英文原文链接:Detection of ArUco Markers
姿态估计(Pose estimation)在计算机视觉领域扮演着十分重要的角色:机器人导航、增强现实以及其它。这一过程的基础是找到现实世界和图像投影之间的对应点。这通常是很困难的一步,因此我们常常用自己制作的或基本的Marker来让这一切变得更容易。
最为流行的一个途径是基于二进制平方的标记。这种Marker的主要便利之处在于,一个Marker提供了足够多的对应(四个角)来获取相机的信息。同样的,内部的二进制编码使得算法非常健壮,使得应用错误检测和校正技术成为可能。
aruco模块基于ArUco库,这是一个检测二进制marker的非常流行的库,是由Rafael Mu?oz和Sergio Garrido完成的。
aruco的函数包含在
#include <opencv2/aruco.hpp>Marker和字典
一个ArUco marker是一个二进制平方标记,它由一个宽的黑边和一个内部的二进制矩阵组成,内部的矩阵决定了它们的id。黑色的边界有利于快速检测到图像,二进制编码可以验证id,并且可以应用错误检测和校正技术。marker的大小决定了内部矩阵的大小。例如,一个4x4的marker由16位组成。

应当注意到,我们能够检测到一个Marker在空间中发生了旋转,但是,检测的过程需要确定它的初始旋转,所以每个角点都应该是清晰可见的,确定的,不能有歧义,这也是通过二进制编码来做的。
markers的字典是在一个特殊应用中使用到的marker的集合。这仅仅是每个marker的二进制编码的链表。
- 字典的主要性质是字典的大小和Marker的大小:
- 字典的大小是指组程字典的marker的数量
- marker的大小是这些marker的尺寸(位的个数)
- aruco模块包含了一些预定义的字典,这些字典涵盖了一系列的字典大小和Marker尺寸。
有些人可能会认为marker的id是通过将二进制编码转换成十进制获得的。但是这实际上是不可能的,因为尺寸大的marker的位数会很大,管理如此多的数据并不现实。事实上,一个marker的id仅仅是marker在它所在的字典的下标。例如,一个字典里的五个marker的id是:0,1,2,3和4。
更多有关字典的信息在“Selecting a dictionary”部分提及。
创建Marker
在检测之前,markers需要被打印出来,以把它们放到环境中。marker的图像可以使用drawMarker()函数生成。
举个例子,让我们分析一下如下的调用:
cv::Mat markerImage;
cv::Ptr<cv::aruco::Dictionary> dictionary = cv::aruco::getPredefinedDictionary(cv::aruco::DICT_6X6_250);
cv::aruco::drawMarker(dictionary, 23, 200, markerImage, 1);首先,通过选择aruco模块中一个预定义好的字典来创建一个Dictionary对象。就当前例子而言,这个字典是由250个marker组成的,每个marker的大小为6x6位(DICT_6X6_250)
drawMarker的参数如下:
- 第一个参数是之前创建的Dictionary对象。
- 第二个参数是marker的id,在这个例子中选择的是字典
DICT_6X6_250的第23个marker。注意到每个字典是由不同数目的Marker组成的,在这个例子中的字典中,有效的Id数字范围是0到249。不在有效区间的特定id将会产生异常。 - 第三个参数,200,是输出Marker图像的大小。在这个例子中,输出的图像将是200x200像素大小。注意到这一参数需要满足能够存储特定字典 的所有位。举例来说,你不能为6x6大小的marker生成一个5x5图像(这还没有考虑到Marker的边界)。除此之外,为了避免变形,这一参数最好和位数+边界的大小成正比,或者至少要比marker的大小大得多(如这个例子中的200),这样变形就不显著了。
- 第四个参数是输出的图像。
- 最终,最后一个参数是一个可选的参数,它指定了Marer黑色边界的大小。这一大小与位数数目成正比。例如,值为2意味着边界的宽度将会是2的倍数。默认的值为1。
生成的图像如下:
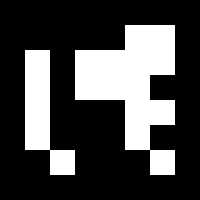
详细的例子在模块示例文件夹中的create_marker.cpp
检测Marker
给定一个可以看见ArUco marker的图像,检测程序应当返回检测到的marker的列表。每个检测到的marker包括:
- 图像四个角的位置(按照原始的顺序)
- marker的ID
marker检测过程由以下两个主要步骤构成:
- 检测候选marker。在这一阶段我们分析图像,以找到那些可能是marker的方形。首先要做的是利用自适应性阈值来分割marker,然后从阈值化的图像中提取外形轮廓,并且舍弃那些非凸多边形的,以及那些不是方形的。我们还使用了一些额外的滤波(来剔除那些过小或者过大的轮廓,过于相近的凸多边形,等)
- 检测完marker候选之后,我们有必要分析它的内部编码来确定它们是否确实是marker。此步骤首先提取每个标记的标记位。为了达到这个目的,首先,我们需要对图像进行透视变换,来得到它规范的形态(正视图)。然后,对规范的图像用Ossu阈值化以分离白色和黑色位。这一图像根据marker大小和边界大小被分为许多不同格子,我们通过统计落在每个格子中的黑白像素数目来决定这是黑色还是白色的位。最终,我们分析这些位来决定这个marker是属于哪个特定字典的,如果有必要的话,需要对错误进行检测。
对于如下图像:

