初次接触哈希表,我谈谈自己对哈希表的一些理解,可能有误,还望指正。
对于哈希表,存放的数据是键值对<key,value>。是按照键值来索引的,键key可以是字符串、单个字符、整形数等,值value就是存放结点数据。
通俗的说,对于哈希表,使用数组来存放基本的结点,每个结点在挂上一串链表构成的结构,如下图所示:
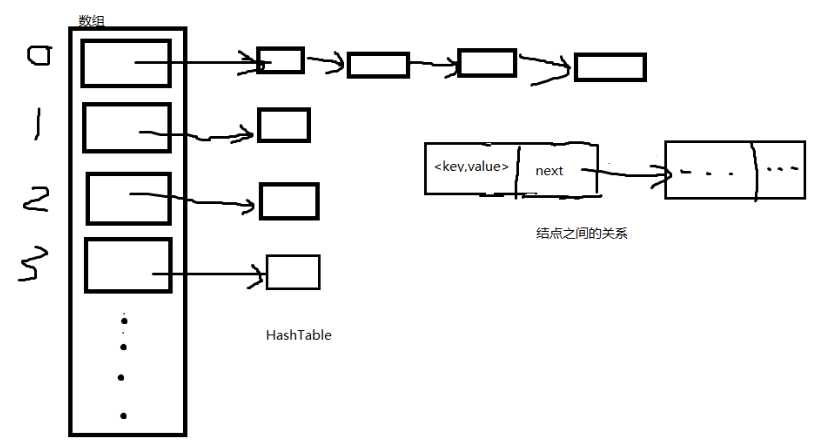
数组存放的可以是不存储任何数据的头结点,我们的数据是存放在以为头结点开始的链表上的。图中的结点的中存放着键值对和指向下一个结点的指针。
索引原理:Java中是根据键进行二次哈希得到哈希值,再由哈希值&(array.length-1)映射到数组下标,或者用哈希值%array.length映射。不同的键可以映射到同一个数组下标,采用链表来解决哈希冲突。基本的原理也就是有key通过hash函数(hash变换)得到hash量,再由hash量通过变换映射到数组下标上,通常为取余操作%和与操作&。
总之,就是通过算法将key映射到数组下标上。
个人理解:数组下标的索引为常数复杂度,hash表就是利用这一点来提高搜索效率的,定位到key对应的数组位置只需要O(1)的复杂度,然后再对链表进行遍历即可。
如果同样的数据用数组进行存储的话,数组长度为length,那么改用hash表来存储,查找的效率可以提高length倍。
但是得注意:hash相同,但是key不一定相同。 key相同,则hash一定相同。
正因为如此,所以才会出现哈希冲突,有三种解决方法,下面的参考中有。这里哈希表采用外加链表法。
参考:
[1] http://m.blog.csdn.net/stayneckwind2/article/details/53574685
[2] http://m.blog.csdn.net/u014539992/article/details/52874819
[3] http://m.blog.csdn.net/u014613043/article/details/50726630
[4] http://m.blog.csdn.net/xiaotan2011929/article/details/61647556
参考视频: