一、消息分发
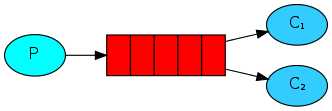
RabbitMQ中的消息都只能存储在Queue中,生产者(下图中的P)生产消息并最终投递到Queue中,消费者(下图中的C)可以从Queue中获取消息并消费。

多个消费者可以订阅同一个Queue,这时Queue中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理。
启动3个消费者
生产者依次生成3条消息
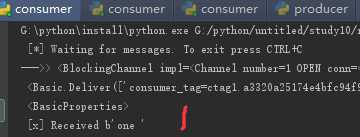
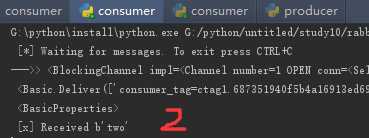
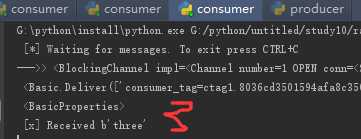
可见3条消息分别被3个消费者获取,所以RabbitMQ是采用轮询机制将消息队列Queue中的消息依次发给不同的消费者
二、消息确认(Message Acknowledgment)
在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失。为了避免这种情况发生,我们可以要求消费者在消费完消息后发送一个回执给RabbitMQ,RabbitMQ收到消息回执(Message acknowledgment)后才将该消息从Queue中移除;如果RabbitMQ没有收到回执并检测到消费者的RabbitMQ连接断开,则RabbitMQ会将该消息发送给其他消费者(如果存在多个消费者)进行处理。这里不存在timeout概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的RabbitMQ连接断开。
如何来实现呢?只需要将consumer消费者端中 no_ack = True去掉就行了

no_ack 就 no acknowlegment的意思,这个参数会导致RabbitMQ并不关心消费者有没有处理完成,可能在消费者获取消息后就将该消息从Queue中移除。去掉这个参数,如果在消费者执行过程当初出现了意外(宕机),RabbitMQ没有收到消息回执,就会发送给其他消费者执行。
修改consumer端
def callback(ch, method, properties, body):
print(‘--->>‘, ch, ‘\n‘, method, ‘\n‘, properties)
time.sleep(30) # 让消费者处理的时间长一点,可以用来模拟运行中断开的情况
print(" [x] Received %r" % body)
# ch: 声明的管道channel对象内存地址
#
channel.basic_consume(callback, # 如果收到消息就调用callback函数来处理消息
queue=‘hello‘,
# no_ack=True
)
运行3个消费者,接收生产者的数据,依次关闭消费者1和消费者2,最后RabbitMQ中的消息还是会被消费者3处理。