数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类型有以下几种
一 Number(数字)
1.1 数字类型的创建
a=10 b=a b=666 print(a)#10 print(b)#666
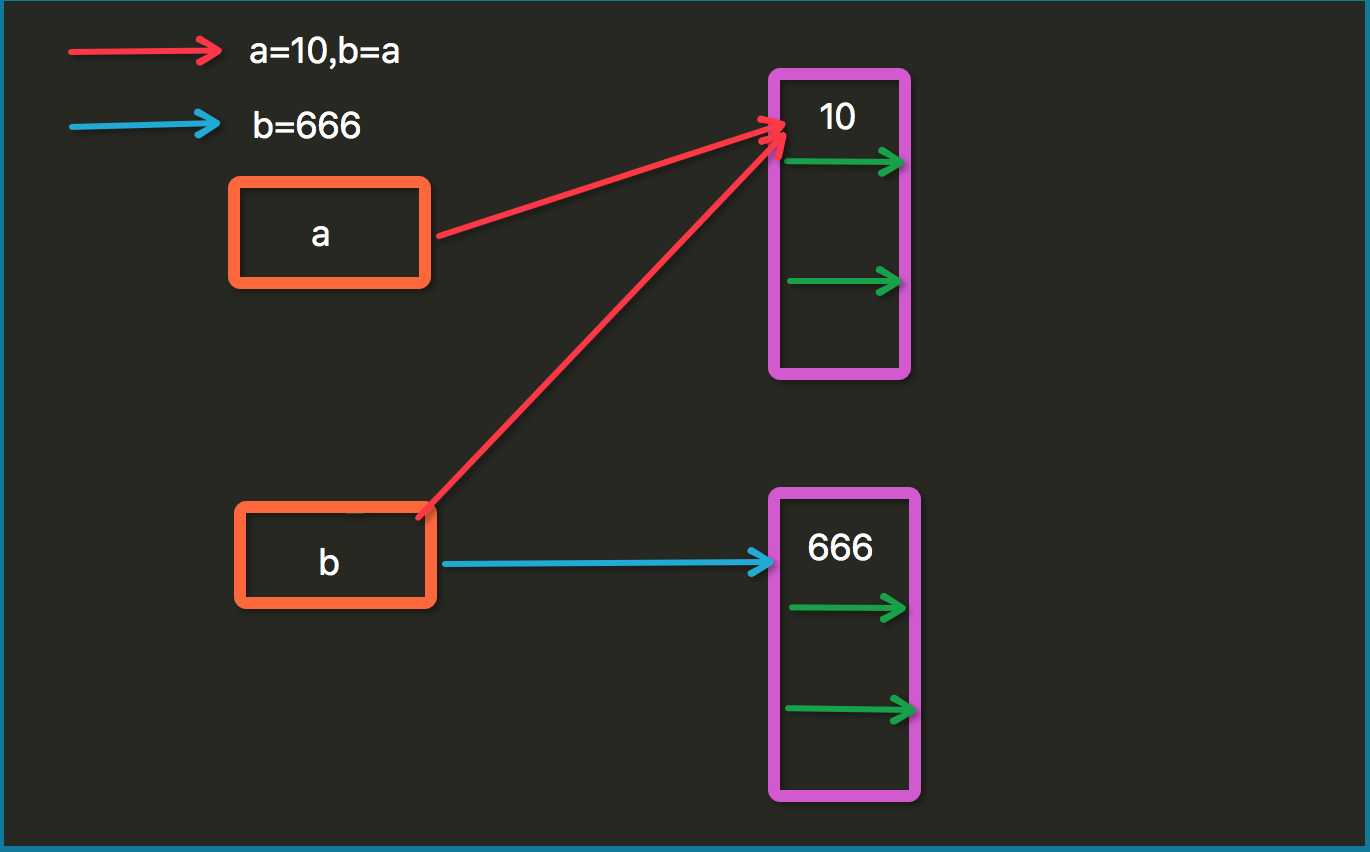
注意这里与C的不同:
#include <stdio.h>
void main(void)
{
int a = 1;
int b = a;
printf ("a:adr:%p,val:%d,b:adr:%p,val:%d\n",&a,a,&b,b);
a = 3;
printf ("a:adr:%p,val:%d,b:adr:%p,val:%d\n",&a,a,&b,b);
}
//打印结果:
topeet@ubuntu:~$ gcc test.c
topeet@ubuntu:~$ ./a.out
a:adr:0x7fff343a069c,val:1
b:adr:0x7fff343a0698,val:1
a:adr:0x7fff343a069c,val:3
b:adr:0x7fff343a0698,val:1
1.2 Number 类型转换
var1=3.14 var2=5 var3=int(var1) var4=float(var2) print(var3,var4)


abs(x) 返回数字的绝对值,如abs(-10) 返回 10 # ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5 # cmp(x, y) 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 # exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 # fabs(x) 返回数字的绝对值,如math.fabs(-10) 返回10.0 # floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4 # log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 # log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0 # max(x1, x2,...) 返回给定参数的最大值,参数可以为序列。 # min(x1, x2,...) 返回给定参数的最小值,参数可以为序列。 # modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 # pow(x, y) x**y 运算后的值。 # round(x [,n]) 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 # sqrt(x) 返回数字x的平方根,数字可以为负数,返回类型为实数,如math.sqrt(4)返回 2+0j
二 字符串类型(string)
字符串是以单引号‘或双引号"括起来的任意文本,比如‘abc‘,"123"等等。
请注意,‘‘或""本身只是一种表示方式,不是字符串的一部分,因此,字符串‘abc‘只有a,b,c这3个字符。如果‘本身也是一个字符,那就可以用""括起来,比如"I‘m OK"包含的字符是I,‘,m,空格,O,K这6个字符。
2.1 创建字符串:
var1 = ‘Hello World!‘ var2 = "Python RAlvin"
对应操作:
# 1 * 重复输出字符串 print(‘hello‘*2) # 2 [] ,[:] 通过索引获取字符串中字符,这里和列表的切片操作是相同的,具体内容见列表 print(‘helloworld‘[2:]) # 3 in 成员运算符 - 如果字符串中包含给定的字符返回 True print(‘el‘ in ‘hello‘) # 4 % 格式字符串 print(‘alex is a good teacher‘) print(‘%s is a good teacher‘%‘alex‘) # 5 + 字符串拼接 a=‘123‘ b=‘abc‘ c=‘789‘ d1=a+b+c print(d1) # +效率低,该用join d2=‘‘.join([a,b,c]) print(d2)
python的内置方法
# string.capitalize() 把字符串的第一个字符大写 # string.center(width) 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 # string.count(str, beg=0, end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 # string.decode(encoding=‘UTF-8‘, errors=‘strict‘) 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除 非 errors 指 定 的 是 ‘ignore‘ 或 者‘replace‘ # string.encode(encoding=‘UTF-8‘, errors=‘strict‘) 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是‘ignore‘或者‘replace‘ # string.endswith(obj, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. # string.expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 # string.find(str, beg=0, end=len(string)) 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 # string.index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在 string中会报一个异常. # string.isalnum() 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False # string.isalpha() 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False # string.isdecimal() 如果 string 只包含十进制数字则返回 True 否则返回 False. # string.isdigit() 如果 string 只包含数字则返回 