[Spark性能调优] Spark Shuffle 中 JVM 内存使用及配置详情
本课主题
|
引言
Spark 从1.6.x 开始对 JVM 的内存使用作出了一种全新的改变,Spark 1.6.x 以前是基于静态固定的JVM内存使用架构和运行机制,如果你不知道 Spark 到底对 JVM 是怎么使用,你怎么可以很有信心地或者是完全确定地掌握和控制数据的缓存空间呢,所以掌握Spark对JVM的内存使用内幕是至关重要的。很多人对 Spark 的印象是:它是基于内存的,而且可以缓存一大堆数据,显现 Spark 是基于内存的观点是错的,Spark 只是优先充分地利用内存而已。如果你不知道 Spark 可以缓存多少数据,你就误乱地缓存数据的话,肯定会有问题。
在数据规模已经确定的情况下,你有多少 Executor 和每个 Executor 可分配多少内存 (在这个物理硬件已经确定的情况下),你必须清楚知道你的內存最多能够缓存多少数据;在 Shuffle 的过程中又使用了多少比例的缓存,这样对于算法的编写以及业务实现是至关重要的!!!
文章的后部份会介绍 Spark 2.x 版本 JVM 的内存使用比例,它被称之为 Spark Unified Memory,这是统一或者联合的意思,但是 Spark 没有用 Shared 这个字,因为 A 和 B 进行 Unified 和 A 和 B 进行 Shared 其实是两个不同的概念, Spark 在运行的时候会有不同类型的 OOM,你必须搞清楚这个 OOM 背后是由什么导致的。 比如说我们使用算子 mapPartition 的时候,一般会创建一些临时对象或者是中间数据,你这个时候使用的临时对象和中间数据,是存储在一个叫 UserSpace 里面的用户操作空间,那你有没有想过这个空间的大小会导致应用程序出现 OOM 的情况,在 Spark 2.x 中 Broadcast 的数据是存储在什么地方;ShuffleMapTask 的数据又存储在什么地方,可能你会认为 ShuffleMapTask 的数据是缓存在 Cache 中。这篇文章会介绍 JVM 在 Spark 1.6.X 以前和 2.X 版本对 Java 堆的使用,还会逐一解密上述几个疑问,也会简单介绍 Spark 1.6.x 以前版本在 Spark On Yarn 上内存的使用案例,希望这篇文章能为读者带出以下的启发:
- 了解 JVM 内存使用架构剖析
- 了解 JVM 在 Spark 1.6.x 以前和 Spark 2.x 中可以缓存多少数据
- 了解 Spark Unified Memory 的原理与机制还有它三大核心空间的用途
- 了解 Shuffle 在 Spark 1.6.x 以前和 Spark 2.x 中可以使用多少缓存