这些是检测出来的marker(用绿色标记):

以下是识别阶段被剔除的Marker候选(用红色标记):

在aruco模块,检测是由detectMarkers()函数完成的,这一函数是这个模块中最重要的函数,因为剩下的所有函数操作都基于detectMarkers()返回的检测出的markers。
一个marker检测的例子:
cv::Mat inputImage;
std::vector<int> markerIds;
std::vector<std::vector<cv::Point2f>> markerCorners, rejectedCandidates;
cv::Ptr<cv::aruco::DetectorParameters> parameters;
cv::Ptr<cv::aruco::Dictionary> dictionary = cv::aruco::getPredefinedDictionary(cv::aruco::DICT_6X6_250);
cv::aruco::detectMarkers(inputImage, dictionary, markerCorners, markerIds, parameters, rejectedCandidates);detectMarkers 的参数为:
- 第一个参数是待检测marker的图像。
- 第二个参数是字典对象,在这一例子中是预先定义的字典 (
DICT_6X6_250).
检测出的markers存储在markerCorners和markerIds结构中: markerCorners是检测出的图像的角点的列表。对于每个marker,将返回按照原始顺序排列的四个角(从左上角开始顺时针旋转)。因此,第一个点是左上角的角,然后是右上角、右下角和左下角。
-markerIds是在markerCorners检测出的所有maker的ID列表.注意返回的markerCorners和markerIds的vetcor具有相同的大小。- 第四个参数是类型的对象
DetectionParameters. 这一对象包含了检测过程中的所有可以定制的参数。这一参数将在 下一章节详细介绍。 - 最后一个参数,
rejectedCandidates, 是返回的所有marker候选, 例如, 那些被检测出来但不是有效编码的方形。每个候选同样由它的四个角定义,形式和markerCorners的参数一样。这一参数可以被省略,它仅仅用于debug阶段,或是用于“再次寻找”策略(详见refineDetectedMarkers())
detectMarkers()之后,接下来你想要做的事情可能是检查你的marker是否被正确地检测出来了。幸运的是,aruco模块提供了一个函数,它能在输入图像中来绘制检测出来的markers,这个函数就是drawDetectedMarkers() ,例子如下:
cv::Mat outputImage;
cv::aruco::drawDetectedMarkers(image, markerCorners, markerIds); - image是输入/输出图像,程序将在这张图上绘制marker。(它通常就是检测marker的那张图像)
markerCorners和markerIds是检测出marker的结构,它们的格式和detectMarkers()函数提供的一样。

请注意这个函数仅仅用于可视化,而没有别的什么用途。
使用这两个函数我们完成了基本的marker识别步骤,我们可以从相机中检测出Marker了。