所谓过拟合,就是当一个模型过于复杂后,它可以很好的处理训练数据的每一个数据,甚至包括其中的随机噪点。而没有总结训练数据中趋势。使得在应对未知数据时错误里一下变得很大。这明显不是我们要的结果。
我们想要的是在训练中,忽略噪点的干扰,总结整体趋势。在应对未知数据时也能保持训练时的正确率。
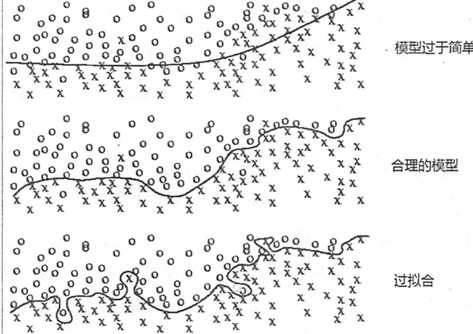
上图中第一种情况,模型过于简单,未能很好的反应数据的总体趋势。
第三种情况就属于过拟合的情况。虽然完美的反应了练习数据的状况,但是明显被噪点影响了。
第二种情况是我们想要的理想状况。
为了避免过拟合,通常使用的方法就是正则化(regularizer)。
正则化的思想就是在损失函数中加入刻画模型复杂度的指标。假设用于刻画模型在训练数据上的表现的损失函数为J(θ),那么在优化时不是直接优化J(θ),而是优化J(θ) + λR(w)。
其中R(w)表示的是模型复杂度。λ表示模型复杂度损失在总损失中的比例。
对于θ表示的是一个神经网络中所有参数,包括weight和 biases。
而复杂度只由权重(weight)来决定。
常用的刻画复杂度R(w)有两种:
L1
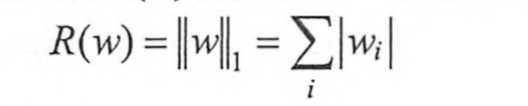
L2:
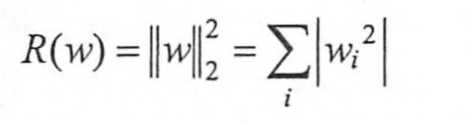
两种思想都是希望限制权重的大小,使得模型不能拟合训练数据中的随机噪点。
两种方式在TensorFlow中的提供的函数为:
tf.contrib.layers.l1_regularizer(scale, scope=None)
tf.contrib.layers.l2_regularizer(scale, scope=None)
参考资料:
《Tensorflow+实战Google深度学习框架》4.4.2节
http://blog.csdn.net/u012436149/article/details/70264257
http://blog.csdn.net/sinat_29957455/article/details/78397601