- 了解 Spark1.6.x 以前 on Yarn 对内存的使用
- 了解 在 Spark 1.6.x 以前和 Spark 2.x Shuffle 的参数配置
JVM 内存使用架构剖析
JVM 有很多不同的区,最开始的时候,它会通过类装载器把类加载进来,在运行期数据区中有 "本地方法栈","程序计数器","Java 栈"、"Java 堆"和"方法区"以及本地方法接口和它的本地库。从 Spark 的角度来谈代码的运行和数据的处理,主要是谈 Java 堆 (Heap) 空间的运用。
[下图是JVM 内存架构图]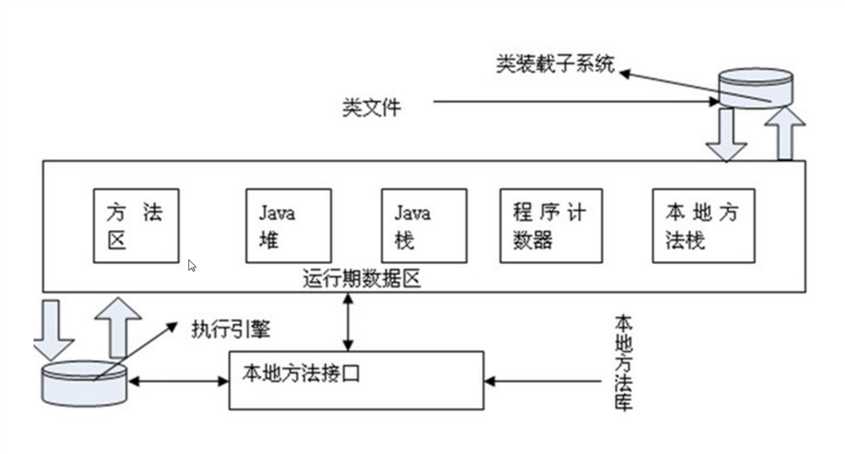
- 本地方法栈:这个是在迭归的时候肯定是至关重要的;
- 程序计数器:这是一个全区计数器,对于线程切换是至关重要的;
- Java 栈 (Stack):Stack 区属于线程私有,高效的程序一般都是并发的,每个线程都会包含一个 Stack 区域,Stack 区域中含有基本的数据类型以及对象的引用,其它线程均不能直接访问该区域;Java 栈分为三大部份:基本数据类型区域、操作指令区域、上下文等;
- Java 堆 (Heap):存储的全部都是 Object 对象实例,对象实例中一般都包含了其数据成员以及与该对象对应类的信息,它会指向类的引用一个,不同线程肯定要操作这个对象;一个 JVM 实例在运行的时候只有一个 Heap 区域,而且该区域被所有的线程共享;补充说明:垃圾回收是回收堆 (heap) 中内容,堆上才有我们的对象。
- 方法区:又名静态成员区域,包含整个程序的 class、static 成员等,类本身的字节码是静态的;它会被所有的线程共享和是全区级别的;
Spark 1.6.x 和 2.x 的 JVM 剖析
Spark JVM 到底可以缓存多少数据
下图显示的是Spark 1.6.x 以前版本对 Java 堆 (heap) 的使用情况,左则是 Storage 对内存的使用,右则是 Shuffle 对内存的使用,这叫 StaticMemoryManagement,数据处理以及类的实体对象都存放在 JVM 堆 (heap) 中。
[下图是 Spark 1.6x 以前版本对 JVM 堆 Storage 和 Shuffle 的使用分布]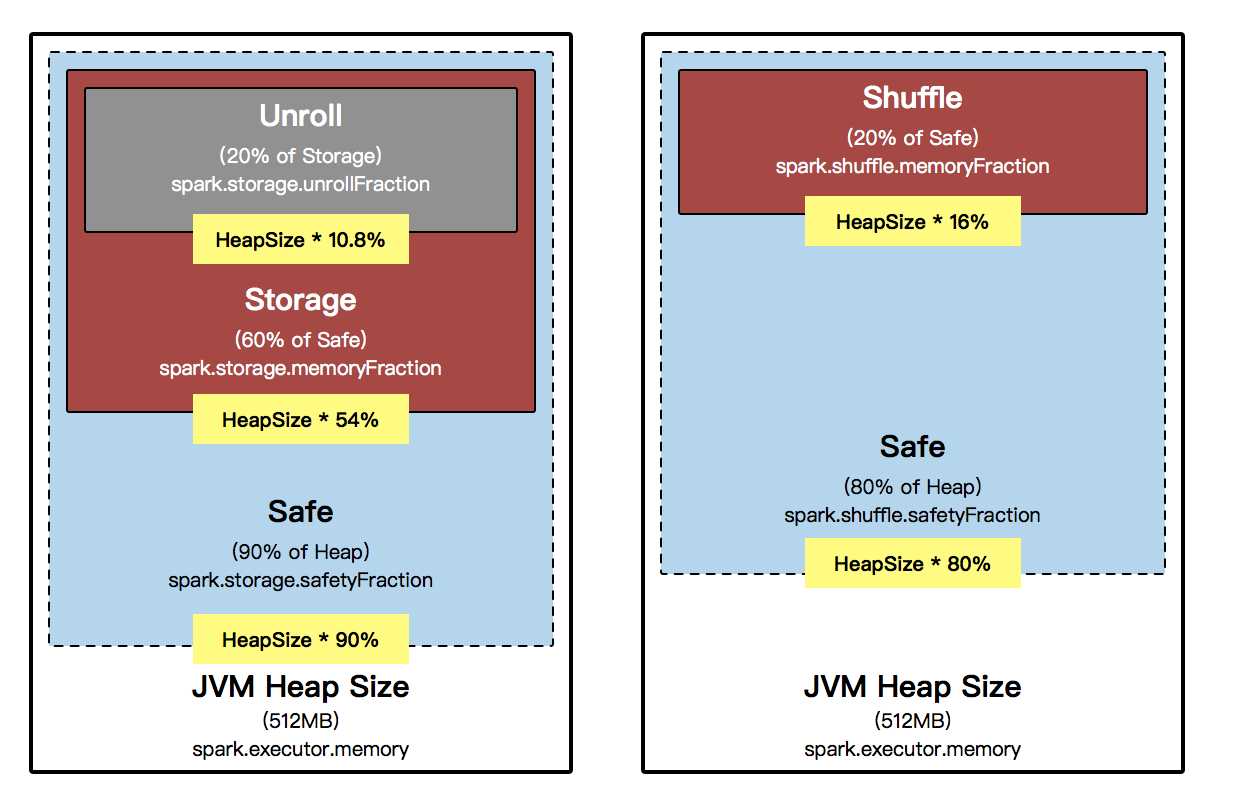
Spark 1.6.x 版本对 JVM 堆的使用
JVM Heap 默认情况下是 512MB,这是取决于 spark.executor.memory 的参数,在回答 Spark JVM 到底可以缓存多少数据这个问题之前,首先了解一下 JVM Heap 在 Spark 中是如何分配内存比例的。无论你定义了 spark.executor.memory 的内存空间有多大,Spark 必然会定义一个安全空间,在默认情况下只会使用 Java 堆上的 90% 作为安全空间,在单个 Executor 的角度来讲,就是 Heap Size x 90%。
