要点: 代码针对于 spark 1.6.1源码
1, TaskScheduler如何注册application, executor如何反注册
2, DAGScheduler
3, spark UI
一、SparkConf概述
SparkContext需要传入SparkConf来进行初始化,SparkConf用于维护Spark的配置属性。
org.apache.spark.SpaarkConf
/**
* SparkConf内部使用ConcurrentHashMap来维护所有的配置。
* 由于SparkConf提供的setter方法返回的是this,也就是一个SparkConf对象,
* 因此它允许使用链式的方式来设置属性。
* @param loadDefaults
*/
class SparkConf(loadDefaults: Boolean) extends Cloneable with Logging {
import SparkConf._
/** Create a SparkConf that loads defaults from system properties and the classpath */
// 加载默认的配置属性
def this() = this(true)
private val settings = new ConcurrentHashMap[String, String]()
if (loadDefaults) {
// Load any spark.* system properties
for ((key, value) <- Utils.getSystemProperties if key.startsWith("spark.")) {
set(key, value)
}
}
/** Set a configuration variable. */
def set(key: String, value: String): SparkConf = {
if (key == null) {
throw new NullPointerException("null key")
}
if (value == null) {
throw new NullPointerException("null value for " + key)
}
logDeprecationWarning(key)
settings.put(key, value)
this
}
/**
* The master URL to connect to, such as "local" to run locally with one thread, "local[4]" to
* run locally with 4 cores, or "spark://master:7077" to run on a Spark standalone cluster.
*/
def setMaster(master: String): SparkConf = {
set("spark.master", master)
}
/** Set a name for your application. Shown in the Spark web UI. */
def setAppName(name: String): SparkConf = {
set("spark.app.name", name)
}
二、SparkContext的初始化
SparkContext的初始化步骤主要包含以下几步:
1)创建JobProgressListener
2)创建SparkEnv
3)创建TaskScheduler DAGScheduler
1. 复制SparkConf配置信息,然后校验或者添加新的配置信息
SparkContext的主构造器参数为SparkConf:
class SparkContext(config: SparkConf) extends Logging with ExecutorAllocationClient {
// getCallSite方法会得到一个CallSite对象,
// 该对象存储了线程栈中最靠近栈顶的用户类及最靠近栈底的Scala或者Spark核心类信息。
// SparkContext默认只有一个实例,由属性"spark.driver.allowMultipleContexts"来控制。
// markPartiallyConstructed方法用于确保实例的唯一性,并将当前SparkContext标记为正在构建中。
private val creationSite: CallSite = Utils.getCallSite()
// If true, log warnings instead of throwing exceptions when multiple SparkContexts are active
private val allowMultipleContexts: Boolean =
config.getBoolean("spark.driver.allowMultipleContexts", false)
.............
}
// 之后会初始化一些其他实例对象,
// 比如会在内部创建一个SparkConf类型的对象_conf,然后在将传过来的config进行复制,然后会对配置信息进行校验。
private var _conf: SparkConf = _
......
try {
_conf = config.clone()
_conf.validateSettings()
if (!_conf.contains("spark.master")) {
throw new SparkException("A master URL must be set in your configuration")
}
if (!_conf.contains("spark.app.name")) {
throw new SparkException("An application name must be set in your configuration")
}
从上面代码可以看出,必须要指定spark.master(运行模式)和spark.app.name(应用程序名称),否则会抛出异常。
2. 创建SparkEnv
SparkEnv包含了Spark实例(master or worker)运行时的环境对象,包括serializer, Akka actor system, block manager, map output tracker等等。
SparkContext中创建SparkEnv实例的部分代码:
private[spark] def createSparkEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus): SparkEnv = {
SparkEnv.createDriverEnv(conf, isLocal, listenerBus, SparkContext.numDriverCores(master))
}
...
//“_jobprogresslistener”应生成在创建sparkenv之前.
// 因为当创建“sparkenv”的时候,一些信息需要放到“listenerbus” 中。
_jobProgressListener = new JobProgressListener(_conf)
listenerBus.addListener(jobProgressListener)
......
// Create the Spark execution environment (cache, map output tracker, etc)
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
也就是说最后会调用SparkEnv.createDriverEnv方法.
/**
* Create a SparkEnv for an executor.
* In coarse-grained mode, the executor provides an actor system that is already instantiated.
