原文地址:https://segmentfault.com/a/1190000003914228 http://blog.csdn.net/synapse7/article/details/18908413
灰常不错的学习资料
先预处理下:在每个字符的两边都插入一个特殊的符号,比如abba变成#a#b#b#a#,aba变成 #a#b#a#(因为Manacher算法只能处理奇数长度的字符串)。同时,为了避免数组越界,在字符串开头添加另一特殊符号,比如$#a#b#a#。
以字符串3212343219为例,处理后变成S[] = "$#3#2#1#2#3#4#3#2#1#9#"。
然后用一个数组Len[i]来记录以处理后的字符S[i]为中心的最长回文子串的半长度(包括S[i]):
1 S # 3 # 2 # 1 # 2 # 3 # 4 # 3 # 2 # 1 # 9 # 2 Len 1 2 1 2 1 6 1 2 1 2 1 8 1 2 1 2 1 2 1 2 1
最终的回文子串的长度即为maxLen-1)
Manacher算法的核心就在于减少Len[i]的计算量,使得原来O(n^2)的算法优化为O(n)。
下面两幅图的红框中的字符串为当前的右边界下标最大的回文子串,mid为其中心,right为其最右端+1,i‘=2*mid-i为i关于mid的对称点。
现要计算Len[i],若以i‘为中心的回文串(黄框)包含在最长回文子串中,则由回文串的对称性,以i为中心的回文串亦在最长回文子串中,即有Len[i]=Len[2*mid-i]

若以i‘为中心的回文串(黄框)不包含在最长回文子串中,则以i为中心的回文串的半长度Len[i]=right-i+(之后继续判断的长度)

那么,为什么复杂度是O(n)的呢?
首先,主要影响复杂度的是s[i + len[i]] == s[i - len[i]]这一判断。
由下面的代码可知,当i<right时,我们就用常数的时间计算Len[i](此时不会执行while中的语句);当i>=right时,我们就继续判断:while (s[i + len[i]] == s[i - len[i]]) ++len[i]; 结束后,right < i + len[i]为真,更新right值。这样,我们至多进行n次s[i + len[i]] == s[i - len[i]]判断,故复杂度为O(n)。
完整代码:


