标签:style blog http io os 使用 ar strong for
Insertion Sort
// 默认以渐增方式排序
template <class RandomAccessIterator>
void __insertion_sort(RandomAccessIterator first,
RandomAccessIterator last)
{
if (first == last) return;
// --- insertion sort 外循环 ---
for (RandomAccessIterator i = first + 1; i != last; ++i)
__linear_insert(first, i, value_type(first));
// 以上,[first,i) 形成一个子区间
}
template <class RandomAccessIterator, class T>
inline void __linear_insert(RandomAccessIterator first,
RandomAccessIterator last, T*)
{
T value = *last; // 记录尾元素
if (value < *first){ // 尾比头还小 (注意,头端必为最小元素)
copy_backward(first, last, last + 1); // 将整个区间向右移一个位置
*first = value; // 令头元素等于原先的尾元素值
}
else // 尾不小于头
__unguarded_linear_insert(last, value);
}
template <class RandomAccessIterator, class T>
void __unguarded_linear_insert(RandomAccessIterator last, T value)
{
RandomAccessIterator next = last;
--next;
// --- insertion sort 内循环 ---
// 注意,一旦不再出现逆转对(inversion),循环就可以结束了
while (value < *next){ // 逆转对(inversion)存在
*last = *next; // 调整
last = next; // 调整迭代器
--next; // 左移一个位置
}
*last = value; // value 的正确落脚处
}
Quick Sort
// 返回 a,b,c之居中者
template <class T>
inline const T& __median(const T& a, const T& b, const T& c)
{
if (a < b)
if (b < c) // a < b < c
return b;
else if (a < c) // a < b, b >= c, a < c --> a < b <= c
return c;
else // a < b, b >= c, a >= c --> c <= a < b
return a;
else if (a < c) // c > a >= b
return a;
else if (b < c) // a >= b, a >= c, b < c --> b < c <= a
return c;
else // a >= b, a >= c, b >= c --> c<= b <= a
return b;
}
Partitioning(分割)
Partitioning
template <class RandomAccessIterator, class T>
RandomAccessIterator __unguarded_partition(
RandomAccessIterator first,
RandomAccessIterator last,
T pivot)
{
while(true){
while (*first < pivot) ++first; // first 找到 >= pivot的元素就停
--last;
while (pivot < *last) --last; // last 找到 <=pivot
if (!(first < last)) return first; // 交错,结束循环
// else
iter_swap(first,last); // 大小值交换
++first; // 调整
}
}
Heap Sort
// paitial_sort的任务是找出middle - first个最小元素。
template <class RandomAccessIterator>
inline void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last)
{
__partial_sort(first, middle, last, value_type(first));
}
template <class RandomAccessIterator,class T>
inline void __partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last, T*)
{
make_heap(first, middle); // 默认是max-heap,即root是最大的
for (RandomAccessIterator i = middle; i < last; ++i)
if (*i < *first)
__pop_heap(first, middle, i, T(*i), distance_type(first));
sort_heap(first,middle);
}
Intro Sort
template <class RandomAccessIterator>
inline void sort(RandomAccessIterator first,
RandomAccessIterator last)
{
if (first != last){
__introsort_loop(first, last, value_type(first), __lg(last-first)*2);
__final_insertion_sort(first,last);
}
}
// __lg()用来控制分割恶化的情况
// 找出2^k <= n 的最大值,例:n=7得k=2; n=20得k=4
template<class Size>
inline Size __lg(Size n)
{
Size k;
for (k = 0; n > 1; n >>= 1)
++k;
return k;
}
// 当元素个数为40时,__introsort_loop的最后一个参数
// 即__lg(last-first)*2是5*2,意思是最多允许分割10层。
const int __stl_threshold = 16;
template <class RandomAccessIterator, class T, class Size>
void __introsort_loop(RandomAccessIterator first,
RandomAccessIterator last, T*,
Size depth_limit)
{
while (last - first > __stl_threshold){ // > 16
if (depth_limit == 0){ // 至此,分割恶化
partial_sort(first, last, last); // 改用 heapsort
return;
}
--depth_limit;
// 以下是 median-of-3 partition,选择一个够好的枢轴并决定分割点
// 分割点将落在迭代器cut身上
RandomAccessIterator cut = __unguarded_partition
(first, last, T(__median(*first,
*(first + (last - first)/2),
*(last - 1))));
// 对右半段递归进行sort
__introsort_loop(cut,last,value_type(first), depth_limit);
last = cut;
// 现在回到while循环中,准备对左半段递归进行sort
// 这种写法可读性较差,效率也并没有比较好
}
}
template <class RandomAccessIterator>
void __final_insertion_sort(RandomAccessIterator first,
RandomAccessIterator last)
{
if (last - first > __stl_threshold){
// > 16
// 一、[first,first+16)进行插入排序
// 二、调用__unguarded_insertion_sort,实质是直接进入插入排序内循环,
// *参见Insertion sort 源码
__insertion_sort(first,first + __stl_threshold);
__unguarded_insertion_sort(first + __stl_threshold, last);
}
else
__insertion_sort(first, last);
}
template <class RandomAccessIterator>
inline void __unguarded_insertion_sort(RandomAccessIterator first,
RandomAccessIterator last)
{
__unguarded_insertion_sort_aux(first, last, value_type(first));
}
template <class RandomAccessIterator, class T>
void __unguarded_insertion_sort_aux(RandomAccessIterator first,
RandomAccessIterator last,
T*)
{
for (RandomAccessIterator i = first; i != last; ++i)
__unguarded_linear_insert(i, T(*i));
}
if (last - first > __stl_threshold){ // > 16
...
...
__introsort_loop(cut,last,value_type(first), depth_limit);
__introsort_loop(first,cut,value_type(first), depth_limit);
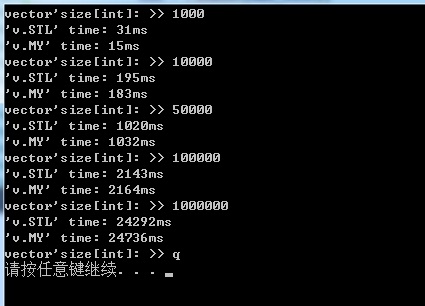
标签:style blog http io os 使用 ar strong for
原文地址:http://www.cnblogs.com/lhmily/p/3976517.html