标签:style blog http color io os 使用 ar strong
这个网页的目的是帮助你理解怎么样在微软FAT32文件系统下取得数据,处理的硬盘的大小通常在500M到几百G之间。FAT是一个相对简单和纯净的文件系统。大多数文件系统都支持FAT,包括Linux和MacOS。所以也是需要访问硬盘的底层固件项目的常用文件系统。FAT16和FAT12是适用于小硬盘的小文件系统。这个网页将只重点介绍FAT32,和简单地比较一下他们的不同之处。
但是,这个网页的内容故意掩盖了很多细节和省略了很多这个文件系统出色的地方,为了使得本文更加简单,令之前没有接触过FAT32文件系统的读者更容易理解。
设备上的第一个扇区,叫做主引导记录(Master Boot Record - MBR)。你可以通过读LBA=0这个地址得到。在一些行的项目中,你可以不用担心怎么通过CHS模式读写设备,LBA只是把扇区从0开始按顺序排列起来而已,他会更加简单。所有的IDE设备都支持通过LBA读写扇区。而且,所有的IDE设备的扇区都是512字节。现在Mincrosoft的操作系统提到过使用更大的扇区,但是设备依然是使用每个扇区512个字节,微软只是把多个扇区当成一个扇区来看而已。本文以下的内容都只涉及512字节扇区的LAB地址。
记录在主引导记录(MBR)最开始的446个字节的代码是用来启动电脑的。他后面紧跟着的64个字节是分区表,然后最后两个字节总是0x55和0xAA。一个看看这个扇区是不是主引导记录的方法就是看第一个扇区最后两个字节是不是0x55和0xAA。

图1: 主引导记录(MBR)的第一个扇区
主引导记录(MBR)只能描述4个分区。一个叫“逻辑分区”(extended partitioning)的技术可以允许更多的分区。这种技术经常在多于两个分区时使用。逻辑分区在主引导记录里面看起来就和普通分区一样,只是这个分区的第一个扇区也存放着一个分区表。由于简单起见,我们不介绍逻辑分区的内容(暂时把逻辑分区重新分配格式化掉……)。最常见的方案就是之分出一个分区,把剩下的234分区空出来。
每一个分区记录只有16字节,好消息是在多数情况下你可以忽略其中的很多东西。第5个字节是“类型代码”(Type Code),这个代码告诉我们分区的文件系统是什么。第9到第12个字节包含了LBA格式的分区开始扇区地址。
![]()
图2: 16字节的分区入口(partition entry)
你只需要看看每个分区的类型代码是不是0x0B和0x0C(这两个代码都代表FAT32)和LBA格式的开始地址就可以知道这个分区在设备上的位置。
至于“扇区数量”(Number of Sectors)区域制定了扇区的长度,防止你把数据卸载这个扇区之外的地方去了。但是,分区的FAT32文件系统自身就含有文件系统大小的信息,所以这个主引导记录里的“扇区数量”区域是多余的。很多Microsoft的操作系统忽略这个区域值,反而依赖与嵌入在每个分区开头第一个扇区里所记录的信息。(没错,我曾经修改过这个值,虽然是无意的)。Linux会检测“扇区数量”这个值,来适当地防止访问超出分区部分的读写操作。大多数的底层固件程序可能会忽略这个值。
“启动标志”(Boot Flag),“CHS起始”(CHS Begin),和“CHS结束”(CHS End)这3个区域我们忽略他们(用LBA代替了CHS)。
读一个FAT32文件系统的第一步是读他的第一个扇区,叫卷ID(Volume ID)。卷ID是用从分区表中LBA起始(LBA Begin)区域中的地址找到的。从这节起,你将会提取一些信息,这些信息会告诉你文件在FAT32文件系统中文件的分布。
你可能会找到Microsoft的“描述列表”(specification lists)。FAT32的卷ID(Volume ID)和版本较老的FAT16、FAT12比起来有些小地方不一样。幸运的是,如果只是编写些功能简单的代码,并不需要用到这么多信息。只有4个变量是必须的,以及另外3个用于确认里面的值是否是对应的值。
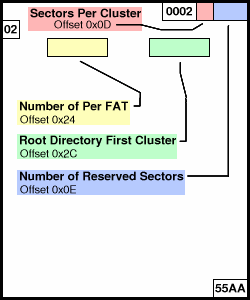