True 否则返回 False. # string.islower() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False # string.isnumeric() 如果 string 中只包含数字字符,则返回 True,否则返回 False # string.isspace() 如果 string 中只包含空格,则返回 True,否则返回 False. # string.istitle() 如果 string 是标题化的(见 title())则返回 True,否则返回 False # string.isupper() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False # string.join(seq) 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 # string.ljust(width) 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 # string.lower() 转换 string 中所有大写字符为小写. # string.lstrip() 截掉 string 左边的空格 # string.maketrans(intab, outtab]) maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 # max(str) 返回字符串 str 中最大的字母。 # min(str) 返回字符串 str 中最小的字母。 # string.partition(str) 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. # string.replace(str1, str2, num=string.count(str1)) 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. # string.rfind(str, beg=0,end=len(string) ) 类似于 find()函数,不过是从右边开始查找. # string.rindex( str, beg=0,end=len(string)) 类似于 index(),不过是从右边开始. # string.rjust(width) 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 # string.rpartition(str) 类似于 partition()函数,不过是从右边开始查找. # string.rstrip() 删除 string 字符串末尾的空格. # string.split(str="", num=string.count(str)) 以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串 # string.splitlines(num=string.count(‘\n‘)) 按照行分隔,返回一个包含各行作为元素的列表,如果 num 指定则仅切片 num 个行. # string.startswith(obj, beg=0,end=len(string)) 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. # string.strip([obj]) 在 string 上执行 lstrip()和 rstrip() # string.swapcase() 翻转 string 中的大小写 # string.title() 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) # string.translate(str, del="") 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中 # string.upper() 转换 string 中的小写字母为大写
三 字节类型(bytes)
# a=bytes(‘hello‘,‘utf8‘) # a=bytes(‘中国‘,‘utf8‘) a=bytes(‘中国‘,‘utf8‘) b=bytes(‘hello‘,‘gbk‘) # print(a) #b‘\xe4\xb8\xad\xe5\x9b\xbd‘ print(ord(‘h‘)) #其十进制 unicode 值为: 104 print(ord(‘中‘))#其十进制 unicode 值为:20013 # h e l l o # 104 101 108 108 111 编码后结果:与ASCII表对应 # 中 国 # \xd6\xd0 \xb9\xfa gbk编码后的字节结果 #\xe4 \xb8 \xad \xe5 \x9b \xbd utf8编码后的字节结果 # 228 184 173 229 155 189 a[:]切片取 c=a.decode(‘utf8‘) d=b.decode(‘gbk‘) #b=a.decode(‘gbk‘) :很明显报错 print(c) #中国 print(d) #hello
注意:对于 ASCII 字符串,因为无论哪种编码对应的结果都是一样的,所以可以直接使用 b‘xxxx‘ 赋值创建 bytes 实例,但对于非 ASCII 编码的字符则不能通过这种方式创建 bytes 实例,需要指明编码方式。
b1=b‘123‘ print(type(b1)) # b2=b‘中国‘ #报错 # 所以得这样: b2=bytes(‘中国‘,‘utf8‘) print(b2)#b‘\xe4\xb8\xad\xe5\x9b\xbd‘
四 布尔值
一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写)
print(True) print(4>2) print(bool([3,4])) print(True+1)
与或非操作:
bool(1 and 0) bool(1 and 1) bool(1 or 0) bool(not 0)
布尔值经常用在条件判断中:
age=18
if age>18:#bool(age>18)
print(‘old‘)
else:
print(‘young‘)
五 List(列表)
OK,现在我们知道了字符串和整型两个数据类型了,那需求来了,我想把某个班所有的名字存起来,怎么办?
有同学说,不是学变量存储了吗,我就用变量存储呗,呵呵,不嫌累吗,同学,如班里有一百个人,你就得创建一百个变量啊,消耗大,效率低。
又有同学说,我用个大字符串不可以吗,没问题,你的确存起来了,但是,你对这个数据的操作(增删改查)将变得非常艰难,不是吗,我想知道张三的位置,你怎么办?