埸景一:假设说在一个Executor,它可用的 Java Heap 大小是 10G,实际上 Spark 只能使用 90%,这个安全空间的比例是由spark.storage.safetyFaction 来控制的。(如果你内存的 Heap 非常大的话,可以尝试调高为 95%),在安全空间中也会划分三个不同的空间:一个是 Storage 空间、一个是 Unroll 空间和一个是 Shuffle 空间。
- 安全空间 (safe):计算公式是 spark.executor.memory x spark.storage.safetyFraction。也就是 Heap Size x 90%,在埸景一的例子中是 10 x 0.9 = 9G;
- 缓存空间 (Storage):计算公式是 spark.executor.memory x spark.storage.safetyFraction x spark.storage.memoryFraction。也就是 Heap Size x 90% x 60%;Heap Size x 54%,在埸景一的例子中是 10 x 0.9 x 0.6 = 5.4G;一个应用程序可以缓存多少数据是由 safetyFraction 和 memoryFraction 这两个参数共同决定的。
[下图是 StaticMemoryManager.scala 中的 getMaxStorageMemory 方法]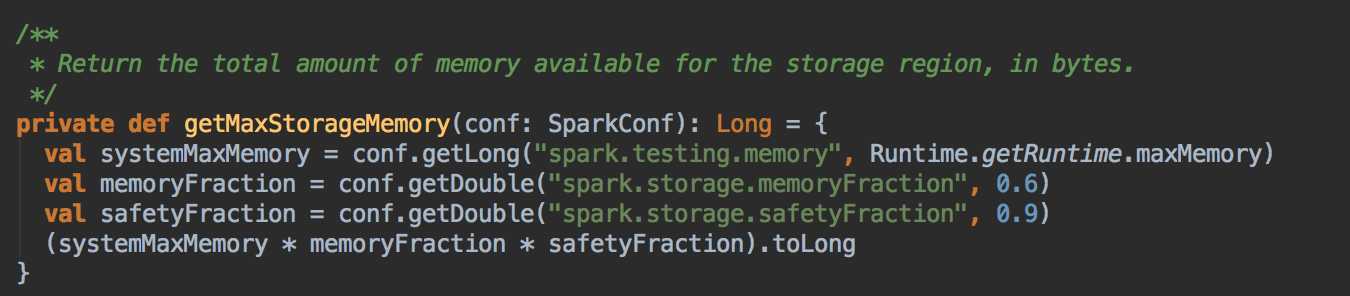
- Unroll 空间:Shuffle 空间:计算公式是 spark.executor.memory x spark.shuffle.memoryFraction x spark.shuffle.safteyFraction。在 Shuffle 空间中也会有一个默认 80% 的安全空间比例,所以应该是 Heap Size x 20% x 80%;Heap Size x 16%,在埸景一的例子中是 10 x 0.2 x 0.8 = 1.6G;从内存的角度讲,你需要从远程抓取数据,抓取数据是一个 Shuffle 的过程,比如说你需要对数据进行排序,显现在这个过程中需要内存空间。
- 计算公式是 spark.executor.memory x spark.storage.safetyFraction x spark.storage.memoryFraction x spark.storage.unrollFraction