图4: FAT32卷ID, 重要区域
|
区域 |
微软的表述 |
偏移地址 |
大小 |
值 |
|
Bytes Per Sector |
BPB_BytsPerSec |
0x0B |
16 Bits |
Always 512 Bytes |
|
Sectors Per Cluster |
BPB_SecPerClus |
0x0D |
8 Bits |
1,2,4,8,16,32,64,128 |
|
Number of Reserved Sectors |
BPB_RsvdSecCnt |
0x0E |
16 Bits |
Usually 0x20 |
|
Number of FATs |
BPB_NumFATs |
0x10 |
8 Bits |
Always 2 |
|
Sectors Per FAT |
BPB_FATSz32 |
0x24 |
32 Bits |
Depends on disk size |
|
Root Directory First Cluster |
BPB_RootClus |
0x2C |
32 Bits |
Usually 0x00000002 |
|
Signature |
(none) |
0x1FE |
16 Bits |
Always 0xAA55 |
原表格:
|
Field |
Microsoft‘s Name |
Offset |
Size |
Value |
|
Bytes Per Sector |
BPB_BytsPerSec |
0x0B |
16 Bits |
Always 512 Bytes |
|
Sectors Per Cluster |
BPB_SecPerClus |
0x0D |
8 Bits |
1,2,4,8,16,32,64,128 |
|
Number of Reserved Sectors |
BPB_RsvdSecCnt |
0x0E |
16 Bits |
Usually 0x20 |
|
Number of FATs |
BPB_NumFATs |
0x10 |
8 Bits |
Always 2 |
|
Sectors Per FAT |
BPB_FATSz32 |
0x24 |
32 Bits |
Depends on disk size |
|
Root Directory First Cluster |
BPB_RootClus |
0x2C |
32 Bits |
Usually 0x00000002 |
|
Signature |
(none) |
0x1FE |
16 Bits |
Always 0xAA55 |
在检查三个区域,确认文件系统是使用512字节扇区,2个FAT,和有正确标志(signature)之后,或许你会想把这3个从主引导区的变量值和卷ID归纳成四个简单的数字。这个数字拥有访问FAT32文件系统所需的必要信息。
下面是用C语言写的公式:
1 (unsigned long)fat_begin_lba = Partition_LBA_Begin + Number_of_Reserved_Sectors; 2 3 (unsigned long)cluster_begin_lba = Partition_LBA_Begin + Number_of_Reserved_Sectors + (Number_of_FATs * Sectors_Per_FAT); 4 5 (unsigned char)sectors_per_cluster = BPB_SecPerClus; 6 7 (unsigned long)root_dir_first_cluster = BPB_RootClus;
就像这样,需要的信息大多数时候只是指明第一个簇的位置和FAT(文档分配表)。你需要记住簇的大小,以及根文件夹(Root Directory)在哪里(它的地址),而其他信息经常是不需要用到的(至少对于简单的读取文件操作来说不需要)。
