车,那就给它打上开车的标签。这样可行吗?乍一看可以!但实际上,由于我们忽略了这些照片之间的时间顺序这一重要信息,我们的分类器会有缺陷的。举个例子,假如有一张小明闭着嘴的照片,怎么分类?显然难以直接判断,需要参考闭嘴之前的照片,如果之前的照片显示小明在吃饭,那这个闭嘴的照片很可能是小明在咀嚼食物准备下咽,可以给它打上吃饭的标签;如果之前的照片显示小明在唱歌,那这个闭嘴的照片很可能是小明唱歌瞬间的抓拍,可以给它打上唱歌的标签。所以,为了让我们的分类器能够有更好的表现,在为一张照片分类时,我们必须将与它相邻的照片的标签信息考虑进来。这——就是条件随机场(CRF)大显身手的地方!#从例子说起——词性标注问题-----啥是词性标注问题?非常简单的,就是给一个句子中的每个单词注明词性。比如这句话:“Bob drank coffee at Starbucks”,注明每个单词的词性后是这样的:“Bob (名词) drank(动词) coffee(名词) at(介词) Starbucks(名词)”。下面,就用条件随机场来解决这个问题。以上面的话为例,有5个单词,我们将:(名词,动词,名词,介词,名词)作为一个标注序列,称为l,可选的标注序列有很多种,比如l还可以是这样:(名词,动词,动词,介词,名词),我们要在这么多的可选标注序列中,挑选出一个最靠谱的作为我们对这句话的标注。怎么判断一个标注序列靠谱不靠谱呢?就我们上面展示的两个标注序列来说,第二个显然不如第一个靠谱,因为它把第二、第三个单词都标注成了动词,动词后面接动词,这在一个句子中通常是说不通的。假如我们给每一个标注序列打分,打分越高代表这个标注序列越靠谱,我们至少可以说,凡是标注中出现了动词后面还是动词的标注序列,要给它减分!!上面所说的动词后面还是动词就是一个特征函数,我们可以定义一个特征函数集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。也就是说,每一个特征函数都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。#定义CRF中的特征函数现在,我们正式地定义一下什么是CRF中的特征函数,所谓特征函数,就是这样的函数,它接受四个参数:- 句子s(就是我们要标注词性的句子)- i,用来表示句子s中第i个单词- l_i,表示要评分的标注序列给第i个单词标注的词性- l_i-1,表示要评分的标注序列给第i-1个单词标注的词性它的输出值是0或者1,0表示要评分的标注序列不符合这个特征,1表示要评分的标注序列符合这个特征。Note:这里,我们的特征函数仅仅依靠当前单词的标签和它前面的单词的标签对标注序列进行评判,这样建立的CRF也叫作线性链CRF,这是CRF中的一种简单情况。为简单起见,本文中我们仅考虑线性链CRF。#从特征函数到概率定义好一组特征函数后,我们要给每个特征函数f_j赋予一个权重λ_j。现在,只要有一个句子s,有一个标注序列l,我们就可以利用前面定义的特征函数集来对l评分。<img src="https://pic3.zhimg.com/50/v2-d5c036cdff0f8ab53bac9f60d126daee_hd.png" data-rawwidth="498" data-rawheight="68" class="origin_image zh-lightbox-thumb" width="498" data-original="https://pic3.zhimg.com/v2-d5c036cdff0f8ab53bac9f60d126daee_r.png">上式中有两个相加,外面的相加用来相加每一个特征函数f_j,里面的相加用来相加句子中每个位置的单词的的特征值。对这个分数进行指数化和标准化,我们就可以得到标注序列l的概率值p(l|s),如下所示:<img src="https://pic4.zhimg.com/50/v2-f309245728fef919a9843bd44c48267f_hd.png" data-rawwidth="637" data-rawheight="96" class="origin_image zh-lightbox-thumb" width="637" data-original="https://pic4.zhimg.com/v2-f309245728fef919a9843bd44c48267f_r.png">#几个特征函数的例子前面我们已经举过特征函数的例子,下面我们再看几个具体的例子,帮助增强大家的感性认识。<img src="https://pic3.zhimg.com/50/v2-1e2e20e990e4572907e6f87c88b40502_hd.png" data-rawwidth="212" data-rawheight="39" class="content_image" width="212">当l_i是“副词”并且第i个单词以“ly”结尾时,我们就让f1 = 1,其他情况f1为0。不难想到,f1特征函数的权重λ1应当是正的。而且λ1越大,表示我们越倾向于采用那些把以“ly”结尾的单词标注为“副词”的标注序列<img src="https://pic2.zhimg.com/50/v2-26349606327a44f4c432e604e168060d_hd.png" data-rawwidth="205" data-rawheight="42" class="content_image" width="205">如果i=1,l_i=动词,并且句子s是以“?”结尾时,f2=1,其他情况f2=0。同样,λ2应当是正的,并且λ2越大,表示我们越倾向于采用那些把问句的第一个单词标注为“动词”的标注序列。<img src="https://pic4.zhimg.com/50/v2-a75ed483ffdea2a543d8f44ff2031e13_hd.png" data-rawwidth="204" data-rawheight="34" class="content_image" width="204">当l_i-1是介词,l_i是名词时,f3 = 1,其他情况f3=0。λ3也应当是正的,并且λ3越大,说明我们越认为介词后面应当跟一个名词。<img src="https://pic1.zhimg.com/50/v2-7ad542bab7f9622e00003c4366639004_hd.png" data-rawwidth="207" data-rawheight="37" class="content_image" width="207">如果l_i和l_i-1都是介词,那么f4等于1,其他情况f4=0。这里,我们应当可以想到λ4是负的,并且λ4的绝对值越大,表示我们越不认可介词后面还是介词的标注序列。好了,一个条件随机场就这样建立起来了,让我们总结一下:为了建一个条件随机场,我们首先要定义一个特征函数集,每个特征函数都以整个句子s,当前位置i,位置i和i-1的标签为输入。然后为每一个特征函数赋予一个权重,然后针对每一个标注序列l,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值。
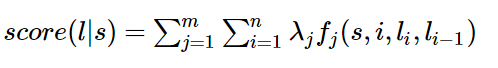{kind=link}
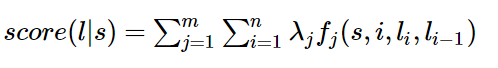{kind=link}
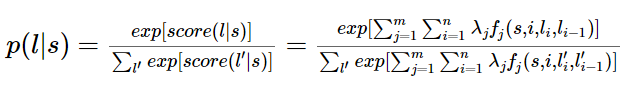{kind=link}
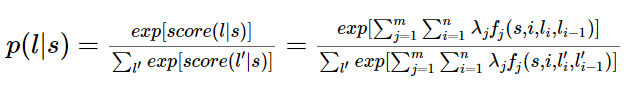{kind=link}
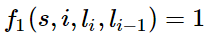{kind=link}
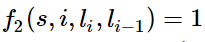{kind=link}
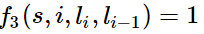{kind=link}
{kind=link}