*/
private[spark] def createExecutorEnv(
conf: SparkConf,
executorId: String,
hostname: String,
port: Int,
numCores: Int,
isLocal: Boolean): SparkEnv = {
val env = create(
conf,
executorId,
hostname,
port,
isDriver = false,
isLocal = isLocal,
numUsableCores = numCores
)
SparkEnv.set(env)
env
}
.......
private def create(
conf: SparkConf,
executorId: String,
hostname: String,
port: Int,
isDriver: Boolean,
isLocal: Boolean,
numUsableCores: Int,
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
................
}
......
val envInstance = new SparkEnv(
executorId,
rpcEnv,
actorSystem, // 基于Akka的分布式消息系统
serializer,
closureSerializer,
cacheManager, // 缓存管理器
mapOutputTracker, // map任务输出跟踪器
shuffleManager, // shuffle管理器
broadcastManager, // 广播管理器
blockTransferService, // 块传输服务
blockManager, // 块管理器
securityManager, // 安全管理器
sparkFilesDir,
metricsSystem, // 测量系统
memoryManager, // 内存管理器
outputCommitCoordinator,
conf)
SparkEnv的createDriverEnv方法会调用私有create方法来创建serializer,closureSerializer,cacheManager等,创建完成后会创建SparkEnv对象。
3. 创建MetadataCleaner
MetadataCleaner是用来定时的清理metadata的,metadata有6种类型,封装在了MetadataCleanerType类中。
4. 创建SparkStatusTracker
SparkStatusTracker是低级别的状态报告API,用于监控job和stage。
5. 初始化Spark UI
SparkUI为Spark监控Web平台提供了Spark环境、任务的整个生命周期的监控。
6. HadoopConfiguration
由于Spark默认使用HDFS作为分布式文件系统,所以需要获取Hadoop相关的配置信息。
主要做了:
1)将Amazon S3文件系统的AccessKeyId和SecretAccessKey加载到Hadoop的Configuration。
2)将SparkConf中所有以spark.hadoop.开头的属性复制到Hadoop的Configuration。
3)将SparkConf的spark.buffer.size属性复制为Hadoop的Configuration的io.file.buffer.size属性。
7. ExecutorEnvs
ExecutorEnvs包含的环境变量会在注册应用时发送给Master,Master给Worker发送调度后,Worker最终使用executorEnvs提供的信息启动Executor。
// ExecutorEnvs包含的环境变量会在注册应用时发送给Master,
// Master给Worker发送调度后,Worker最终使用executorEnvs提供的信息启动Executor。
for { (envKey, propKey) <- Seq(("SPARK_TESTING", "spark.testing"))
value <- Option(System.getenv(envKey)).orElse(Option(System.getProperty(propKey)))} {
executorEnvs(envKey) = value
}
Option(System.getenv("SPARK_PREPEND_CLASSES")).foreach { v =>
executorEnvs("SPARK_PREPEND_CLASSES") = v
}
// The Mesos scheduler backend relies on this environment variable to set executor memory.
// TODO: Set this only in the Mesos scheduler.