在这种需求下,编程语言有了一个重要的数据类型----列表(list)
什么是列表:
列表(list)是Python以及其他语言中最常用到的数据结构之一。Python使用使用中括号 [ ] 来解析列表。列表是可变的(mutable)——可以改变列表的内容。
对应操作:
1 查([])
names_class2=[‘张三‘,‘李四‘,‘王五‘,‘赵六‘] # print(names_class2[2]) # print(names_class2[0:3]) # print(names_class2[0:7]) # print(names_class2[-1]) # print(names_class2[2:3]) # print(names_class2[0:3:1]) # print(names_class2[3:0:-1]) # print(names_class2[:])
2 增(append,insert)
insert 方法用于将对象插入到列表中,而append方法则用于在列表末尾追加新的对象
names_class2.append(‘alex‘) names_class2.insert(2,‘alvin‘) print(names_class2)
3 改(重新赋值)
names_class2=[‘张三‘,‘李四‘,‘王五‘,‘赵六‘] names_class2[3]=‘赵七‘ names_class2[0:2]=[‘wusir‘,‘alvin‘] print(names_class2)
4 删(remove,del,pop)
names_class2.remove(‘alex‘) del names_class2[0] del names_class2 names_class2.pop()#注意,pop是有一个返回值的
5 其他操作
5.1 count
count 方法统计某个元素在列表中出现的次数:
>>> [‘to‘, ‘be‘, ‘or‘, ‘not‘, ‘to‘, ‘be‘].count(‘to‘) 2 >>> x = [[1,2], 1, 1, [2, 1, [1, 2]]] >>> x.count(1) 2 >>> x.count([1,2]) 1
5.2 extend
extend 方法可以在列表的末尾一次性追加另一个序列中的多个值。
>>> a = [1, 2, 3] >>> b = [4, 5, 6] >>> a.extend(b) >>> a [1, 2, 3, 4, 5, 6]
extend 方法修改了被扩展的列表,而原始的连接操作(+)则不然,它会返回一个全新的列表。
>>> a = [1, 2, 3] >>> b = [4, 5, 6] >>> a.extend(b) >>> a [1, 2, 3, 4, 5, 6] >>> >>> a + b [1, 2, 3, 4, 5, 6, 4, 5, 6] >>> a [1, 2, 3, 4, 5, 6]
5.3 index
index 方法用于从列表中找出某个值第一个匹配项的索引位置:
names_class2.index(‘李四‘)
5.4 reverse
reverse 方法将列表中的元素反向存放。
names_class2.reverse() print(names_class2)
5.5 sort
sort 方法用于在原位置对列表进行排序。
x = [4, 6, 2, 1, 7, 9] x.sort()#x.sort(reverse=True)
5.6 深浅拷贝
现在,大家先不要理会什么是深浅拷贝,听我说,对于一个列表,我想复制一份怎么办呢?
肯定会有同学说,重新赋值呗:
names_class1=[‘张三‘,‘李四‘,‘王五‘,‘赵六‘] names_class1_copy=[‘张三‘,‘李四‘,‘王五‘,‘赵六‘]
这是两块独立的内存空间
这也没问题,还是那句话,如果列表内容做够大,你真的可以要每一个元素都重新写一遍吗?当然不啦,所以列表里为我们内置了copy方法:
names_class1=[‘张三‘,‘李四‘,‘王五‘,‘赵六‘,[1,2,3]] names_class1_copy=names_class1.copy() names_class1[0]=‘zhangsan‘ print(names_class1) print(names_class1_copy) ############ names_class1[4][2]=5 print(names_class1) print(names_class1_copy) #问题来了,为什么names_class1_copy,从这一点我们可以断定,这两个变量并不是完全独立的,那他们的关系是什么呢?为什么有的改变,有的不改变呢?
这里就涉及到我们要讲的深浅拷贝了:
#不可变数据类型:数字,字符串,元组 可变类型:列表,字典 # l=[2,2,3] # print(id(l)) # l[0]=5 # print(id(l)) # 当你对可变类型进行修改时,比如这个列表对象l,它的内存地址不会变化,注意是这个列表对象l,不是它里面的元素 # # this is the most important # # s=‘alex‘ # print(id(s)) #像字符串,列表,数字这些不可变数据类型,,是不能修改的,比如我想要一个‘Alex‘的字符串,只能重新创建一个‘Alex‘的对象,然后让指针只想这个新对象 # # s[0]=‘e‘ #报错 # print(id(s)) #重点:浅拷贝 a=[[1,2],3,4] b=a[:]#b=a.copy() print(a,b) print(id(a),id(b)) print(‘*************‘) print(‘a[0]:‘,id(a[0]),‘b[0]:‘,id(b[0])) print(‘a[0][0]:‘,id(a[0][0]),‘b[0][0]:‘,id(b[0][0])) print(‘a[0][1]:‘,id(a[0][1]),‘b[0][1]:‘,id(b[0][1])) print(‘a[1]:‘,id(a[1]),‘b[1]:‘,id(b[1])) print(‘a[2]:‘,id(a[2]),‘b[2]:‘,id(b[2])) print(‘___________________________________________‘) b[0][0]=8 print(a,b) print(id(a),id(b)) print(‘*************‘) print(‘a[0]:‘,id(a[0]),‘b[0]:‘,id(b[0])) print(‘a[0][0]:‘,id(a[0][0]),‘b[0][0]:‘,id(b[0][0])) print(‘a[0][1]:‘,id(a[0][1]),‘b[0][1]:‘,id(b[0][1])) print(‘a[1]:‘,id(a[1]),‘b[1]:‘,id(b[1])) print(‘a[2]:‘,id(a[2]),‘b[2]:‘,id(b[2]))
#outcome
# [[1, 2], 3, 4] [[1, 2], 3, 4]
# 4331943624 4331943752
# *************
# a[0]: 4331611144 b[0]: 4331611144
# a[0][0]: 4297375104 b[0][0]: 4297375104
# a[0][1]: 4297375136 b[0][1]: 4297375136
# a[1]: 4297375168 b[1]: 4297375168
# a[2]: 4297375200 b[2]: 4297375200
# ___________________________________________
# [[8, 2], 3, 4] [[8, 2], 3, 4]
# 4331943624 4331943752
# *************
# a[0]: 4331611144 b[0]: 4331611144
# a[0][0]: 4297375328 b[0][0]: 4297375328
# a[0][1]: 4297375136 b[0][1]: 4297375136
# a[1]: 4297375168 b[1]: 4297375168
# a[2]: 4297375200 b[2]: 4297375200
那么怎么解释这样的一个结果呢?
