标签:style blog http color io os 使用 ar strong
hmater负责把region均匀到各个region server 。hmaster中有一个线程任务是专门处理负责均衡的,默认每隔5分钟执行一次。
每次负载均衡操作可以分为两步:
负载均衡方法入口
以下代码的Hbase版本为0.96.2
在org.apache.hadoop.hbase.master.balancer.BalancerChore中
public BalancerChore(HMaster master) { super(master.getServerName() + "-BalancerChore", master.getConfiguration().getInt("hbase.balancer.period", 300000), master);//hbase.balancer.period 为负载均衡方法执行的周期,毫秒为单位,hbaser-site.xml中可以设置 this.master = master; } @Override protected void chore() { try { master.balance();//执行负载均衡方法 } catch (IOException e) { LOG.error("Failed to balance.", e); } } //执行负载均衡的入口。 public void run() { try { boolean initialChoreComplete = false; while (!this.stopper.isStopped()) {//stopper是Hmaster service,这里判断Hmaster是否是正常状态。 long startTime = System.currentTimeMillis(); try { if (!initialChoreComplete) { initialChoreComplete = initialChore();//在循环开始前,执行初始化方法,这里默认返回true; } else { chore();//执行负载均衡方法 } } catch (Exception e) { if (this.stopper.isStopped()) { continue; } } this.sleeper.sleep(startTime); } ... }
负载均衡代码:
org.apache.hadoop.hbase.master.HMaster public boolean balance() throws IOException { // 如果master没有被初始化,则不执行初始化操作 if (!this.initialized) { LOG.debug("Master has not been initialized, don‘t run balancer."); return false; } //只能同时跑一个负载均衡方法 if (!this.loadBalancerTracker.isBalancerOn()) return false; // Do this call outside of synchronized block. int maximumBalanceTime = getBalancerCutoffTime(); synchronized (this.balancer) { //如果有region处于splitting状态,则不跑负载均衡方法。 if (this.assignmentManager.getRegionStates().isRegionsInTransition()) { Map<String, RegionState> regionsInTransition = this.assignmentManager.getRegionStates().getRegionsInTransition(); ... return false; } if (this.serverManager.areDeadServersInProgress()) {//如果有挂掉的region server则不执行负载均衡。 LOG.debug("Not running balancer because processing dead regionserver(s): " + this.serverManager.getDeadServers()); return false; } ... Map<TableName, Map<ServerName, List<HRegionInfo>>> assignmentsByTable = this.assignmentManager.getRegionStates().getAssignmentsByTable();//获取table下面的region server 和region。 List<RegionPlan> plans = new ArrayList<RegionPlan>(); //Give the balancer the current cluster state. this.balancer.setClusterStatus(getClusterStatus());//设置当前集群的状态 for (Map<ServerName, List<HRegionInfo>> assignments : assignmentsByTable.values()) {//可以看到,负载均衡方法是以每个table作为负载均衡的依据的。 List<RegionPlan> partialPlans = this.balancer.balanceCluster(assignments);//获取负载均衡计划表 if (partialPlans != null) plans.addAll(partialPlans); } ... if (plans != null && !plans.isEmpty()) { for (RegionPlan plan: plans) { ... this.assignmentManager.balance(plan);//根据执行计划表的迁移内容。 ... } } } // If LoadBalancer did not generate any plans, it means the cluster is already balanced. // Return true indicating a success. return true; }