executorEnvs("SPARK_EXECUTOR_MEMORY") = executorMemory + "m"
executorEnvs ++= _conf.getExecutorEnv
executorEnvs("SPARK_USER") = sparkUser
}
由上面代码克制,可以通过配置spark.executor.memory指定Executor占用内存的大小,也可以配置系统变量SPARK_EXECUTOR_MEMORY或SPARK_MEM对其大小进行设置。
8. 注册HeartbeatReceiver
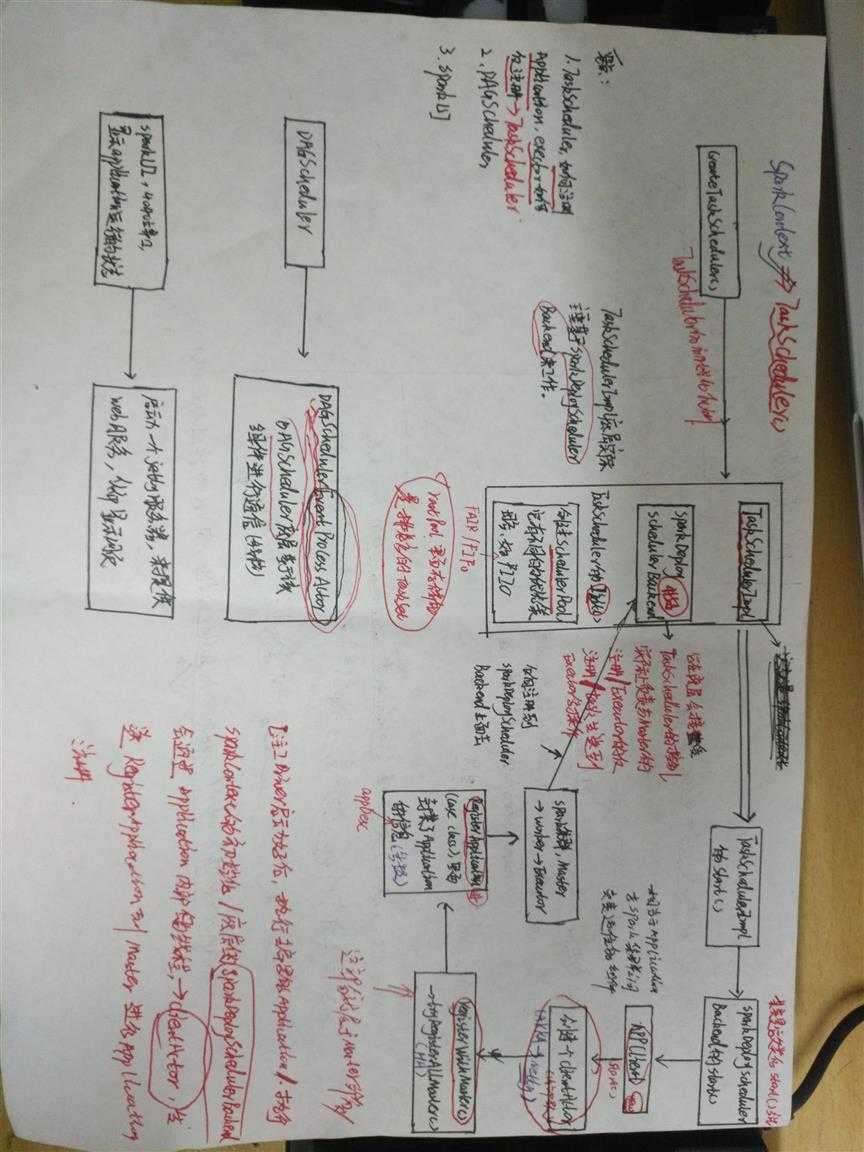
9. 创建TaskScheduler
TaskScheduler为Spark的任务调度器,Spark通过它提交任务并且请求集群调度任务;TaskScheduler通过master的配置匹配部署模式,创建TashSchedulerImpl,根据不同的集群管理模式(local、local[n]、local[n,m]、standalone、local-cluster、mesos、YARN)创建不同的SchedulerBackend。
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler‘s
// constructor
_taskScheduler.start()
_applicationId = _taskScheduler.applicationId()
_applicationAttemptId = taskScheduler.applicationAttemptId()
_conf.set("spark.app.id", _applicationId)
_ui.foreach(_.setAppId(_applicationId))
_env.blockManager.initialize(_applicationId)
createTaskScheduler方法会使用模式匹配来创建不同的TaskSchedulerImpl和Backend。
/**
* 针对不同的提交模式来匹配TaskScheduler采用的方式和资源调度采用的方式
*/
private def createTaskScheduler(
sc: SparkContext,
master: String): (SchedulerBackend, TaskScheduler) = {
// 这里直接导入了包,来看查看匹配的集群的模式
import SparkMasterRegex._
// 当运行是本地模式的时候,默认是情况下task失败以后不重试
val MAX_LOCAL_TASK_FAILURES = 1
master match {
case "local" =>
// 本地单线程模式,其中taskschedule采用了TaskSchedulerImpl 资源调度采用了LocalBackend
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalBackend(sc.getConf, scheduler, 1)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_REGEX(threads) =>
// 本地多线程模式,匹配Local[N][N个线程]和Local[*][机器上面的所有线程],
// 其中taskschedule采用了TaskSchedulerImpl 资源调度采用了LocalBackend
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
val threadCount = if (threads == "*") localCpuCount else threads.toInt
if (threadCount <= 0) {
throw new SparkException(s"Asked to run locally with $threadCount threads")
}
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_FAILURES_REGEX(threads, maxFailures) =>
// 匹配本地模式 Local[N,M]和Local[*,M] M表示task失败以后重试的次数,
// 其中taskschedule采用了TaskSchedulerImpl 资源调度采用了LocalBackend
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
val threadCount = if (threads == "*") localCpuCount else threads.toInt
val scheduler = new TaskSchedulerImpl(sc, maxFailures.toInt, isLocal = true)
val backend = new LocalBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case SPARK_REGEX(sparkUrl) =>
// 匹配spark standalone模式,
// 其中taskschedule采用了TaskSchedulerImpl 资源调度采用了SparkDeploySchedulerBackend
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_CLUSTER_REGEX(numSlaves, coresPerSlave, memoryPerSlave) =>
// 匹配本地集群模式 Local-cluster,
// 其中taskschedule采用了TaskSchedulerImpl 资源调度采用了SparkDeploySchedulerBackend
// Check to make sure memory requested <= memoryPerSlave.
