大数据:Hadoop入门
一:什么是大数据
- 什么是大数据:
(1.)大数据是指在一定时间内无法用常规软件对其内容进行抓取,管理和处理的数据集合,简而言之就是数据量非常大,大到无法用常规工具进行处理,如关系型数据库,数据仓库等。这里“大”是一个什么量级呢?如在阿里巴巴每天处理数据达到20PB(即20971520GB).
2.大数据的特点:
(1.)体量巨大。按目前的发展趋势来看,大数据的体量已经到达PB级甚至EB级。
(2.)大数据的数据类型多样,以非结构化数据为主,如网络杂志,音频,视屏,图片,地理位置信息,交易数据,社交数据等。
(3.)价值密度低。有价值的数据仅占到总数据的一小部分。比如一段视屏中,仅有几秒的信息是有价值的。
(4.)产生和要求处理速度快。这是大数据区与传统数据挖掘最显著的特征。
3.除此之外还有其他处理系统可以处理大数据。
Hadoop (开源)
Spark(开源)
Storm(开源)
MongoDB(开源)
IBM PureDate(商用)
Oracle Exadata(商用)
SAP Hana(商用)
Teradata AsterData(商用)
EMC GreenPlum(商用)
HP Vertica(商用)
注:这里我们只介绍Hadoop。
二:Hadoop体系结构
- Hadoop来源:
Hadoop源于Google在2003到2004年公布的关于GFS(Google File System),MapReduce和BigTable的三篇论文,创始人Doug Cutting。Hadoop现在是Apache基金会顶级项目,“Hadoop”一个虚构的名字。由Doug Cutting的孩子为其黄色玩具大象所命名。
- Hadoop的核心:
(1.)HDFS和MapReduce是Hadoop的两大核心。通过HDFS来实现对分布式储存的底层支持,达到高速并行读写与大容量的储存扩展。
(2.)通过MapReduce实现对分布式任务进行处理程序支持,保证高速分区处理数据。
3.Hadoop子项目:

(1.)HDFS:分布式文件系统,整个Hadoop体系的基石。
(2.)MapReduce/YARN:并行编程模型。YARN是第二代的MapReduce框架,从Hadoop 0.23.01版本后,MapReduce被重构,通常也称为MapReduce V2,老MapReduce也称为 MapReduce V1。
(3.)Hive:建立在Hadoop上的数据仓库,提供类似SQL语音的查询方式,查询Hadoop中的数据,
(4.)Pig:一个队大型数据进行分析和评估的平台,主要作用类似于数据库中储存过程。
(5.)HBase:全称Hadoop Database,Hadoop的分布式的,面向列的数据库,来源于Google的关于BigTable的论文,主要用于随机访问,实时读写的大数据。
(6.)ZooKeeper:是一个为分布式应用所设计的协调服务,主要为用户提供同步,配置管理,分组和命名等服务,减轻分布式应用程序所承担的协调任务。
还有其它特别多其它项目这里不做一一解释了。
三:安装Hadoop运行环境
- 用户创建:
(1.)创建Hadoop用户组,输入命令:
groupadd hadoop
(2.)创建hduser用户,输入命令:
useradd –p hadoop hduser
(3.)设置hduser的密码,输入命令:
passwd hduser
按提示输入两次密码
(4.)为hduser用户添加权限,输入命令:
#修改权限
chmod 777 /etc/sudoers
#编辑sudoers
Gedit /etc/sudoers
#还原默认权限
chmod 440 /etc/sudoers
先修改sudoers 文件权限,并在文本编辑窗口中查找到行“root ALL=(ALL)”,紧跟后面更新加行“hduser ALL=(ALL) ALL”,将hduser添加到sudoers。添加完成后切记还原默认权限,否则系统将不允许使用sudo命令。
(5.)设置好后重启虚拟机,输入命令:
Sudo reboot
重启后切换到hduser用户登录
- 安装JDK
(1.)下载jdk-7u67-linux-x64.rpm,并进入下载目录。
(2.)运行安装命令:
Sudo rpm –ivh jdk-7u67-linux-x64.rpm
完成后查看安装路径,输入命令:
Rpm –qa jdk –l
记住该路径,
(3.)配置环境变量,输入命令:
Sudo gedit /etc/profile
打开profile文件在文件最下面加入如下内容
export JAVA_HOME=/usr/java/jdk.7.0.67
export CLASSPATH=$ JAVA_HOME/lib:$ CLASSPATH
export PATH=$ JAVA_HOME/bin:$PATH
保存后关闭文件,然后输入命令使环境变量生效:
Source /etc/profile
(4.)验证JDK,输入命令:
Java –version
若出现正确的版本则安装成功。
- 配置本机SSH免密码登录:
(1.)使用ssh-keygen 生成私钥与公钥文件,输入命令:
ssh-keygen –t rsa
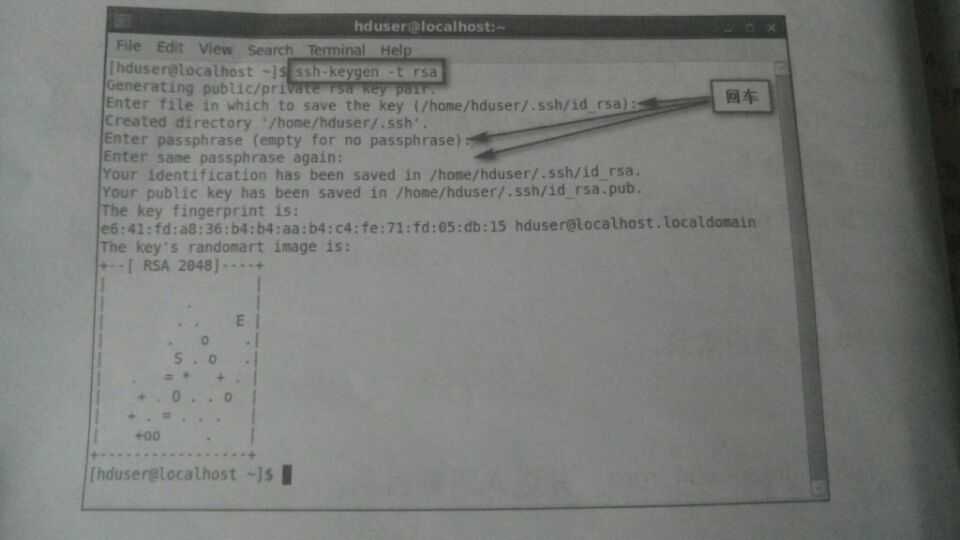
(2.)私钥留在本机,公钥发给其它主机(现在是localhost)。输入命令:
ssh-copy-id localhost
(3.)使用公钥来登录输入命令:
ssh localhost
- 配置其它主机SSH免密登录
(1.)克隆两次。在VMware左侧栏中选中虚拟机右击,在弹出的快捷键菜单中选中管理---克隆命令。在克隆类型时选中“创建完整克隆”,单击“下一步”,按钮直到完成。
(2.)分别启动并进入三台虚拟机,使用ifconfig查询个主机IP地址。
(3.)修改每台主机的hostname及hosts文件。
步骤1:修改hostname,分别在各主机中输入命令。
Sudo gedit /etc/sysconfig/network
步骤2:修改hosts文件:
sudo gedit /etc/hosts
步骤3:修改三台虚拟机的IP
第一台对应node1虚拟机的IP:192.168.1.130
第二台对应node2虚拟机的IP:192.168.1.131
第三台对应node3虚拟机的IP:192.168.1.132
(4.)由于已经在node1上生成过密钥对,所有现在只要在node1上输入命令:
ssh-copy-id node2
ssh-copy-id node3
这样就可以将node1的公钥发布到node2,node3。
(5.)测试SSH,在node1上输入命令:
ssh node2
#退出登录
exit
ssh node3
exit
四:Hadoop完全分布式安装
- 1. Hadoop有三种运行方式:
(1.)单机模式:无须配置,Hadoop被视为一个非分布式模式运行的独立Java进程
(2.)伪分布式:只有一个节点的集群,这个节点即是Master(主节点,主服务器)也是Slave(从节点,从服务器),可在此单节点上以不同的java进程模拟分布式中的各类节点
(3.)完全分布式:对于Hadoop,不同的系统会有不同的节点划分方式。
2.安装Hadoop
(1.)获取Hadoop压缩包hadoop-2.6.0.tar.gz,下载后可以使用VMWare Tools通过共享文件夹,或者使用Xftp工具传到node1。进入node1 将压缩包解压到/home/hduser目录下,输入命令:
#进入HOME目录即:“/home/hduser”
cd ~
tar –zxvf hadoop-2.6.0.tar.gz
(2.)重命名hadoop输入命令:
mv hadoop-2.6.0 hadoop
(3.)配置Hadoop环境变量,输入命令:
Sudo gedit /etc/profile
将以下脚本加到profile内:
#hadoop
export HADOOP_HOME=/home/hduser/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
保存关闭,最后输入命令使配置生效
source /etc/profile
注:node2,和node3都要按照以上配置进行配置。
3.配置Hadoop
(1.)hadoop-env.sh文件用于指定JDK路径。输入命令:
[hduser@node1 ~]$ cd ~/hadoop/etc/hadoop
[hduser@node1 hadoop]$ gedit hadoop-env.sh
然后增加如下内容指定jDK路径。
export JAVA_HOME=/usr/java/jdk1.7.0_67