也就是 Heap Size x 90% x 60% x 20%;Heap Size x 10.8%,在埸景一的例子中是 10 x 0.9 x 0.6 x 0.2 = 1.8G,你可能把序例化后的数据放在内存中,当你使用数据时,你需要把序例化的数据进行反序例化。
[下图是 StaticMemoryManager.scala 中的 maxUnrollMemory 变量]
- 对 cache 缓存数据的影响是由于 Unroll 是一个优先级较高的操作,进行 Unroll 操作的时候会占用 cache 的空间,而且又可以挤掉缓存在内存中的数据 (如果该数据的缓存级别是 MEMORY_ONLY 的话,否则该数据会丢失)。
- 计算公式是 spark.executor.memory x spark.storage.safetyFraction x spark.storage.memoryFraction x spark.storage.unrollFraction
[下图是 StaticMemoryManager.scala 中的 getMaxExecutionMemory 方法]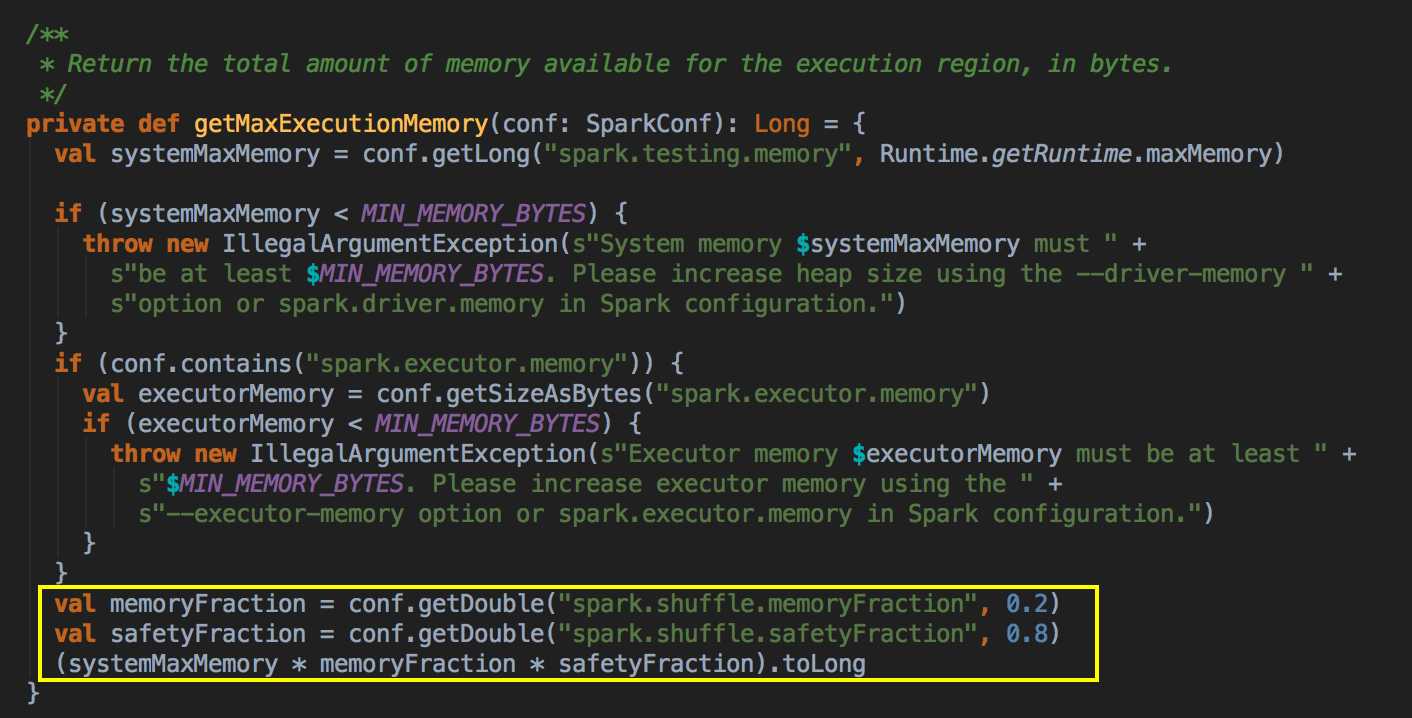
Spark Unified Memory 原理和运行机制
下图是一种叫联合内存 (Spark Unified Memeory),数据缓存与数据执行之间的内存可以相互移动,这是一种更弹性的方式,下图显示的是 Spark 2.x 版本对 Java 堆 (heap) 的使用情况,数据处理以及类的实体对象存放在 JVM 堆 (heap) 中。
[下图是 Spark 2.x 版本对 JVM 堆 Storage 和 Execution 的使用分布]
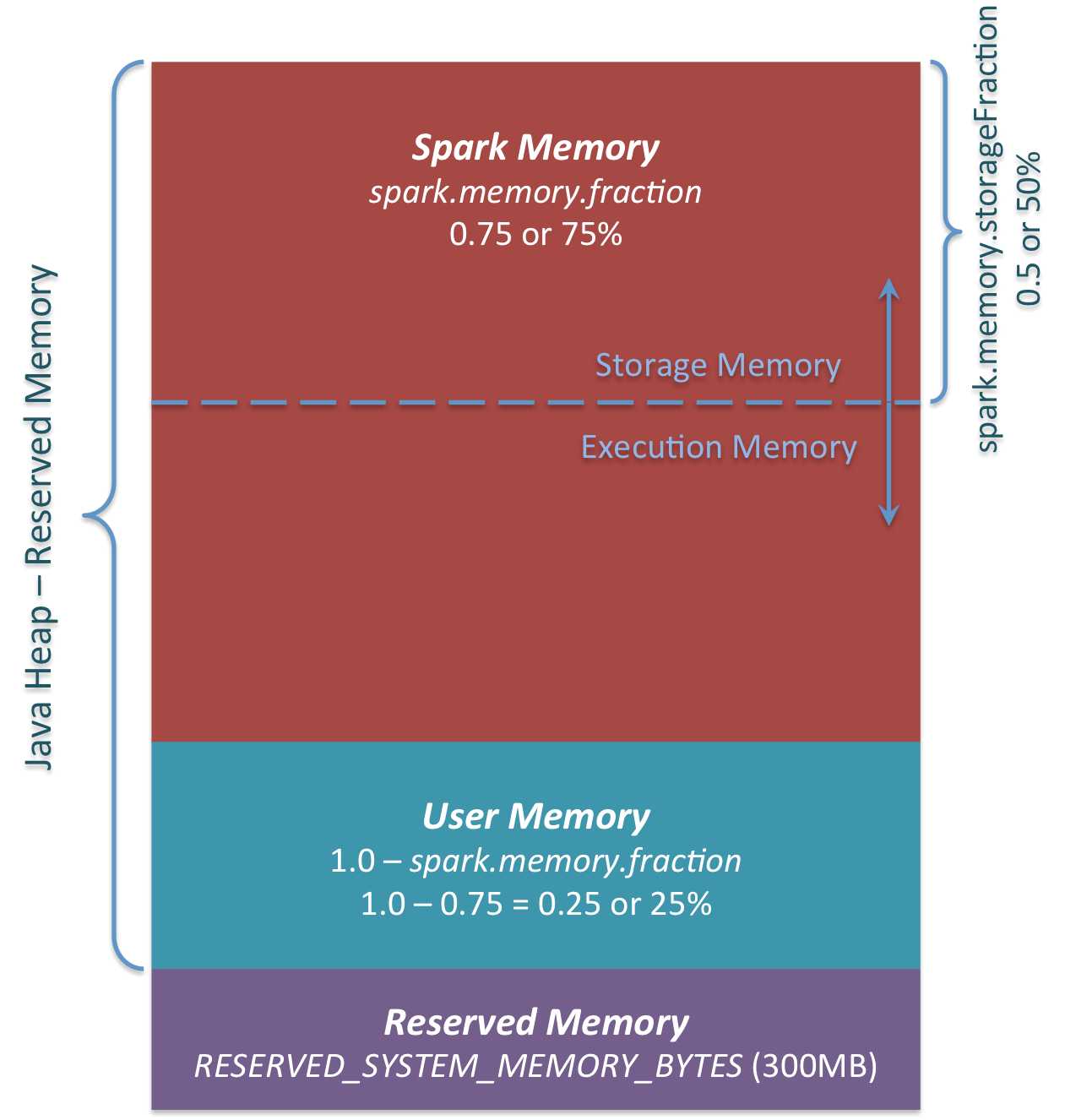
Spark 2.x 版本对 JVM 堆的使用
Spark 2.1.0 新型 JVM Heap 分成三个部份:Reserved Memory、User Memory 和 Spark Memory。
- Reserved Memory:默认都是300MB,这个数字一般都是固定不变的,在系统运行的时候 Java Heap 的大小至少为 Heap Reserved Memory x 1.5. e.g. 300MB x 1.5 = 450MB 的 JVM配置。一般本地开发例如说在 Windows 系统上,建义系统至少 2G 的大小。
[下图是 UnifiedMemoryManager.scala 中 UnifiedMemoryManager 伴生对象里的 RESERVED_SYSTEM_MEMORY_BYTES 参数]
SparkMemory空间默认是占可用 HeapSize 的 60%,与上图显示的75%有点不同,当然这个参数是可配置的!!