// Otherwise Spark will just hang.
val memoryPerSlaveInt = memoryPerSlave.toInt
if (sc.executorMemory > memoryPerSlaveInt) {
throw new SparkException(
"Asked to launch cluster with %d MB RAM / worker but requested %d MB/worker".format(
memoryPerSlaveInt, sc.executorMemory))
}
val scheduler = new TaskSchedulerImpl(sc)
val localCluster = new LocalSparkCluster(
numSlaves.toInt, coresPerSlave.toInt, memoryPerSlaveInt, sc.conf)
val masterUrls = localCluster.start()
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
backend.shutdownCallback = (backend: SparkDeploySchedulerBackend) => {
localCluster.stop()
}
(backend, scheduler)
// "yarn-standalone"或"yarn-cluster"运行模式,
// 其中taskschedule采用了YarnClusterScheduler 资源调度采用了YarnClusterSchedulerBackend
case "yarn-standalone" | "yarn-cluster" =>
if (master == "yarn-standalone") {
logWarning(
"\"yarn-standalone\" is deprecated as of Spark 1.0. Use \"yarn-cluster\" instead.")
}
val scheduler = try {
val clazz = Utils.classForName("org.apache.spark.scheduler.cluster.YarnClusterScheduler")
val cons = clazz.getConstructor(classOf[SparkContext])
cons.newInstance(sc).asInstanceOf[TaskSchedulerImpl]
} catch {
// TODO: Enumerate the exact reasons why it can fail
// But irrespective of it, it means we cannot proceed !
case e: Exception => {
throw new SparkException("YARN mode not available ?", e)
}
}
val backend = try {
val clazz =
Utils.classForName("org.apache.spark.scheduler.cluster.YarnClusterSchedulerBackend")
val cons = clazz.getConstructor(classOf[TaskSchedulerImpl], classOf[SparkContext])
cons.newInstance(scheduler, sc).asInstanceOf[CoarseGrainedSchedulerBackend]
} catch {
case e: Exception => {
throw new SparkException("YARN mode not available ?", e)
}
}
scheduler.initialize(backend)
(backend, scheduler)
// 匹配yarn-client模式,其中taskschedule采用了YarnScheduler,
// 其中YarnScheduler为TaskSchedulerImpl的子类, 资源调度采用了YarnClientSchedulerBackend
case "yarn-client" =>
val scheduler = try {
val clazz = Utils.classForName("org.apache.spark.scheduler.cluster.YarnScheduler")
val cons = clazz.getConstructor(classOf[SparkContext])
cons.newInstance(sc).asInstanceOf[TaskSchedulerImpl]
} catch {
case e: Exception => {
throw new SparkException("YARN mode not available ?", e)
}
}
val backend = try {
val clazz =
Utils.classForName("org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend")
val cons = clazz.getConstructor(classOf[TaskSchedulerImpl], classOf[SparkContext])
cons.newInstance(scheduler, sc).asInstanceOf[CoarseGrainedSchedulerBackend]
} catch {
case e: Exception => {
throw new SparkException("YARN mode not available ?", e)
}
}
scheduler.initialize(backend)
(backend, scheduler)
// 匹配Mesos运行模式 taskscheduler采用了TaskSchedulerImpl,
case MESOS_REGEX(mesosUrl) =>
MesosNativeLibrary.load()
val scheduler = new TaskSchedulerImpl(sc)
val coarseGrained = sc.conf.getBoolean("spark.mesos.coarse", defaultValue = true)
// 根据coarseGrained 选择粗粒度还是细粒度来选择资源调度器
val backend = if (coarseGrained) {
// 当为粗粒度的时候CoarseMesosSchedulerBackend
new CoarseMesosSchedulerBackend(scheduler, sc, mesosUrl, sc.env.securityManager)
} else {
// 当为细粒度的时候MesosSchedulerBackend
new MesosSchedulerBackend(scheduler, sc, mesosUrl)
}
scheduler.initialize(backend)
(backend, scheduler)
// 匹配spark in MapReduce V1模式,
// taskscheduler采用了TaskSchedulerImpl,资源调度采用了SimrSchedulerBackend
case SIMR_REGEX(simrUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val backend = new SimrSchedulerBackend(scheduler, sc, simrUrl)
scheduler.initialize(backend)
(backend, scheduler)
// 匹配如果是zookeeper模式,底层还是和mesos模式类似
case zkUrl if zkUrl.startsWith("zk://") =>
logWarning("Master URL for a multi-master Mesos cluster managed by ZooKeeper should be " +
"in the form mesos://zk://host:port. Current Master URL will stop working in Spark 2.0.")