如果你那这些信息与Microsoft的描述信息相比较的话,你应该注意到两个不同的地方。他们缺少了“RootDirSectors”(根文件夹扇区),因为FAT32储存文件夹和子文件夹的方式与储存文件的方式是一样的,所以在FAT32中“RootDirSectors”(根文件夹扇区)总是0。而FAT16和FAT12需要经过额外的步骤来计算出根文件夹(Root Directory)的特定地址。
Microsoft的公式中没有给出“Partition_LAB_Begin”这一项。他们的这些公式都依赖于文件系统开头的部分,不过这点他们没有很明确地说出来而已。你需要在主引导记录中找到“Partition_LAB_Begin”这一项,然后计算出IDE接口正确的LBA地址。因为设备是从LBA=0的MBR开始计算,而不是从卷ID开始计算的。没有加上Partition_LBA_Begin(分区起始地址)是开发者经常犯的错误。所以,特别当你在使用Microsoft的描述方式时,不要忘记加上正确的LBA地址。
本文剩下的部分将会经常提到“fat_begin_lba”,“cluster_begin_lba”,“sectors_per_cluser”,和“root_dir_first_cluster”,而不是主引导记录(MBR)中和卷ID(Volume ID)中的特定的区域。原因是,你不再需要主引导记录(MBR)中和卷ID(Volume ID)中的细节,能最简单地使用这些数值来计算。
FAT32文件系统的布局非常简单。第一个扇区总是卷ID(Volume ID)。在中和卷ID之后总是跟着一些未被使用的保留扇区(reserved sectors)。在保留扇区后面是两个FAT(File Allocation Table,文件分配表)。剩下的区域被文件系统以“簇”为单位分配,在最后的簇后面还可能会出现一些未使用的区域。
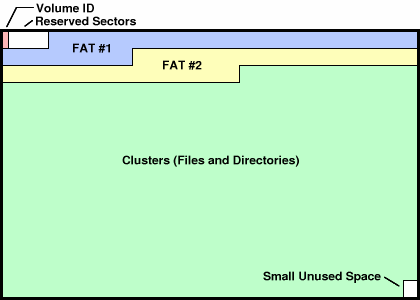
图5: FAT32文件系统整体布局(一个分区)
这些用来存放所有文件和文件夹的“簇”占据着硬盘大部分的空间。簇是从2号开始的,所以没有0号和1号簇。如果你需要访问特定的簇,你需要用以下这条公式吧簇号(cluster number)转换为IDE设备的LBA地址:
lba_addr = cluster_begin_lba + (cluster_number-2) * sectors_per_cluster;
通常,簇的大小最少为4K(8个扇区),8K,16K和32K的簇很少使用。一些新版本的Microsoft Windows系统允许使用更大的簇,而处于对效率的考虑,扇区(簇?)的大小都是512字节的倍数。Microsoft指出,FAT32描述的文件系统最大的簇大小为32K。
刚开始时,你只知道第一个簇和根目录(Root directory)的地址。读取目录将可以知道其他文件和目录的名字和起始簇在哪里。很重要的一点是:目录仅仅告诉你怎么找到文件和子目录的起始的簇在哪里。你还需要从目录中获取诸如文件长度、修改时间、文件属性等其他种类的信息。但是目录只会告诉你文件在哪里。要得到起始簇以外的信息,你需要用到FAT(文件分配表)。但首先你需要找到这些文件是从哪里开始的。
在这节里面,我们只会简短地看看目录,知道哪些是找到文件所必须的。然后我们将看看怎么通过文件分配表(FAT)来找到剩下的文件。最后我们将来回头看看关于目录结构的细节。
目录数据被组织成32个字节的记录。这很好,因为每一个扇区刚好可以保存16条记录,没有记录会卡在扇区与扇区中间。这里有四种32个字节的目录记录:
未使用的目录记录可能是被删除的文件的记录,它的第一个字节被0xE5覆盖掉,当有新文件被创建时就可以重新使用这条记录。目录的最后是一条开头第一个字节为0的记录。所有其他的记录都是以非0开头的,所以可以很容易的察觉到你什么时候到达了目录的结尾。