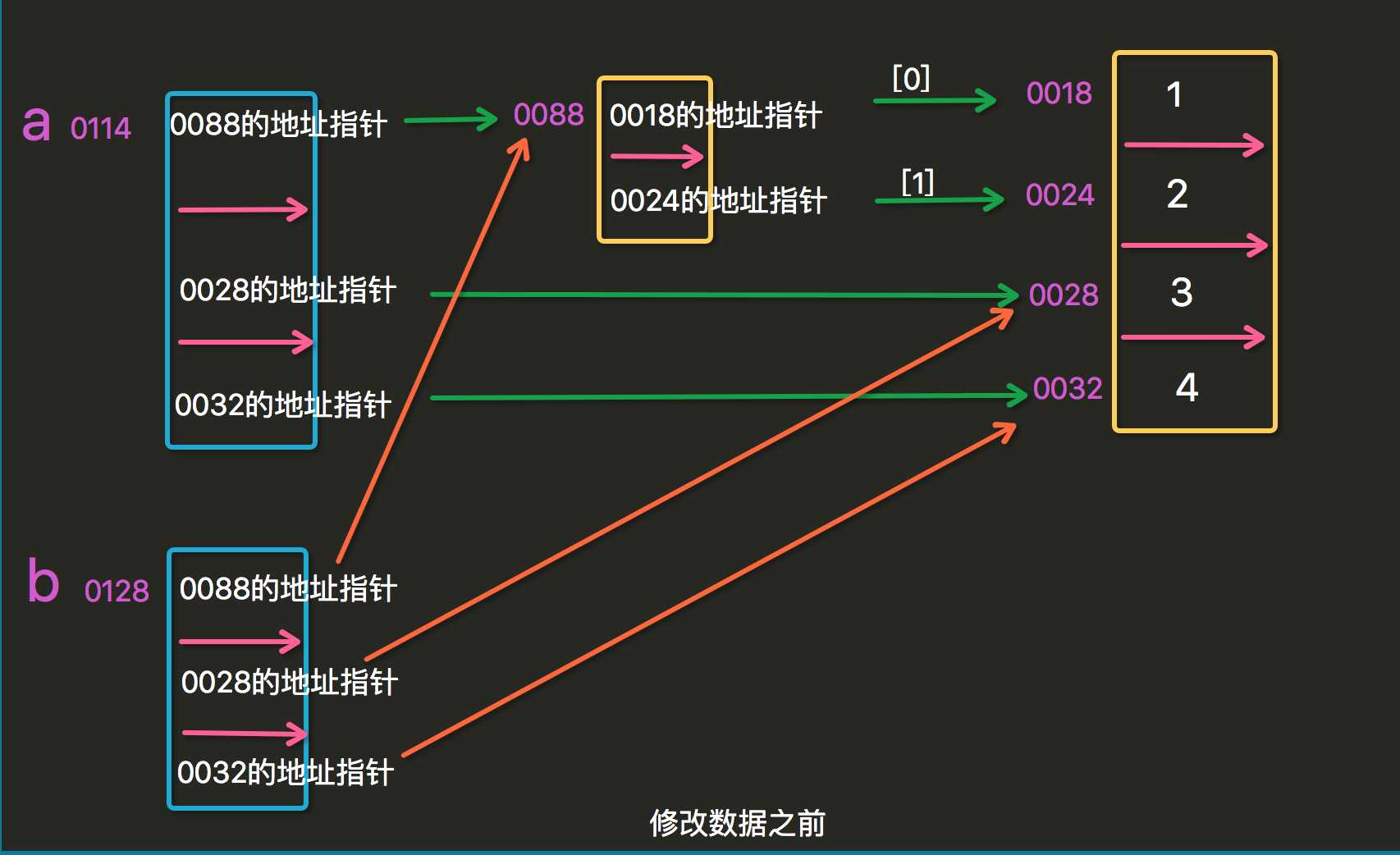
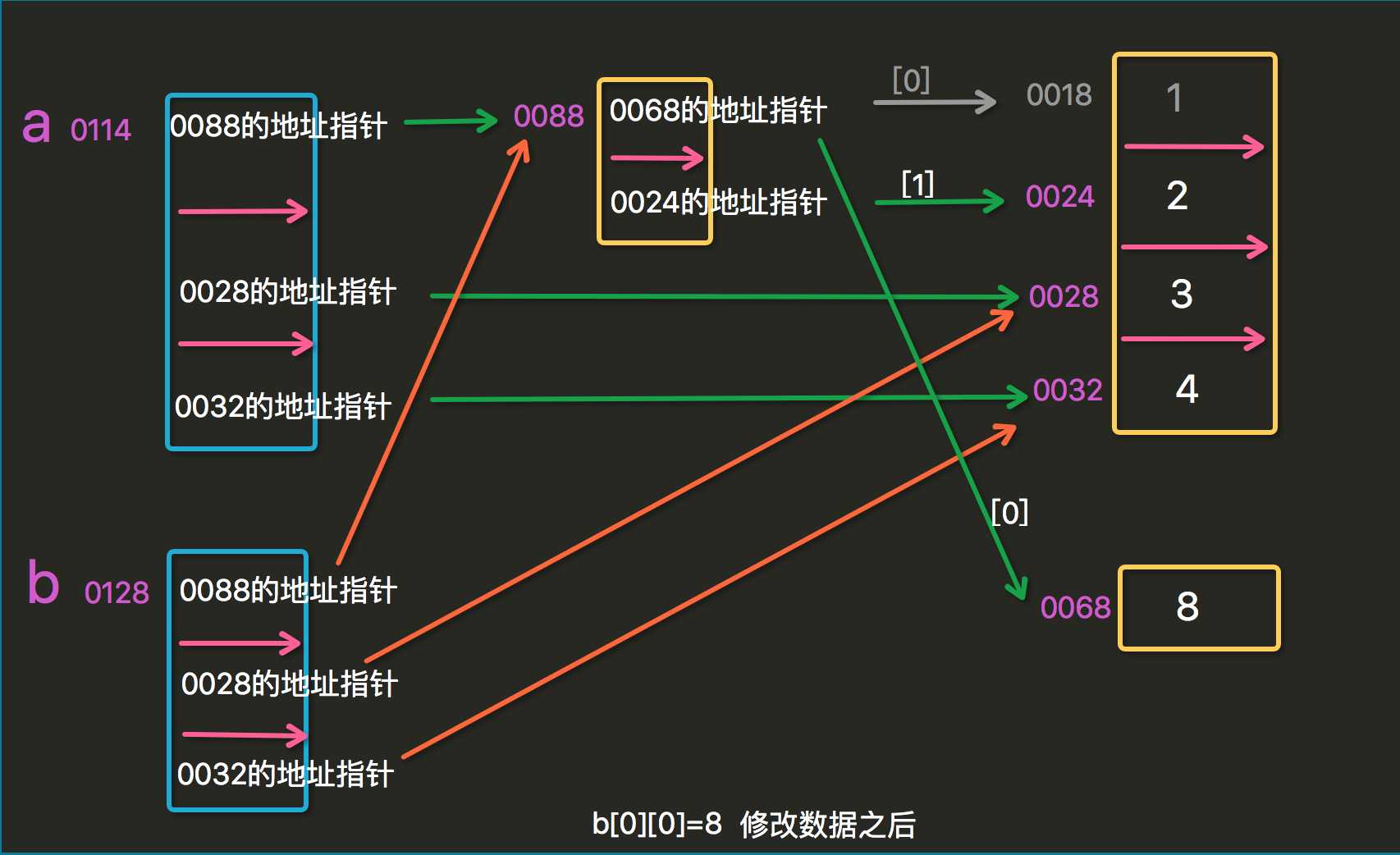
再不懂,俺就没办法啦...
列表补充:
b,*c=[1,2,3,4,5]
六 tuple(元组)
元组被称为只读列表,即数据可以被查询,但不能被修改,所以,列表的切片操作同样适用于元组。
元组写在小括号(())里,元素之间用逗号隔开。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
tup1 = () # 空元组 tup2 = (20,) # 一个元素,需要在元素后添加逗号
作用:
1 对于一些数据我们不想被修改,可以使用元组;
2 另外,元组的意义还在于,元组可以在映射(和集合的成员)中当作键使用——而列表则不行;元组作为很多内建函数和方法的返回值存在。
字典
# product_list=[ # (‘book‘,100), # (‘Mac Pro‘,9000), # (‘watch‘,500), # (‘coffee‘,30), # (‘Python‘,106),] # # saving=input(‘input your saving:‘) # shopping_car=[] # # if saving.isdigit(): # saving=int(saving) # while True: # for i,v in enumerate(product_list): # print(i,v) # user_choice=input(‘选择购买商品编号[退出:q]:‘) # # if user_choice.isdigit(): # user_choice=int(user_choice) # if user_choice<len(product_list) and user_choice>=0: # product_item=product_list[user_choice] # if product_item[1]<saving: # saving-=product_item[1] # shopping_car.append(product_item) # print(‘您当前的余额为%s‘%saving) # else: # print(‘编号错误‘) # elif user_choice==‘q‘: # print(‘---------您已经购买如下商品-----------‘) # for i in shopping_car: # print(i) # print(‘您的余额为%s‘%saving) # break # # else: # print(‘invalid choice‘)
七 Dictionary(字典)
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
字典(dictionary)是除列表意外python之中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
创建字典:
dic1={‘name‘:‘alex‘,‘age‘:36,‘sex‘:‘male‘}
dic2=dict(((‘name‘,‘alex‘),))
print(dic1)
print(dic2)
对应操作:
1 增
dic3={}
dic3[‘name‘]=‘alex‘
dic3[‘age‘]=18
print(dic3)#{‘name‘: ‘alex‘, ‘age‘: 18}
a=dic3.setdefault(‘name‘,‘yuan‘)
b=dic3.setdefault(‘ages‘,22)
print(a,b)
print(dic3)
2 查
dic3={‘name‘: ‘alex‘, ‘age‘: 18}
# print(dic3[‘name‘])
# print(dic3[‘names‘])
#
# print(dic3.get(‘age‘,False))
# print(dic3.get(‘ages‘,False))
print(dic3.items())
print(dic3.keys())
print(dic3.values())
print(‘name‘ in dic3)# py2: dic3.has_key(‘name‘)
print(list(dic3.values()))
3 改
dic3={‘name‘: ‘alex‘, ‘age‘: 18}
dic3[‘name‘]=‘alvin‘
dic4={‘sex‘:‘male‘,‘hobby‘:‘girl‘,‘age‘:36}
dic3.update(dic4)
print(dic3)
4 删
dic4={‘name‘: ‘alex‘, ‘age‘: 18,‘class‘:1}
# dic4.clear()
# print(dic4)
del dic4[‘name‘]
print(dic4)
a=dic4.popitem()
print(a,dic4)
# print(dic4.pop(‘age‘))
# print(dic4)
# del dic4
# print(dic4)
5 其他操作以及涉及到的方法
5.1 dict.fromkeys