createTaskScheduler(sc, "mesos://" + zkUrl)
case _ =>
throw new SparkException("Could not parse Master URL: ‘" + master + "‘")
}
}
}
/**
* 判断不同的提交模式
*/
private object SparkMasterRegex {
// 正则表达式,用于匹配local[N] 和 local[*]
val LOCAL_N_REGEX = """local\[([0-9]+|\*)\]""".r
// 正则表达式,用于匹配local[N, maxRetries], maxRetries表示失败后的最大重复次数
val LOCAL_N_FAILURES_REGEX = """local\[([0-9]+|\*)\s*,\s*([0-9]+)\]""".r
// 正则表达式,用于匹配local-cluster[N, cores, memory],它是一种伪分布式模式
val LOCAL_CLUSTER_REGEX = """local-cluster\[\s*([0-9]+)\s*,\s*([0-9]+)\s*,\s*([0-9]+)\s*]""".r
// 正则表达式用于匹配 Spark Standalone集群运行模式
val SPARK_REGEX = """spark://(.*)""".r
// 正则表达式用于匹配 Mesos集群资源管理器运行模式匹配 mesos:// 或 zk:// url
val MESOS_REGEX = """mesos://(.*)""".r
// 正则表达式和于匹配Spark in MapReduce v1,用于兼容老版本的Hadoop集群
val SIMR_REGEX = """simr://(.*)""".r
}
9.1 创建TaskSchedulerImpl
TaskSchedulerImpl构造过程如下:
1)从SparkConf中读取配置信息,包括每个任务分配的CPU数,调度策略(FAIR或FIFO,默认为FIFO)
2)创建TaskResultGetter
通过线程池对Worker上的Executor发送的Task的执行结果进行处理。默认会通过Executors.newFixedThreadPool创建一个包含4个、线程名以task-result-getter开头的线程池。
TaskSchedulerImpl的调度模式有FAIR和FIFO两种。任务的最终调度实际都是有SchedulerBackend实现的。local模式下的SchedulerBackend为LocalBackend。
9.2 TaskSchedulerImpl的初始化
以SPARK_REGEX 对应的standlone模式为例,里面创建了 TaskSchedulerImpl对象和 SparkDeploySchedulerBackend对象,并执行TaskSchedulerImpl的initialize方法,把SparkDeploySchedulerBackend对象(backend)作为参数传入TaskSchedulerImpl 中。
// 针对于SparkContext中的针对于不同的提交模式,调用的initialize()方法
// 会创建一个调度池rootPool-->调度策略
def initialize(backend: SchedulerBackend) {
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
}
}
schedulableBuilder.buildPools()
}
def newTaskId(): Long = nextTaskId.getAndIncrement()
override def start() {
// backend-->SparkDeploySchedulerBackend
// 实际上调用的是SparkDeploySchedulerPool的start()方法
backend.start()
// 是否启用推断机制
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
speculationScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}
1) 使TaskSchedulerImpl持有SparkDeploySchedulerBackend的引用
2)创建Pool,Pool中缓存了调度队列,调度算法以及TaskSetManager集合等信息。
3)创建FIFOSchedulableBuilder,FIFOSchedulableBuilder用来操作Pool中的调度队列。
9.3 进入start方法,可以看到在start()方法中执行了SparkDeploySchedulerBackend对象的start()方法
org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend-->start()
/**
* SparkDeploySchedulerBackend:
* 1 负责与Master的注册
* 2 负责Executor的反注册
* 3 负责 将task发送到Executor操作(其实是TaskSet)
*/
// TaskSchedulerImpl中start()方法其实调用的是这里的start()方法
override def start() {
// 然后它最终调用的是它的父类CoarseGrainedSchedulerBackend的start()方法
super.start()
launcherBackend.connect()
// 这个地方的CoarseGrainedSchedulerBackend是SparkDeploySchedulerBackend
// 的父类,在父类里面定义了start()方法,定义了driverEndpoint变量
val driverUrl = rpcEnv.uriOf(SparkEnv.driverActorSystemName,
RpcAddress(sc.conf.get("spark.driver.host"), sc.conf.get("spark.driver.port").toInt),
CoarseGrainedSchedulerBackend.ENDPOINT_NAME)
.......