从代码可以看到负载均衡是根据每个table来的
在以下几种状态下,负载平衡方法不会执行:
生成RegionPlan表:
org.apache.hadoop.hbase.master.balancer.StochasticLoadBalancer
生成regionPlan表用的StochasticLoadBalancer. balanceCluster(Map<ServerName, List<HRegionInfo>> clusterState)这个方法,这个方法比较特别也比较有意思,首先,StochasticLoadBalancer 有一套计算某一table下cluster load(集群负载)评分的算法,得出的值越低表明负载越合理。这套算法是根据以下几个维度来计算得出的:
首先对单个region server 根据上面5个维度计算得出评分x(0<=x<=1),然后把同一table下所有region server评分加起来,就是当前table的cluster load评分。这个评分越低表明越合理。
然后它还有三种调节cluster load 的方法:
RandomRegionPicker 随机交换策略。在虚拟cluster中(虚拟cluster只作为记录用,不会涉及实际的region 迁移操作。cluster包含某个table下所有的region server的相关信息,以及region server下的regions.)随机选出两个region server ,然后分别在region server 中在 随机获取一个region,然后这两个region server下的region交换一下,然后再计算评分,如果得出的评分较低的话,表明这两个region 交换是有利于集群的负载均衡的,保留这个改变。否则,还原到之前的状态,两个region再交换下region server 。其中拥有比较少regions的region server 可能随机出一个空,实际情况,就是变成了迁移region,不再是交换region。
LoadPicker ,region数目均衡策略。在虚拟cluster中,首先获取region数目最多和最少的两个region server ,这样能使两个region server 最终的region数目更加的平均。后面的流程和上面的一样。
LocalityPicker ,本地性最强的均衡策略。本地性的意思是,Hbase底层的数据其实是存放在HDFS上面的,如果某个region的数据文件存放在某个region server 的比例比其他的region server 都要高,那么称这个region server是该region的最高本地性region server 。在该策略中,首先随机出一个region server 以及其下面的region 。然后找到这个region本地性最高的region server 。本地性最高的region server再随机出一个region server。这两个region server 后面的流程和上面的一样。
具体流程如下:
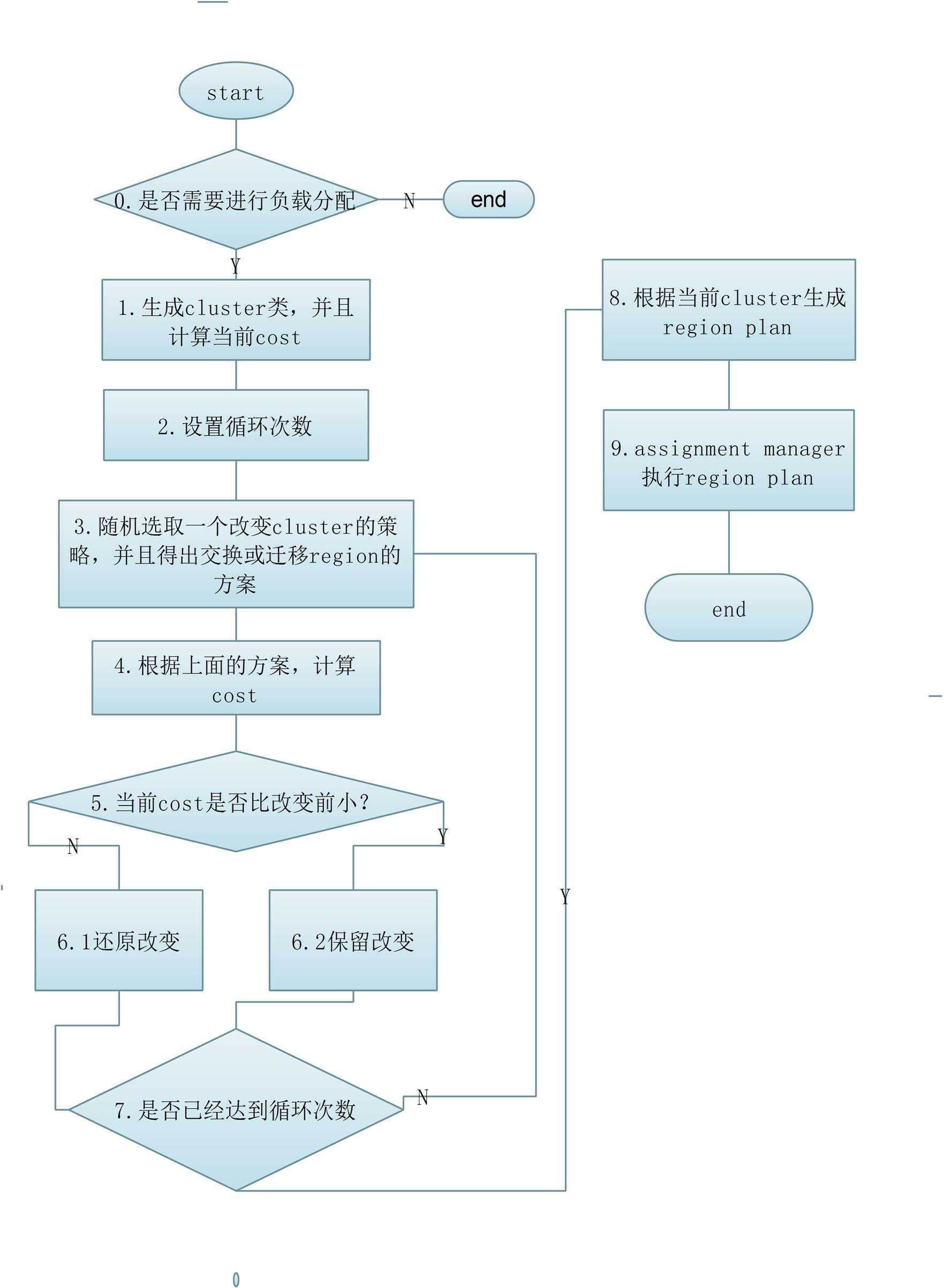
0. 是否需要进行负载均衡,是根据当前region server拥有的region数目来判断的
protected boolean needsBalance(ClusterLoadState cs) { ... float average = cs.getLoadAverage(); // for logging 获取cluster中region server平均拥有的region数目 int floor = (int) Math.floor(average * (1 - slop));//slop默认是0.2,可接受范围的最低值 int ceiling = (int) Math.ceil(average * (1 + slop));//最高值 if (!(cs.getMaxLoad() > ceiling || cs.getMinLoad() < floor)) {//如果cluster的最多和最少region的region server不在范围内,返回false表明需要进行负载均衡算法。 ... return false; } return true; }
1.计算当前cluster的分数。简单来说是这样的,在每一个维度中,计算region server 的cost值,最终根据 (权重*cost值) 加起来的就是总得分,这得分越小表示越均衡,每个region server之间的差异越小。这个cost值是由cluster的(最大差值/(当前差值-最小差值))得出的。
/* 计算cluster的总得分*/ protected double computeCost(Cluster cluster, double previousCost) { double total = 0;for (CostFunction c:costFunctions) {//CostFunction 根据某个维度计算分数 ,costFunctions的实现见下面代码。 if (c.getMultiplier() <= 0) {//multiplier是权重。 continue; } total += c.getMultiplier() * c.cost(cluster);//权重*当前维度的评分 if (total > previousCost) { return total; } } return total; } //costFunctions 初始化 regionLoadFunctions = new CostFromRegionLoadFunction[] { new ReadRequestCostFunction(conf),//读请求维度评分 new WriteRequestCostFunction(conf),//写请求维度评分 new MemstoreSizeCostFunction(conf),//memstore 大小维度评分 new StoreFileCostFunction(conf)//StoreFile 维度评分 }; costFunctions = new CostFunction[]{ new RegionCountSkewCostFunction(conf),//region 数目 维度评分 new MoveCostFunction(conf),//迁移region 维度评分 localityCost,//本地相关 维度评分 new TableSkewCostFunction(conf), //表 维度评分 regionLoadFunctions[0], regionLoadFunctions[1], regionLoadFunctions[2], regionLoadFunctions[3], };