d1=dict.fromkeys([‘host1‘,‘host2‘,‘host3‘],‘Mac‘) print(d1) d1[‘host1‘]=‘xiaomi‘ print(d1) ####### d2=dict.fromkeys([‘host1‘,‘host2‘,‘host3‘],[‘Mac‘,‘huawei‘]) print(d2) d2[‘host1‘][0]=‘xiaomi‘ print(d2)
5.2 d.copy() 对字典 d 进行浅复制,返回一个和d有相同键值对的新字典
5.3 字典的嵌套
av_catalog = { "欧美":{ "www.youporn.com": ["很多免费的,世界最大的","质量一般"], "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] }, "日韩":{ "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] }, "大陆":{ "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] } } av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来" print(av_catalog["大陆"]["1024"]) #ouput [‘全部免费,真好,好人一生平安‘, ‘服务器在国外,慢,可以用爬虫爬下来‘]
5.4 sorted(dict) : 返回一个有序的包含字典所有key的列表
dic={5:‘555‘,2:‘222‘,4:‘444‘}
print(sorted(dic))
5.5 字典的遍历
dic5={‘name‘: ‘alex‘, ‘age‘: 18}
for i in dic5:
print(i,dic5[i])
for items in dic5.items():
print(items)
for keys,values in dic5.items():
print(keys,values)
还用我们上面的例子,存取这个班学生的信息,我们如果通过字典来完成,那:
dic={‘zhangsan‘:{‘age‘:23,‘sex‘:‘male‘},
‘李四‘:{‘age‘:33,‘sex‘:‘male‘},
‘wangwu‘:{‘age‘:27,‘sex‘:‘women‘}
}
八 集合(set)
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
集合(set):把不同的元素组成一起形成集合,是python基本的数据类型。
集合元素(set elements):组成集合的成员(不可重复)
li=[1,2,‘a‘,‘b‘]
s =set(li)
print(s) # {1, 2, ‘a‘, ‘b‘}
li2=[1,2,1,‘a‘,‘a‘]
s=set(li2)
print(s) #{1, 2, ‘a‘}
集合对象是一组无序排列的可哈希的值:集合成员可以做字典的键
li=[[1,2],‘a‘,‘b‘] s =set(li) #TypeError: unhashable type: ‘list‘ print(s)
集合分类:可变集合、不可变集合
可变集合(set):可添加和删除元素,非可哈希的,不能用作字典的键,也不能做其他集合的元素
不可变集合(frozenset):与上面恰恰相反
li=[1,‘a‘,‘b‘]
s =set(li)
dic={s:‘123‘} #TypeError: unhashable type: ‘set‘
集合的相关操作
1、创建集合
由于集合没有自己的语法格式,只能通过集合的工厂方法set()和frozenset()创建
s1 = set(‘alvin‘)
s2= frozenset(‘yuan‘)
print(s1,type(s1)) #{‘l‘, ‘v‘, ‘i‘, ‘a‘, ‘n‘} <class ‘set‘>
print(s2,type(s2)) #frozenset({‘n‘, ‘y‘, ‘a‘, ‘u‘}) <class ‘frozenset‘>
2、访问集合
由于集合本身是无序的,所以不能为集合创建索引或切片操作,只能循环遍历或使用in、not in来访问或判断集合元素。
s1 = set(‘alvin‘)
print(‘a‘ in s1)
print(‘b‘ in s1)
#s1[1] #TypeError: ‘set‘ object does not support indexing
for i in s1:
print(i)
#
# True
# False
# v
# n
# l
# i
# a
3、更新集合
可使用以下内建方法来更新:
s.add()
s.update()
s.remove()
注意只有可变集合才能更新:
# s1 = frozenset(‘alvin‘)
# s1.add(0) #AttributeError: ‘frozenset‘ object has no attribute ‘add‘
s2=set(‘alvin‘)
s2.add(‘mm‘)
print(s2) #{‘mm‘, ‘l‘, ‘n‘, ‘a‘, ‘i‘, ‘v‘}
s2.update(‘HO‘)#添加多个元素
print(s2) #{‘mm‘, ‘l‘, ‘n‘, ‘a‘, ‘i‘, ‘H‘, ‘O‘, ‘v‘}
s2.remove(‘l‘)
print(s2) #{‘mm‘, ‘n‘, ‘a‘, ‘i‘, ‘H‘, ‘O‘, ‘v‘}
del:删除集合本身
四、集合类型操作符
1 in ,not in
2 集合等价与不等价(==, !=)