[下图是 UnifiedMemoryManager.scala 中 UnifiedMemoryManager 伴生对象里的 getMaxMemory 方法]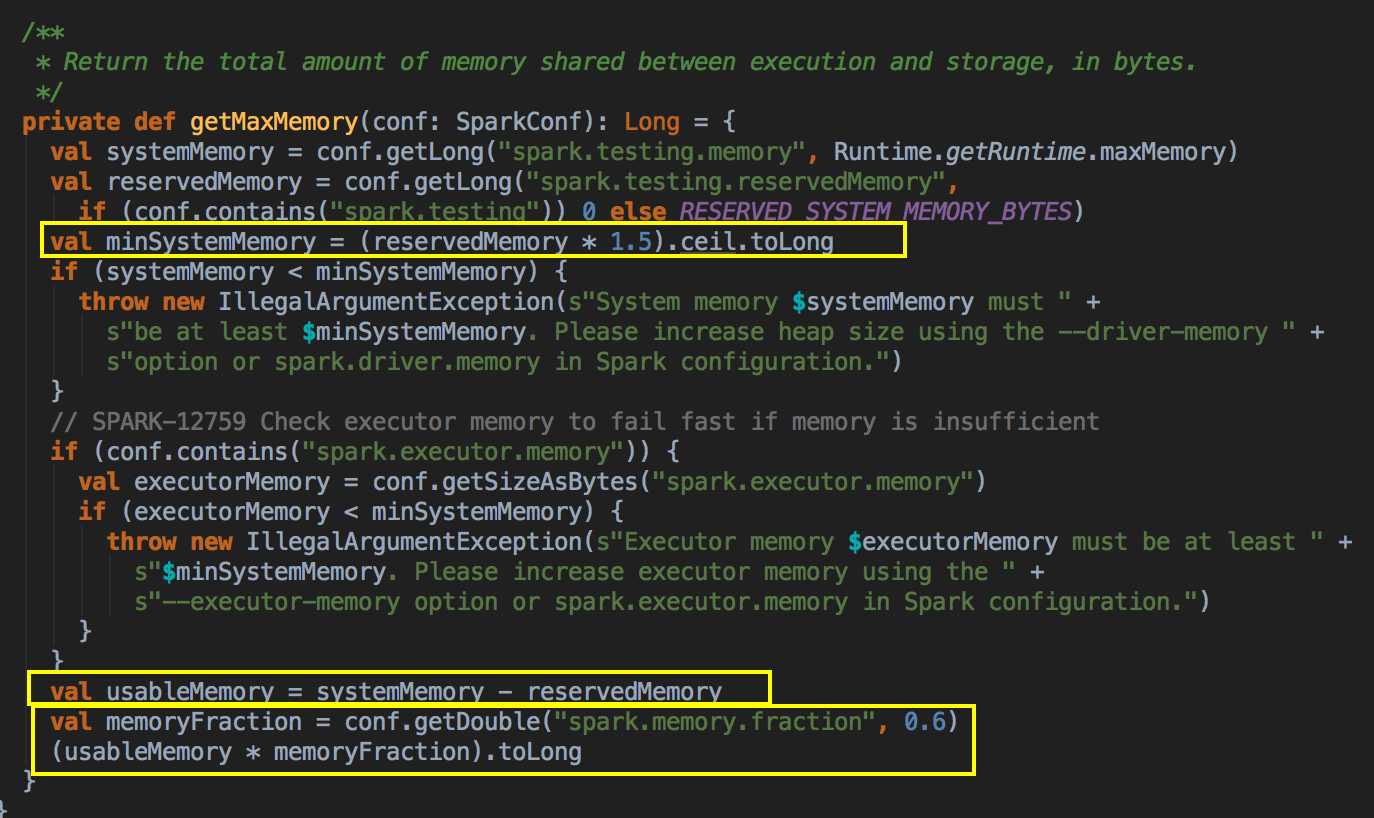
- User Memory:写 Spark 程序中产生的临时数据或者是自己维护的一些数据结构也需要给予它一部份的存储空间,你可以这么认为,这是程序运行时用户可以主导的空间,叫用户操作空间。它占用的空间是 (Java Heap - Reserved Memory) x 25%(默认是25%,可以有参数供调优),这样设计可以让用户操作时所需要的空间与系统框架运行时所需要的空间分离开。假设 Executor 有 4G 的大小,那么在默认情况下 User Memory 大小是:(4G - 300MB) x 25% = 949MB,也就是说一个 Stage 内部展开后 Task 的算子在运行时最大的大小不能够超过 949MB。例如工程师使用 mapPartition 等,一个 Task 内部所有算子使用的数据空间的大小如果大于 949MB 的话,那么就会出现 OOM。思考题:有 100个 Executors 每个 4G 大小,现在要处理 100G 的数据,假设这 100G 分配给 100个 Executors,每个 Executor 分配 1G 的数据,这 1G 的数据远远少于 4G Executor 内存的大小,为什么还会出现 OOM 的情况呢?那是因为在你的代码中(e.g.你写的应用程序算子)超过用户空间的限制 (e.g. 949MB),而不是 RDD 本身的数据超过了限制。
- Spark Memeory:系统框架运行时需要使用的空间,这是从两部份构成的,分别是 Storage Memeory 和 Execution Memory。现在 Storage 和 Execution (Shuffle) 采用了 Unified 的方式共同使用了 (Heap Size - 300MB) x 75%,默认情况下 Storage 和 Execution 各占该空间的 50%。你可以从图中可以看出,Storgae 和 Execution 的存储空间可以往上和往下移动。
定义:所谓 Unified 的意思是 Storgae 和 Execution 在适当时候可以借用彼此的 Memory,需要注意的是,当 Execution 空间不足而且 Storage 空间也不足的情况下,Storage 空间如果曾经使用了超过 Unified 默认的 50% 空间的话则超过部份会被强制 drop 掉一部份数据来解决 Execution 空间不足的问题 (注意:drop 后数据会不会丢失主要是看你在程序设置的 storage_level 来决定你是 Drop 到那里,可能 Drop 到磁盘上),这是因为执行(Execution) 比缓存 (Storage) 是更重要的事情。
