一、三言片语Hadoop
Hadoop起源于谷歌的三篇论文:GFS、MapReduce、BigTable
hadoop擅长日志分析,facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。
Hadoop解决的问题:海量数据的存储(HDFS)、海量数据的分析(MapReduce)、资源管理调度(YARN)
2.x原生支持HA机制
二、HDFS分布式文件体统实现思想
它可以分布式存储海量的文件。把多台机器组成一个集群,这个集群通过一个元数据管理系统管理起来构成一个分布式系统,对于客户端来说完全感受不到分布式存储的细节,用户存储文件的抽象目录和分布式系统存储在元数据管理系统上一一对应。
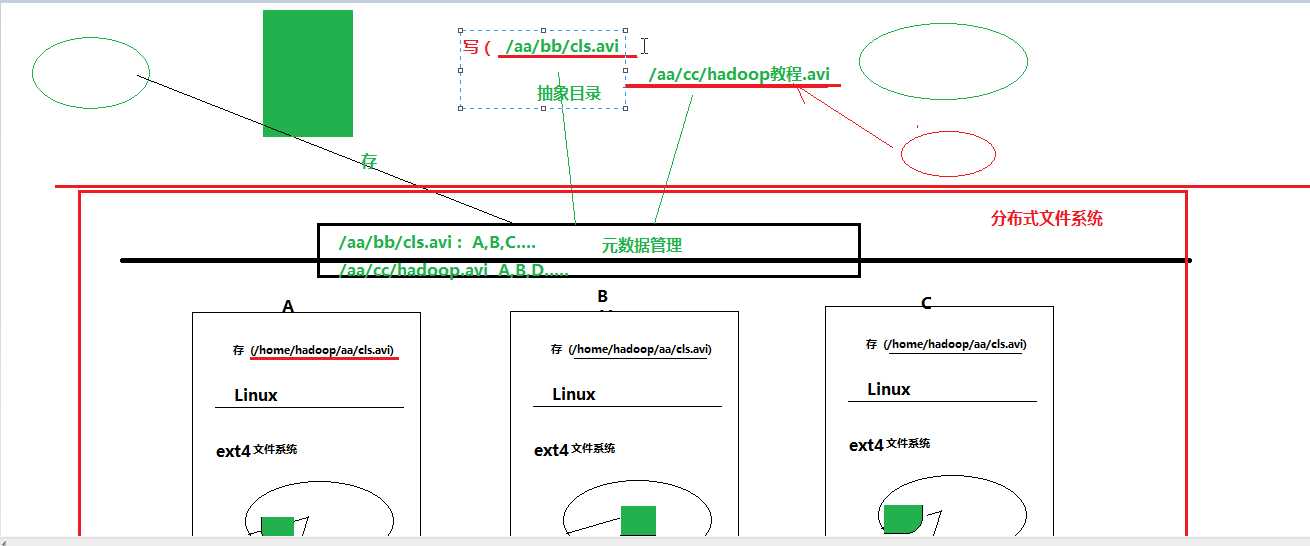
HDFS的基本思想:
1.客户的文件会被切分成若干块存储到集群的不同机器上
2.每一个文件切块在集群中会存储多个副本
3.hdfs为客户提供了一个抽象的文件目录树,访问文件只要指定文件路劲就可以,不用关心具体的分布式细节
4.集群中的节点应该分为两个角色:一种角色(namenode)负责管理目录树和元数据(抽象路劲和具体物理存储路径之间的映射),另一种角色(DataNode)负责管理客户存储的文件