3 子集、超集
s=set(‘alvinyuan‘) s1=set(‘alvin‘) print(‘v‘ in s) print(s1<s)
4 联合(|)
联合(union)操作与集合的or操作其实等价的,联合符号有个等价的方法,union()。
s1=set(‘alvin‘)
s2=set(‘yuan‘)
s3=s1|s2
print(s3) #{‘a‘, ‘l‘, ‘i‘, ‘n‘, ‘y‘, ‘v‘, ‘u‘}
print(s1.union(s2)) #{‘a‘, ‘l‘, ‘i‘, ‘n‘, ‘y‘, ‘v‘, ‘u‘}
5、交集(&)
与集合and等价,交集符号的等价方法是intersection()
s1=set(‘alvin‘)
s2=set(‘yuan‘)
s3=s1&s2
print(s3) #{‘n‘, ‘a‘}
print(s1.intersection(s2)) #{‘n‘, ‘a‘}
6、查集(-)
等价方法是difference()
s1=set(‘alvin‘)
s2=set(‘yuan‘)
s3=s1-s2
print(s3) #{‘v‘, ‘i‘, ‘l‘}
print(s1.difference(s2)) #{‘v‘, ‘i‘, ‘l‘}
7、对称差集(^)
对称差分是集合的XOR(‘异或’),取得的元素属于s1,s2但不同时属于s1和s2.其等价方法symmetric_difference()
s1=set(‘alvin‘)
s2=set(‘yuan‘)
s3=s1^s2
print(s3) #{‘l‘, ‘v‘, ‘y‘, ‘u‘, ‘i‘}
print(s1.symmetric_difference(s2)) #{‘l‘, ‘v‘, ‘y‘, ‘u‘, ‘i‘}
应用
‘‘‘最简单的去重方式‘‘‘ lis = [1,2,3,4,1,2,3,4] print list(set(lis)) #[1, 2, 3, 4]
九 文件操作
9.1 对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
现有文件如下:
昨夜寒蛩不住鸣。 惊回千里梦,已三更。 起来独自绕阶行。 人悄悄,帘外月胧明。 白首为功名,旧山松竹老,阻归程。 欲将心事付瑶琴。 知音少,弦断有谁听。
f = open(‘小重山‘) #打开文件 data=f.read()#获取文件内容 f.close() #关闭文件
注意 if in the win,hello文件是utf8保存的,打开文件时open函数是通过操作系统打开的文件,而win操作系统
默认的是gbk编码,所以直接打开会乱码,需要f=open(‘hello‘,encoding=‘utf8‘),hello文件如果是gbk保存的,则直接打开即可。
9.2 文件打开模式
========= ===============================================================
Character Meaning
--------- ---------------------------------------------------------------
‘r‘ open for reading (default)
‘w‘ open for writing, truncating the file first
‘x‘ create a new file and open it for writing
‘a‘ open for writing, appending to the end of the file if it exists
‘b‘ binary mode
‘t‘ text mode (default)
‘+‘ open a disk file for updating (reading and writing)
‘U‘ universal newline mode (deprecated)
========= ===============================================================
先介绍三种最基本的模式:
# f = open(‘小重山2‘,‘w‘) #打开文件 # f = open(‘小重山2‘,‘a‘) #打开文件 # f.write(‘莫等闲1\n‘) # f.write(‘白了少年头2\n‘) # f.write(‘空悲切!3‘)
9.3 文件具体操作
def read(self, size=-1): # known case of _io.FileIO.read """ 注意,不一定能全读回来 Read at most size bytes, returned as bytes. Only makes one system call, so less data may be returned than requested. In non-blocking mode, returns None if no data is available. Return an empty bytes object at EOF. """ return "" def readline(self, *args, **kwargs): pass def readlines(self, *args, **kwargs): pass def tell(self, *args, **kwargs): # real