凡是不是以0x00和0xE5开头的记录都是目录的数据,这些记录的格式可以通过检查它的属性字(Attrib byte)来判定。现在,我们将只考虑“旧8.3短文件名格式”(old 8.3 format)的一般目录记录。在FAT32中,所有的文件盒子目录都有短文件名(short name),即使用户赋予了这个文件一个长文件名。所以你不需要解释长文件名记录就可以访问到所有的文件(当你的代码简单到需要忽略他们)。这是一般目录记录的格式:

图6: 32字节目录结构,短文件名格式
|
区域 |
Microsoft的描述 |
偏移地址 |
地址 |
|
Short Filename |
DIR_Name |
0x00 |
11 Bytes |
|
Attrib Byte |
DIR_Attr |
0x0B |
8 Bits |
|
First Cluster High |
DIR_FstClusHI |
0x14 |
16 Bits |
|
First Cluster Low |
DIR_FstClusLO |
0x1A |
16 Bits |
|
File Size |
DIR_FileSize |
0x1C |
32 Bits |
属性字(Attrib byte)通过6bits来决定,具体如下表所示。大多数程序框架都是通过检查属性字来决定这32个字节是一般目录记录还是长文件名数据,以及决定他是一个普通文件还是子目录。长文件名记录会把最后4位置为1。普通的文件很少会把这最后四个位全部置为1。
|
Attrib Bit |
功能 |
长文件名记录时 |
注释 |
|
0 (LSB) |
Read Only |
1 |
不应该位可写入 |
|
1 |
Hidden |
1 |
不应该在目录中显示 |
|
2 |
System |
1 |
是系统文件 |
|
3 |
Volume ID |
1 |
文件名是卷ID(Volume ID) |
|
4 |
Directory |
x |
是一条子目录记录 |
|
5 |
Archive |
x |
在最后一次备份后已经被修改过 |
|
6 |
Ununsed |
0 |
此位应该常为0 |
|
7 (MSB) |
Ununsed |
0 |
此位应该常为0 |
剩下的区域就相对简单和直接。开头11字节是短文件名(旧8.3格式-old 8.3 format)。扩展功能允许使用其后面的3个字节。如果文件名的长度小于8字节,剩下的字节就会用0x20填充。起始簇号码被分为两个16位来储存,以及最后4个字节用来储存文件的大小。这两者的储存都是通过字节来存取,低位在前,高位在后。起始簇号码告诉我们文件的数据从硬盘的哪里开始,文件大小告诉我们这个文件有多长。由于硬盘的实际空间都是通过整数个簇来分配的,所以文件大小会让你知道其后的多少个簇存放着文件的数据。
目录的入口告诉你文件或子目录的起始簇在硬盘的什么地方,然后就理所当然的从卷ID中的根目录中找到了第一个簇。对于小文件和目录(大小在一个簇以内),你能从文件分配表(FAT)得到的信息只是:这个文件不占用更多的簇。要访问剩下超过一个簇的文件时,你就需要使用文件分配表(FAT)。FAT32这个名字所代表的含义是表格中每一个入口(entry)都是32位的。在FAT16和FAT12中,入口时16和12位的。FAT16和FAT12的工作方式与FAT32相同(只是令人讨厌的是12位的入口经常对齐不了扇区的边界,但是16和32位的入口是不会超出扇区边界的)。我们将只介绍FAT32。
文件分配表是一个很大的32位整数序列。这个序列中的每一个入口(32位)在序列中的位置对应簇的号码,而每个入口中的内容储存着的是该文件下一个簇的位置。文件分配表的目的就是在你知道目前簇的位置时,告诉你下一个簇的位置在哪里。每一个扇区中包含有128个这种32位的整数,所以可以相对简单地知道下一个簇的位置。当前所在的入口中,第7到31位告诉你下一个入口在FAT中的那个扇区,剩下的0到6位告诉你下一个入口是这个扇区中128个入口的哪一个(如果所有位都置为1,说明这是文件的结尾)。