1 #include<bits/stdc++.h> 2 using namespace std; 3 const int mx = 10000; 4 5 char ss[mx + 5], s[(mx << 1) + 5]; /// ss为源串,s为处理后的字符串 6 int len[(mx << 1) + 5]; 7 8 void debug() 9 { 10 int i; 11 for (i = 1; s[i]; ++i) printf("%c ", s[i]); 12 puts(""); 13 for (i = 1; s[i]; ++i) printf("%d ", len[i]); 14 puts(""); 15 } 16 17 int main() 18 { 19 int right, mid, i, maxlen; 20 while (gets(ss)) 21 { 22 memset(s, 0, sizeof(s)); 23 s[0] = ‘$‘; 24 for (i = 0; ss[i]; ++i) s[(i << 1) + 1] = ‘#‘, s[(i << 1) + 2] = ss[i]; 25 s[(i << 1) + 1] = ‘#‘; 26 memset(len, 0, sizeof(len)); 27 maxlen = right = mid = 0; 28 for (i = 1; s[i]; ++i) 29 { 30 len[i] = (i < right ? min(len[(mid << 1) - i], right - i) : 1); 31 /* 取min的原因:记点i关于mid的对称点为i‘, 32 若以i‘为中心的回文串范围超过了以mid为中心的回文串的范围 33 (此时有i + len[(mid << 1) - i] >= right,注意len是包括中心的半长度) 34 则len[i]应取right - i(总不能超过边界吧) */ 35 while (s[i + len[i]] == s[i - len[i]]) ++len[i]; 36 maxlen = max(maxlen, len[i]); 37 if (right < i + len[i]) mid = i, right = i + len[i]; 38 } 39 printf("%d\n", maxlen - 1); 40 debug(); 41 } 42 return 0; 43 }
补充:使用 Manacher 算法后我们得到了一个 len 数组,利用它我们可以在 O(1) 的时间内判断该字符串的任意子串是不是回文串,方法如下:
1 inline bool Query(int l, int r) /// 判断源串中的某一子串 ss[l...r] 是否为回文串 2 { 3 return len[l + r + 2] >= r - l + 1; 4 }
0. 问题定义
最长回文子串问题:给定一个字符串,求它的最长回文子串长度。
如果一个字符串正着读和反着读是一样的,那它就是回文串。下面是一些回文串的实例:
12321 a aba abba aaaa tattarrattat(牛津英语词典中最长的回文单词)1. Brute-force 解法
对于最长回文子串问题,最简单粗暴的办法是:找到字符串的所有子串,遍历每一个子串以验证它们是否为回文串。一个子串由子串的起点和终点确定,因此对于一个长度为n的字符串,共有n^2个子串。这些子串的平均长度大约是n/2,因此这个解法的时间复杂度是O(n^3)。
2. 改进的方法
显然所有的回文串都是对称的。长度为奇数回文串以最中间字符的位置为对称轴左右对称,而长度为偶数的回文串的对称轴在中间两个字符之间的空隙。可否利用这种对称性来提高算法效率呢?答案是肯定的。我们知道整个字符串中的所有字符,以及字符间的空隙,都可能是某个回文子串的对称轴位置。可以遍历这些位置,在每个位置上同时向左和向右扩展,直到左右两边的字符不同,或者达到边界。对于一个长度为n的字符串,这样的位置一共有n+n-1=2n-1个,在每个位置上平均大约要进行n/4次字符比较,于是此算法的时间复杂度是O(n^2)。
3. Manacher 算法
对于一个比较长的字符串,O(n^2)的时间复杂度是难以接受的。Can we do better?
先来看看解法2存在的缺陷。
1) 由于回文串长度的奇偶性造成了不同性质的对称轴位置,解法2要对两种情况分别处理;
2) 很多子串被重复多次访问,造成较差的时间效率。
缺陷2)可以通过这个直观的小??体现:
char: a b a b a
i : 0 1 2 3 4当i==1,和i==2时,左边的子串aba分别被遍历了一次。
如果我们能改善解法2的不足,就很有希望能提高算法的效率。Manacher正是针对这些问题改进算法。
(1) 解决长度奇偶性带来的对称轴位置问题
Manacher算法首先对字符串做一个预处理,在所有的空隙位置(包括首尾)插入同样的符号,要求这个符号是不会在原串中出现的。这样会使得所有的串都是奇数长度的。以插入#号为例:
aba ———> #a#b#a#
abba ———> #a#b#b#a#插入的是同样的符号,且符号不存在于原串,因此子串的回文性不受影响,原来是回文的串,插完之后还是回文的,原来不是回文的,依然不会是回文。
(2) 解决重复访问的问题
我们把一个回文串中最左或最右位置的字符与其对称轴的距离称为回文半径。Manacher定义了一个回文半径数组RL,用RL[i]表示以第i个字符为对称轴的回文串的回文半径。我们一般对字符串从左往右处理,因此这里定义RL[i]为第i个字符为对称轴的回文串的最右一个字符与字符i的距离。对于上面插入分隔符之后的两个串,可以得到RL数组:
char: # a # b # a #
RL : 1 2 1 4 1 2 1
RL-1: 0 1 0 3 0 1 0
i : 0 1 2 3 4 5 6
char: # a # b # b # a #
RL : 1 2 1 2 5 2 1 2 1
RL-1: 0 1 0 1 4 1 0 1 0
i : 0 1 2 3 4 5 6 7 8上面我们还求了一下RL[i]-1。通过观察可以发现,RL[i]-1的值,正是在原本那个没有插入过分隔符的串中,以位置i为对称轴的最长回文串的长度。那么只要我们求出了RL数组,就能得到最长回文子串的长度。
于是问题变成了,怎样高效地求的RL数组。基本思路是利用回文串的对称性,扩展回文串。
我们再引入一个辅助变量MaxRight,表示当前访问到的所有回文子串,所能触及的最右一个字符的位置。另外还要记录下MaxRight对应的回文串的对称轴所在的位置,记为pos,它们的位置关系如下。
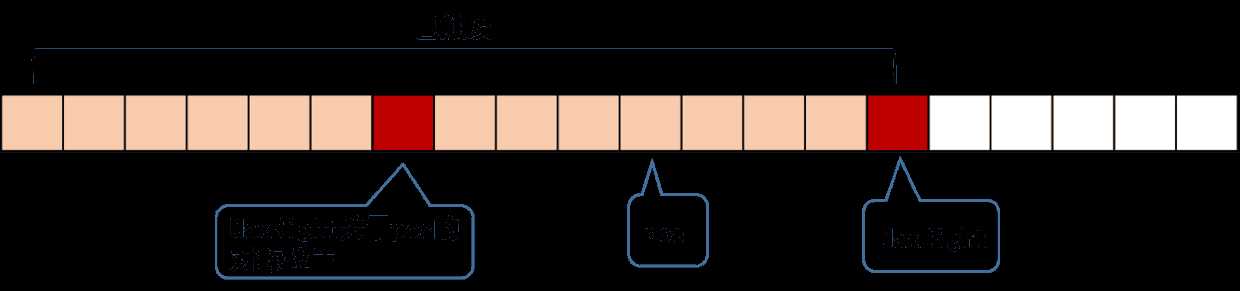