signature unknown """ Current file position. Can raise OSError for non seekable files. """ pass def seek(self, *args, **kwargs): # real signature unknown """ Move to new file position and return the file position. Argument offset is a byte count. Optional argument whence defaults to SEEK_SET or 0 (offset from start of file, offset should be >= 0); other values are SEEK_CUR or 1 (move relative to current position, positive or negative), and SEEK_END or 2 (move relative to end of file, usually negative, although many platforms allow seeking beyond the end of a file). Note that not all file objects are seekable. """ pass def write(self, *args, **kwargs): # real signature unknown """ Write bytes b to file, return number written. Only makes one system call, so not all of the data may be written. The number of bytes actually written is returned. In non-blocking mode, returns None if the write would block. """ pass def flush(self, *args, **kwargs): pass def truncate(self, *args, **kwargs): # real signature unknown """ Truncate the file to at most size bytes and return the truncated size. Size defaults to the current file position, as returned by tell(). The current file position is changed to the value of size. """ pass def close(self): # real signature unknown; restored from __doc__ """ Close the file. A closed file cannot be used for further I/O operations. close() may be called more than once without error. """ pass ##############################################################less usefull def fileno(self, *args, **kwargs): # real signature unknown """ Return the underlying file descriptor (an integer). """ pass def isatty(self, *args, **kwargs): # real signature unknown """ True if the file is connected to a TTY device. """ pass def readable(self, *args, **kwargs): # real signature unknown """ True if file was opened in a read mode. """ pass def readall(self, *args, **kwargs): # real signature unknown """ Read all data from the file, returned as bytes. In non-blocking mode, returns as much as is immediately available, or None if no data is available. Return an empty bytes object at EOF. """ pass def seekable(self, *args, **kwargs): # real signature unknown """ True if file supports random-access. """ pass def writable(self, *args, **kwargs): # real signature unknown """ True if file was opened in a write mode. """ pass