这是一个虚拟的例子,里面有三个小文件和根目录,他们都分布在第一个簇的附近(下图中,文件需要的所有簇号码画在FAT图的旁边)。注意到,下面这个根目录占用了5个簇,但是却悲剧的仅仅含有三个文件。这里只是想展示一下怎么样链式的寻找到簇。但是值得注意的是,如果是小的根目录(只占一个簇),表中第2个入口中的内容将是“FFFFFFFF”(在卷ID中包含了根目录簇的首地址),而不是通过“00000009”号到达其他的簇。然而,当根目录有很多文件的情况下,根目录会占用几个簇,但是这几个簇很少会连在一起,毕竟在你存入更多的文件之前,这个根目录还是一个只占用一个簇的小目录。那么在记住这些要点后,我们来看看简单的例子:

图7: FAT32扇区,根目录和三个文件的簇链
在这个例子中,通过卷ID的信息我们知道根目录从2号簇开始。在FAT的第2个位置里面的数字式9,所以下一个是9号簇。像这样,簇A,B和11保存了根目录剩下的数据。在位置11的数字“FFFFFFFF”表示这里是根目录的最后一个簇。但是你的代码可能不会去读地11个位置,因为你将会找到一个目录结束标记(end-of-directory marker)(开头32个字节全为0)。就这样,这个文件系统就含有大小为一个簇的小型根目录,而且在读取目录时不需要使用FAT,因为只有一个簇。但是如果你在这个簇中没有发现目录结束标记,那么就必须通过FAT来寻找剩下的簇了。
同样的,这里显示了三个文件。在所有情况下,FAT都没有指出哪个是文件的第一个簇,所以必须从目录中提取文件的首地址,然后通过FAT来访问剩下的簇。分配给文件的簇的总字节数必须大于目录记录中文件大小区域指出的文件大小。除非文件的大小不是簇的整数倍的话,否则最后一个簇的末尾就会有一部分未使用的空间。文件大小是0的文件将不会分配簇,在目录记录中的簇数量应该为0。文件大小只占用一个簇的文件在FAT中对应簇的内容为“FFFFFFFF”表示已经到文件末尾。
便捷提示:一个能使代码尽可能简单的方法是是的根目录非常小(少量文件,只用8.3短文件名),避免出现子目录,以及在电脑上运行整理磁盘碎片程序。这样,根目录能在一个簇中找到,然后每个文件占据着地址连续的簇。虽然这种实现的功能非常有限,但是这样你就可以不使用文件分配表了。
更具Microsoft的描述,簇号码其实只占28位,高四位是保留的。你可以在把这些保留的位清零。同样的,文件结束号码(end-of-file number)实际上是所有比0xFFFFFFF8大的数,但是实际上通常使用0xFFFFFFFF。FAT中为全0的标记是自由的位置。同样的,请记住在内存中簇号码是先储存他们的低字节(低地址对低地址)(图7中使用的格式是为了便于我们阅读,但是他们实际上市先储存低字节的-stored LSB first)。所以其实在内存中,FAT中二号簇实际上在二进制编码器中会写成“90000000”,低字节在前。
好消息是,对于固件开发者来说使用FAT是很简单的。但是,FAT的简单导致的大量计算往往也是起作为一个通用文件系统的弱点。例如,为了向文件增加数据,文件系统必须读便整个簇链。在文件中任意位置中定位也需要大量的读取FAT。处于比较的目的,Unix文件系统使用树状结构。其中的簇(也叫作“区块”)会拥有完整的区块列表(在unix哲学中被叫做“inode”)或者拥有另一个包含着inode的区块。制这种方式下,定位一个硬盘中的任意一个区块只需要读取1,2或者3个inode。FAT的另外可以通过缓存来缓解的缺点在于,它数据的物理分布会集中在磁盘的“开头”,而不是分布式储存的。Unix基于inode(inode-based)的文件系统会把inode区块均匀地分布在数据区块之间,然后把数据区块定位在inode区块附近。
原作者就写到这里了,剩下的这些部分就要靠读者们写了。
翻译原文:https://www.pjrc.com/tech/8051/ide/fat32.html
转载本文请保留以下网址:http://www.cnblogs.com/warren-wong/p/3977685.html
如果发现文中有错误之处,请务必告诉我,谢谢大家。
标签:style blog http color io os 使用 ar strong
原文地址:http://www.cnblogs.com/warren-wong/p/3977685.html