(2.)打开指定JDK路径,输入命令:
export JAVA_HOME=/usr/java/jdk1.7.0_67
(3.)slaves:用于增加slave节点即DataNode节点。
[hduser@node1 hadoop]$ gedit slaves
打开并清空原内容,然后输入如下内容:
node2
node3
表示node2,node3作为slave节点。
(4.)core-site.xml:该文件是Hadoop全局配置,打开并在<configuration>元素中增加配置属性如下:
<configuration>
<property>
<name>fs.defaultFs</name>
<value>hdfs://node1:9000</value>
</property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hduser/hadoop/tmp</value>
</property>
<configuration>
这里给出了两个常用的配置属性,fs.defaultFS表示客户端连接HDFS时,默认路径前缀,9000是HDFS工作的端口。Hadoop.tmp.dir如不指定会保存到系统的默认临时文件目录/tmp中。
(5.)hdfs-site.xml:该文件是hdfs的配置。打开并在<configuration>元素中增加配置属性。
(6.)mapred-site.xml:该文件是MapReduce的配置,可从模板文件mapred-site.xml.template中复制打开并在<configuration>元素中增加配置。
(7.)yarn-site.xml:如果在mapred-site.xml配置了使用YARN框架,那么YARN框架就使用此文件中的配置,打开并在<configuration>元素中增加配置属性。
(8.)复制这七个命令到node2,node3。输入命令如下:
scp –r /home/hduser/hadoop/etc/hadoop/ hduser@node2:/home/hduser/hadoop/etc/
scp –r /home/hduser/hadoop/etc/hadoop/ hduser@node3:/home/hduser/hadoop/etc/
4.验证:
下面验证hadoop是否正确
(1.)在Master主机(node1)上格式化NameNode。输入命令:
[hduser@node1 ~]$ cd ~/hadoop
[hduser@node1 hadoop]$ bin/hdfs namenode –format
(2)关闭node1,node2 ,node3,系统防火墙并重启虚拟机。输入命令:
service iptables stop
sudo chkconfig iptables off
reboot
(3.)输入以下启动HDFS:
[hduser@node1 ~]$ cd ~/hadoop
(4.)启动所有
[hduser@node1 hadoop]$ sbin/start-all.sh
(5.)查看集群状态:
[hduser@node1 hadoop]$ bin/hdfs dfsadmin –report
(6.)在浏览器中查看hdfs运行状态,网址:http://node1:50070
(7.)停止Hadoop。输入命令:
[hduser@node1 hadoop]$ sbin/stop-all.sh
五:Hadoop相关的shell操作
(1.)在操作系统中/home/hduser/file目录下创建file1.txt,file2.txt可使用图形界面创建。
file1.txt输入内容:
Hello World hi HADOOP
file2.txt输入内容
Hello World hi CHIAN
(2.)启动hdfs后创建目录/input2
[hduser@node1 hadoop]$ bin/hadoop fs –mkdir /input2
(3.)将file1.txt.file2.txt保存到hdfs中:
[hduser@node1 hadoop]$ bin/hadoop fs –put -/file/file*.txt /input2/
(4.)[hduser@node1 hadoop]$ bin/hadoop fs –ls /input2