[下图是 UnifiedMemoryManager.scala 中 UnifiedMemoryManager 伴生对象里的 apply 方法]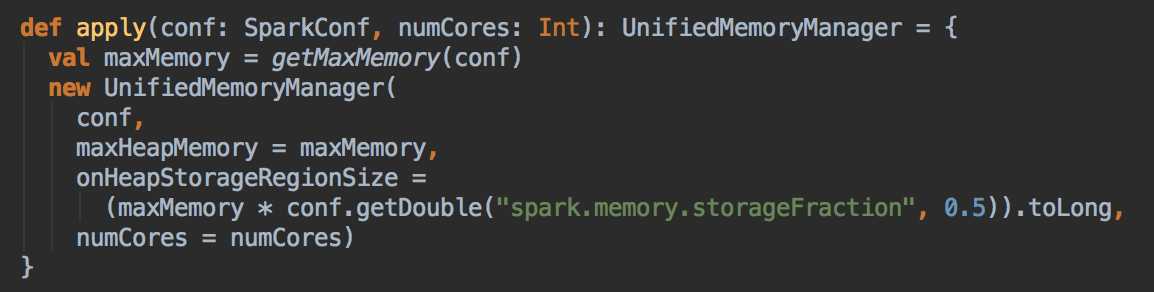
但是也有它的基本条件限制,Execution 向 Storage 借空间有两种情况:具体代码实现可以参考源码补充 : Spark 2.1.X 中 Unified 和 Static MemoryManager
[下图是 Execution 向 Storage 借空间的第一种情况]
第一种情况:Storage 曾经向 Execution 借了空间,它缓存的数据可能是非常的多,然后 Execution 又不需要那么大的空间 (默认情况下各占 50%),假设现在 Storage 占了 80%,Execution 占了 20%,然后 Execution 说自己空间不足,Execution 会向内存管理器发信号把 Storgae 曾经占用的超过 50%数据的那部份强制挤掉,在这个例子中挤掉了 30%;
[下图是 Execution 向 Storage 借空间的第二种情况]
第二种情况:Execution 可以向 Storage Memory 借空间,在 Storage Memory 不足 50% 的情况下,Storgae Memory 会很乐意地把剩馀空间借给 Execution。相反当 Execution 有剩馀空间的时候,Storgae 也可以找 Execution 借空间。 - Storage Memeory:相当于旧版本的 Storage 空间,在旧版本中 Storage 占了 54% 的 Heap 空间,这个空间会负责存储 Persist、Unroll 以及 Broadcast 的数据。假设 Executor 有 4G 的大小,那么 Storage 空间是:(4G - 300MB) x 75% x 50% = 1423.5MB 的空间,也就是说如果你的内存够大的话,你可以扩播足够大的变量,扩播对于性能提升是一件很重要的事情,因为它所有的线程都是共享的。从算子运行的角度来讲,Spark 会倾向于数据直接从 Storgae Memeory 中抓取过来,这也就所谓的内存计算。
- Execution Memeory:相当于旧版本的 Shuffle 空间,这个空间会负责存储 ShuffleMapTask 的数据。比如说从上一个 Stage 抓取数据和一些聚合的操作、等等。在旧版本中 Shuffle 占了 16% 的 Heap 空间。Execution 如果空间不足的情况下,除了选择向 Storage Memory 借空间以外,也可以把一部份数据 Spill 到磁盘上,但很多时候基于性能调优方面的考虑都不想把数据 Spill 到磁盘上。思考题:你觉得是 Storgae 空间或者是 Execution 空间比较重要呢?