我们从左往右地访问字符串来求RL,假设当前访问到的位置为i,即要求RL[i],在对应上图,i必然是在po右边的(obviously)。但我们更关注的是,i是在MaxRight的左边还是右边。我们分情况来讨论。
1)当i在MaxRight的左边
情况1)可以用下图来刻画: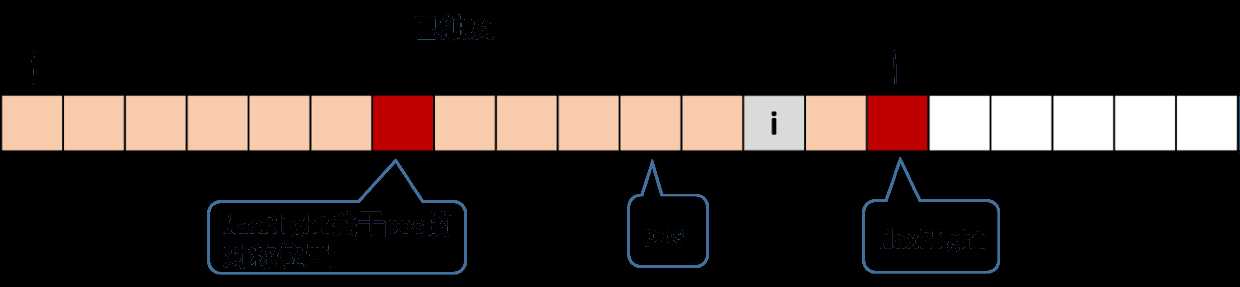

我们知道,图中两个红色块之间(包括红色块)的串是回文的;并且以i为对称轴的回文串,是与红色块间的回文串有所重叠的。我们找到i关于pos的对称位置j,这个j对应的RL[j]我们是已经算过的。根据回文串的对称性,以i为对称轴的回文串和以j为对称轴的回文串,有一部分是相同的。这里又有两种细分的情况。
-
以
j为对称轴的回文串比较短,短到像下图这样。
-

这时我们知道RL[i]至少不会小于RL[j],并且已经知道了部分的以i为中心的回文串,于是可以令RL[i]=RL[j]。但是以i为对称轴的回文串可能实际上更长,因此我们试着以i为对称轴,继续往左右两边扩展,直到左右两边字符不同,或者到达边界。
-
以
j为对称轴的回文串很长,这么长:

这时,我们只能确定,两条蓝线之间的部分(即不超过MaxRight的部分)是回文的,于是从这个长度开始,尝试以i为中心向左右两边扩展,,直到左右两边字符不同,或者到达边界。
不论以上哪种情况,之后都要尝试更新MaxRight和pos,因为有可能得到更大的MaxRight。
具体操作如下:
step 1: 令RL[i]=min(RL[2*pos-i], MaxRight-i)
step 2: 以i为中心扩展回文串,直到左右两边字符不同,或者到达边界。
step 3: 更新MaxRight和pos2)当i在MaxRight的右边


遇到这种情况,说明以i为对称轴的回文串还没有任何一个部分被访问过,于是只能从i的左右两边开始尝试扩展了,当左右两边字符不同,或者到达字符串边界时停止。然后更新MaxRight和pos。
(3) 算法实现
(4) 复杂度分析
空间复杂度:插入分隔符形成新串,占用了线性的空间大小;RL数组也占用线性大小的空间,因此空间复杂度是线性的。
时间复杂度:尽管代码里面有两层循环,通过amortized analysis我们可以得出,Manacher的时间复杂度是线性的。由于内层的循环只对尚未匹配的部分进行,因此对于每一个字符而言,只会进行一次,因此时间复杂度是O(n)。
描述
小Hi和小Ho是一对好朋友,出生在信息化社会的他们对编程产生了莫大的兴趣,他们约定好互相帮助,在编程的学习道路上一同前进。
这一天,他们遇到了一连串的字符串,于是小Hi就向小Ho提出了那个经典的问题:“小Ho,你能不能分别在这些字符串中找到它们每一个的最长回文子串呢?”
小Ho奇怪的问道:“什么叫做最长回文子串呢?”
小Hi回答道:“一个字符串中连续的一段就是这个字符串的子串,而回文串指的是12421这种从前往后读和从后往前读一模一样的字符串,所以最长回文子串的意思就是这个字符串中最长的身为回文串的子串啦~”
小Ho道:“原来如此!那么我该怎么得到这些字符串呢?我又应该怎么告诉你我所计算出的最长回文子串呢?
小Hi笑着说道:“这个很容易啦,你只需要写一个程序,先从标准输入读取一个整数N(N<=30),代表我给你的字符串的个数,然后接下来的就是我要给你的那N个字符串(字符串长度<=10^6)啦。而你要告诉我你的答案的话,只要将你计算出的最长回文子串的长度按照我给你的顺序依次输出到标准输出就可以了!你看这就是一个例子。”
样例输入
3 abababa aaaabaa acacdas
样例输出
7 5 3
1 /************************************************************************* 2 > File Name: manacher.cpp 3 > Author: PrayG 4 > Mail: 5 > Created Time: 2018年01月06日 星期六 17时47分16秒 6 ************************************************************************/ 7 8 #include<iostream> 9 #include<stdio.h> 10 #include<math.h> 11 #include<string.h> 12 using namespace std; 13 const int maxn = 1e6+3; 14 const int Maxn = maxn << 1; 15 char s[maxn],ss[Maxn]; 16 int len[Maxn]; 17 18 int main() 19 { 20 int n,right,maxlen,pos; 21 scanf("%d",&n); 22 while(n--) 23 { 24 memset(len,0,sizeof(len)); 25 memset(ss,0,sizeof(ss)); 26 memset(s,0,sizeof(s)); 27 ss[0] = ‘$‘; 28 scanf("%s",s); 29 int i; 30 for(i = 0; s[i]; i++) 31 { 32 ss[(i << 1) + 1] = ‘#‘; 33 ss[(i << 1) + 2] = s[i]; 34 } 35 ss[(i << 1) + 1] = ‘#‘; 36 right = maxlen = pos = 0; 37 for(i = 1; ss[i]; i++) 38 { 39 len[i] = (i < right ? min(len[(pos << 1) - i],right-i) : 1); 40 while(ss[i + len[i]] == ss[i - len[i]]) ++len[i]; 41 maxlen = max(maxlen,len[i]); 42 if(right < i + len[i]) 43 { 44 right = i + len[i]; 45 pos = i; 46 } 47 } 48 printf("%d\n",maxlen -1); 49 } 50 return 0; 51 }