取其中RegionCountSkewCostFunction 作为例子:
public static class RegionCountSkewCostFunction extends CostFunction { private static final String REGION_COUNT_SKEW_COST_KEY = "hbase.master.balancer.stochastic.regionCountCost"; private static final float DEFAULT_REGION_COUNT_SKEW_COST = 500;//默认权重为500 private double[] stats = null; RegionCountSkewCostFunction(Configuration conf) { super(conf); // Load multiplier should be the greatest as it is the most general way to balance data. this.setMultiplier(conf.getFloat(REGION_COUNT_SKEW_COST_KEY, DEFAULT_REGION_COUNT_SKEW_COST));//设置权重 }
@Override double cost(Cluster cluster) { if (stats == null || stats.length != cluster.numServers) { stats = new double[cluster.numServers]; } for (int i =0; i < cluster.numServers; i++) { stats[i] = cluster.regionsPerServer[i].length;//当前维度是根据每个region server 的region数目作为评分标准。 } return costFromArray(stats); } } protected double costFromArray(double[] stats) {//根据某一维度,每个region server计算出来的评分 double totalCost = 0; double total = getSum(stats);//计算总分 double mean = total/((double)stats.length);//获取每个region server的平均评分 double count = stats.length;//region server的总数 // Compute max as if all region servers had 0 and one had the sum of all costs. This must be // a zero sum cost for this to make sense. //这里假设最坏的情况为(count-1)的region server的评分为0,剩下的一个region server 占有了所有的分数,也就是负载非常不均衡,全部压力都压到同一台region server上面了。计算出最大的差值max。 double max = ((count - 1) * mean) + (total - mean); for (double n : stats) {//计算当前的差值 double diff = Math.abs(mean - n); totalCost += diff; } double scaled = scale(0, max, totalCost);//(最大差值/(当前差值-最小差值)) return scaled; }
2.设置循环的次数和cluster的region server 的总数和region总数有关。最大值mapSteps为1000000。
long computedMaxSteps = Math.min(this.maxSteps, ((long)cluster.numRegions * (long)this.stepsPerRegion * (long)cluster.numServers));
3,4,5,6随机出一个策略,就是上面讲到的 RandomRegionPicker,LoadPicker,LocalityPicker 交换或迁移一次region再计算评分。如果评分比之前要低保留,否则还原。
7,8,9循环进行直到结束,产出List<RegionPlan>。交给assignment manager实际执行迁移region的操作。regionPlan的格式是这样子的:
RegionPlan rp = new RegionPlan(region, initialServer, newServer); //initialServer的region需要迁移到newServer
到此,负载均衡算法结束。在Hbase 0.94的版本里面,默认的负载均衡算法是使用SimpleLoadBalancer类,balanceCluster主要思路上,平均每个region server的region数目,维度相对来说比较单一,在StochasticLoadBalancer 中考虑的维度比较多,在0.96版本里面StochasticLoadBalancer作为了默认的负载均衡的算法的实现。https://issues.apache.org/jira/browse/HBASE-5959 这个patch的评论能看到StochasticLoadBalancer的提交的过程。
标签:style blog http color io os 使用 ar strong
原文地址:http://www.cnblogs.com/niurougan/p/3975433.html