Spark1.6.x 以前 on Yarn 计算内存使用案例
这是一张 Spark 运行在 Yarn 上的架构图,它有 Driver 和 Executor 部份,在 Driver 部份有一个内存控制参数,Spark 1.6.x 以前是spark.driver.memory,在实际生产环境下建义配置成 2G。如果 Driver 比较繁忙或者是经常把某些数据收集到 Driver 上的话,建义把这个参数调大一点。
图的左边是 Executor 部份,它是被 Yarn 管理的,每台机制上都有一个 Node Manager;Node Manager 是被 Resources Manager 管理的,Resources Manager 的工作主要是管理全区级别的计算资源,计算资源核心就是内存和 CPU,每台机器上都有一个 Node Manager 来管理当前内存和 CPU 等资源。Yarn 一般跟 Hadoop 藕合,它底层会有 HDFS Node Manager,主要是负责管理当前机器进程上的数据并且与HDFS Name Node 进行通信。
[下图是 Spark on Yarn 的架构图]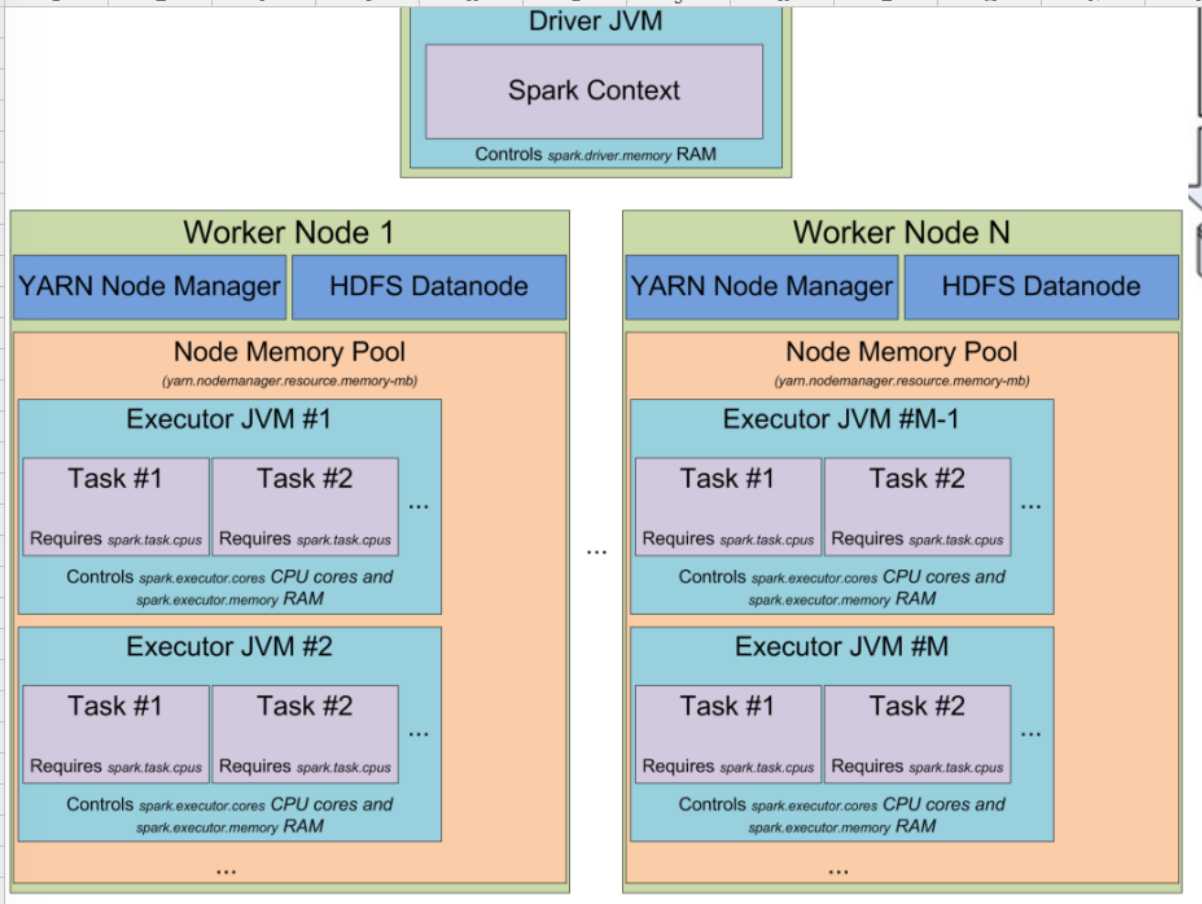
在每个节点上至少有两个进程,一个是 HDFS Data Node,负责管理磁盘上的数据,另外一个是 Yarn Node Manager,负责管理执行进程,在这两个 Node 的下面有两个 Executors,每个 Executor 里面运行的都是 Tasks。从 Yarn 的角度来讲,会配置每个 Executor 所占用的空间,以防止资源竞争,Yarn 里有一个叫 Node Memory Pool 的概念,可以配置 64G 或者是 128G,Node Memory Pool 是当前节点上总共能够使用的内存大小。
图中这两个 Executors 在两个不同的进程中 (JVM#1 和 JVM#2),里面的 Task 是并行运行的,Task 是运行在线程中,但你可以配置 Task 使用线程的数量,e.g. 2条线程或者是4条线程,但默认情况下都是1条线程去处理一个Task,你也可以用 spark.executor.cores 去配置可用的 Core 以及 spark.executor.memory 去配置可用的 RAM 的大小。
在 Yarn 上启动 Spark Application 的时候可以通过以下参数来调优:
- -num-executor 或者 spark.executor.instances 来指定运行时所需要的 Executor 的个数;
- -executor-memory 或者 spark.executor.memory 来指定每个 Executor 在运行时所需要的内存空间;
- -executor-cores 或者是 spark.executor.cores 来指定每个 Executor 在运行时所需要的 Cores 的个数;
- -driver-memory 或者是 spark.driver.memory 来指定 Driver 内存的大小;
- spark.task.cpus 来指定每个 Task 运行时所需要的 Cores 的个数;
场景一:例如 Yarn 集群上有 32 个 Node 来运行的 Node Manager,每个 Node 的内存是 64G,每个 Node 的 Cores 是 32 Cores,假如说每个 Node 我们要分配两个 Executors,那么可以把每个 Executor 分配 28G,Cores 分配为 12 个 Cores,每个 Spark Task 在运行的时候只需要一个 Core 就行啦,那么我们 32 个 Nodes 同时可以运行: 32 个 Node x 2 个 Executors x (12 个 Cores / 1) = 768 个 Task Slots,也就是说这个集群可以并行运行 768 个 Task,如果 Job 超过了 Task 可以并行运行的数量 (e.g. 768) 则需要排队。那么这个集群模可以缓存多少数据呢?从理论上:32 个 Node x 2 个 Executors x 28g x 90% 安全空间 x 60%缓存空间 = 967.68G,这个缓存数量对于普通的 Spark Job 而言是完全够用的,而实际上在运行中可能只能缓存 900G 的数据,900G 的数据从磁盘储存的角度数据有多大呢?还是 900G 吗?不是的,数据一般都会膨胀好几倍,这是和压缩、序列化和反序列化框架有关,所以在磁盘上可能也就 300G 的样子的数据。
总结
了解 Spark Shuffle 中的 JVM 内存使用空间对一个Spark应用程序的内存调优是至关重要的。跟据不同的内存控制原理分别对存储和执行空间进行参数调优:spark.executor.memory, spark.storage.safetyFraction, spark.storage.memoryFraction, spark.storage.unrollFraction, spark.shuffle.memoryFraction, spark.shuffle.safteyFraction。
Spark 1.6 以前的版本是使用固定的内存分配策略,把 JVM Heap 中的 90% 分配为安全空间,然后从这90%的安全空间中的 60% 作为存储空间,例如进行 Persist、Unroll 以及 Broadcast 的数据。然后再把这60%的20%作为支持一些序列化和反序列化的数据工作。其次当程序运行时,JVM Heap 会把其中的 80% 作为运行过程中的安全空间,这80%的其中20%是用来负责 Shuffle 数据传输的空间。
Spark 2.0 中推出了联合内存的概念,最主要的改变是存储和运行的空间可以动态移动。需要注意的是执行比存储有更大的优先值,当空间不够时,可以向对方借空间,但前提是对方有足够的空间或者是 Execution 可以强制把 Storage 一部份空间挤掉。Excution 向 Storage 借空间有两种方式:第一种方式是 Storage 曾经向 Execution 借了空间,它缓存的数据可能是非常的多,当 Execution 需要空间时可以强制拿回来;第二种方式是 Storage Memory 不足 50% 的情况下,Storgae Memory 会很乐意地把剩馀空间借给 Execution。
如果是你的计算比较复杂的情况,使用新型的内存管理 (Unified Memory Management) 会取得更好的效率,但是如果说计算的业务逻辑需要更大的缓存空间,此时使用老版本的固定内存管理 (StaticMemoryManagement) 效果会更好。
參考資料
资料来源来至
DT大数据梦工厂 大数据商业案例以及性能调优
[1] 第29课:彻底解密Spark 1.6.X以前Shuffle中JVM内存使用及配置内幕详情:Spark到底能够缓存多少数据、Shuffle到底占用了多少数据、磁盘的数据远远比内存小却还是报告内存不足?
[2] 第30课:彻底解密Spark 2.1.X中Shuffle中JVM Unified Memory内幕详情:Spark Unified Memory的运行原理和机制是什么?Spark JVM最小配置是什么?用户空间什么时候会出现OOM?Spark中的Broadcast到底是存储在什么空间的?ShuffleMapTask的使用的数据到底在什么地方?
[4] Spark new memory management
Spark源码图片取自于 Spark 2.1.0版本
参考:http://www.cnblogs.com/jcchoiling/p/6494652.html