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory,
command, appUIAddress, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor)
client = new AppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
其中的appDesc很重要
// 这是个很重要的变量appDesc,定义了app的基本信息
private[spark] case class ApplicationDescription(
name: String,
maxCores: Option[Int],
memoryPerExecutorMB: Int,
command: Command,
appUiUrl: String,
eventLogDir: Option[URI] = None,
// short name of compression codec used when writing event logs, if any (e.g. lzf)
eventLogCodec: Option[String] = None,
coresPerExecutor: Option[Int] = None,
user: String = System.getProperty("user.name", "<unknown>")) {
override def toString: String = "ApplicationDescription(" + name + ")"
}
这个地方看下CoarseGrainedSchedulerBackend
override def start() {
val properties = new ArrayBuffer[(String, String)]
for ((key, value) <- scheduler.sc.conf.getAll) {
if (key.startsWith("spark.")) {
properties += ((key, value))
}
}
// TODO (prashant) send conf instead of properties
driverEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint(properties))
}
9.4 APPClient --其实APPClient相当于application与spark集群(master)之间相互通信的组件>registerWithMaster()/tryRegisterAllMasters()/start()
/**
* 向master进行注册Application
*/
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
for (masterAddress <- masterRpcAddresses) yield {
registerMasterThreadPool.submit(new Runnable {
// 在注册时候其实是创建了一个clientActor的线程
override def run(): Unit = try {
if (registered.get) {
return
}
logInfo("Connecting to master " + masterAddress.toSparkURL + "...")
val masterRef =
rpcEnv.setupEndpointRef(Master.SYSTEM_NAME, masterAddress, Master.ENDPOINT_NAME)
masterRef.send(RegisterApplication(appDescription, self))
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
})
}
}
private def registerWithMaster(nthRetry: Int) {
registerMasterFutures.set(tryRegisterAllMasters())
registrationRetryTimer.set(registrationRetryThread.scheduleAtFixedRate(new Runnable {
override def run(): Unit = {
Utils.tryOrExit {
if (registered.get) {
registerMasterFutures.get.foreach(_.cancel(true))
registerMasterThreadPool.shutdownNow()
} else if (nthRetry >= REGISTRATION_RETRIES) {
markDead("All masters are unresponsive! Giving up.")
} else {
registerMasterFutures.get.foreach(_.cancel(true))
registerWithMaster(nthRetry + 1)
}
}
}
}, REGISTRATION_TIMEOUT_SECONDS, REGISTRATION_TIMEOUT_SECONDS, TimeUnit.SECONDS))
}
创建完ApplicationDescription对象后,创建StandaloneAppClient对象,并执行该对象的start方法,把Application信息发送给Master。
def start() {
endpoint.set(rpcEnv.setupEndpoint("AppClient", new ClientEndpoint(rpcEnv)))
}
10. 创建DAGScheduler
DAGScheduler的主要作用是在TaskSchedulerImpl正式提交任务之前做一些准备工作,包括:创建Job,将DAG中的RDD划分到不同的Stage,提交Stage等等。DAGScheduler的创建代码如下:
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler‘s
// constructor
_taskScheduler.start()