f = open(‘小重山‘) #打开文件
# data1=f.read()#获取文件内容
# data2=f.read()#获取文件内容
#
# print(data1)
# print(‘...‘,data2)
# data=f.read(5)#获取文件内容
# data=f.readline()
# data=f.readline()
# print(f.__iter__().__next__())
# for i in range(5):
# print(f.readline())
# data=f.readlines()
# for line in f.readlines():
# print(line)
# 问题来了:打印所有行,另外第3行后面加上:‘end 3‘
# for index,line in enumerate(f.readlines()):
# if index==2:
# line=‘‘.join([line.strip(),‘end 3‘])
# print(line.strip())
#切记:以后我们一定都用下面这种
# count=0
# for line in f:
# if count==3:
# line=‘‘.join([line.strip(),‘end 3‘])
# print(line.strip())
# count+=1
# print(f.tell())
# print(f.readline())
# print(f.tell())#tell对于英文字符就是占一个,中文字符占三个,区分与read()的不同.
# print(f.read(5))#一个中文占三个字符
# print(f.tell())
# f.seek(0)
# print(f.read(6))#read后不管是中文字符还是英文字符,都统一算一个单位,read(6),此刻就读了6个中文字符
#terminal上操作:
f = open(‘小重山2‘,‘w‘)
# f.write(‘hello \n‘)
# f.flush()
# f.write(‘world‘)
# 应用:进度条
# import time,sys
# for i in range(30):
# sys.stdout.write("*")
# # sys.stdout.flush()
# time.sleep(0.1)
# f = open(‘小重山2‘,‘w‘)
# f.truncate()#全部截断
# f.truncate(5)#全部截断
# print(f.isatty())
# print(f.seekable())
# print(f.readable())
f.close() #关闭文件
接下来我们继续扩展文件模式:
# f = open(‘小重山2‘,‘w‘) #打开文件
# f = open(‘小重山2‘,‘a‘) #打开文件
# f.write(‘莫等闲1\n‘)
# f.write(‘白了少年头2\n‘)
# f.write(‘空悲切!3‘)
# f.close()
#r+,w+模式
# f = open(‘小重山2‘,‘r+‘) #以读写模式打开文件
# print(f.read(5))#可读
# f.write(‘hello‘)
# print(‘------‘)
# print(f.read())
# f = open(‘小重山2‘,‘w+‘) #以写读模式打开文件
# print(f.read(5))#什么都没有,因为先格式化了文本
# f.write(‘hello alex‘)
# print(f.read())#还是read不到
# f.seek(0)
# print(f.read())
#w+与a+的区别在于是否在开始覆盖整个文件
# ok,重点来了,我要给文本第三行后面加一行内容:‘hello 岳飞!‘
# 有同学说,前面不是做过修改了吗? 大哥,刚才是修改内容后print,现在是对文件进行修改!!!
# f = open(‘小重山2‘,‘r+‘) #以写读模式打开文件
# f.readline()
# f.readline()
# f.readline()
# print(f.tell())
# f.write(‘hello 岳飞‘)
# f.close()
# 和想的不一样,不管事!那涉及到文件修改怎么办呢?
# f_read = open(‘小重山‘,‘r‘) #以写读模式打开文件
# f_write = open(‘小重山_back‘,‘w‘) #以写读模式打开文件
# count=0
# for line in f_read:
# if count==3:
# f_write.write(‘hello,岳飞\n‘)
#
# else:
# f_write.write(line)
# another way:
# if count==3:
#
# line=‘hello,岳飞2\n‘
# f_write.write(line)
# count+=1
# #二进制模式
# f = open(‘小重山2‘,‘wb‘) #以二进制的形式读文件
# # f = open(‘小重山2‘,‘wb‘) #以二进制的形式写文件
# f.write(‘hello alvin!‘.encode())#b‘hello alvin!‘就是一个二进制格式的数据,只是为了观看,没有显示成010101的形式
注意1: 无论是py2还是py3,在r+模式下都可以等量字节替换,但没有任何意义的!
注意2:有同学在这里会用readlines得到内容列表,再通过索引对相应内容进行修改,最后将列表重新写会该文件。
这种思路有一个很大的问题,数据若很大,你的内存会受不了的,而我们的方式则可以通过迭代器来优化这个过程。
补充:rb模式以及seek
在py2中:
#昨夜寒蛩不住鸣. f = open(‘test‘,‘r‘,) #以写读模式打开文件 f.read(3) # f.seek(3) # print f.read(3) # 夜 # f.seek(3,1) # print f.read(3) # 寒 # f.seek(-4,2) # print f.read(3) # 鸣
在py3中:
# test: 昨夜寒蛩不住鸣. f = open(‘test‘,‘rb‘,) #以写读模式打开文件 f.read(3) # f.seek(3) # print(f.read(3)) # b‘\xe5\xa4\x9c‘ # f.seek(3,1) # print(f.read(3)) # b‘\xe5\xaf\x92‘ # f.seek(-4,2) # print(f.read(3)) # b‘\xe9\xb8\xa3‘ #总结: 在py3中,如果你想要字符数据,即用于观看的,则用r模式,这样我f.read到的数据是一个经过decode的 # unicode数据; 但是如果这个数据我并不需要看,而只是用于传输,比如文件上传,那么我并不需要decode # 直接传送bytes就好了,所以这个时候用rb模式. # 在py3中,有一条严格的线区分着bytes和unicode,比如seek的用法,在py2和py3里都是一个个字节的seek, # 但在py3里你就必须声明好了f的类型是rb,不允许再模糊. #建议: 以后再读写文件的时候直接用rb模式,需要decode的时候仔显示地去解码.
9.4 with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open(‘log‘,‘r‘) as f:
pass
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open(‘log1‘) as obj1, open(‘log2‘) as obj2:
pass