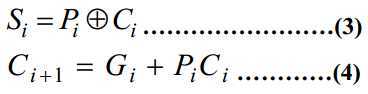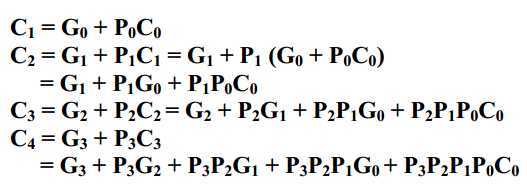首页
Web开发
Windows程序
编程语言
数据库
移动开发
系统相关
微信
其他好文
会员
首页
>
其他好文
> 详细
加法器
时间:
2014-09-17 21:47:02
阅读:
255
评论:
0
收藏:
0
[点我收藏+]
标签:
style
blog
http
color
使用
ar
strong
2014
sp
基本单元:全加器
假设全加器的延迟是1,占用的面积也是1。
行波进位加法器(Ripple Carry Adder)
结构类似于我们拿笔在纸上做加法的方法。从最低位开始做加法,将进位结果送到下一级做和。由于本级的求和需要等待前一级的进位结果才可以得到,所以对于两个N-bit的求和。即使有N个一位的全加器,也需要N个延迟。
不妨考虑m个n-bit的加数求和,采用树形结构。占用面积:
m*n
,时间延迟:
n*log
2
(m)
。
上面没有考虑每两个加数的进位,事实上,采用树形结构,第一次求和加法器的位数是n,输出的结果是n+1,最后一次加法的位数就是n+log
2
(m)。进位产生的多出来的位数就是1/2*log
2
(m)。故实际的延迟应该是n*log
2
(m)+1/2*log
2
(m)*log
2
(m)
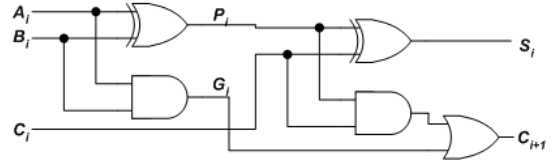
超前进位加法器(Carry Look-Ahead, CLA)
事实上,在以下两种情况中,C
i
=1:
A
i
和B
i
都为1
A
i
和B
i
有一个为1,且C
i-1
为1
则第i位的求和电路可以用下图实现:
对应的表达式如下:
递归后有:
由此可见,每一级的进位仅与输入信号有关,无需等待前一级的进位而可以根据输入信号直接产生,这就是超前进位的原理。
延迟分析:产生P和G仅需要一个单位的延迟,得到C之后的求和得到S也只需要一个单位的延迟。最大的延迟发生在上例的C
4
,即P
3
P
2
P
1
P
0
C
0
,如果使用二输入与门或者或门的话,延迟为log
2
(n),n为两个加数的bit位数。所以时间复杂度为
O(log
2
(n))
,小于行波进位加法器的
O(n)。
相应的,资源消耗为
n*log
2
(n)。对于m个加数,延迟为
log
2
(m)*log
2
(n)
注意,上面的延迟也没有计算最高位进位的影响,而是默认每个加数从头到尾都是n位。
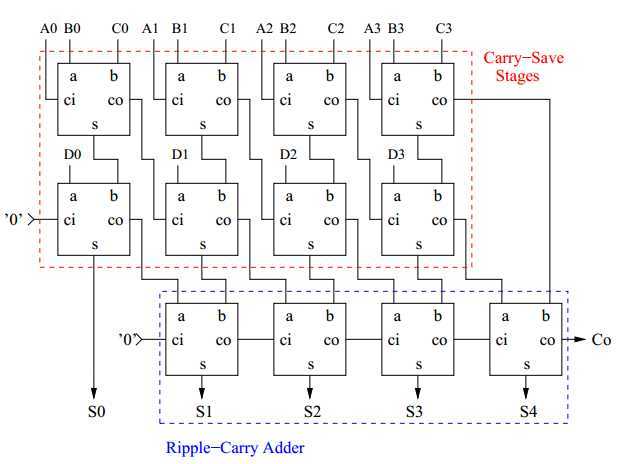
进位存储加法器(Carry Save Adder, CSA)
在有多个加数的时候,我们可以先加前两个,再加第三个,如此循环。也可以两两配对做加法,然后得到的加数再两两配对。这种算法的时间消耗主要是每次得到求和结果时进位需要从后往前累加,而在多个加数时,其实我们可以把本级的进位存储下来,作为运算结果到下一级求和,而不必立刻求和。
由上图可知,完整的进位存储加法器,先用进位存储的方法计算每位的部分和以及进位结果,对于m个加数,延时为m-2。在最后阶段对着两部分求和得到最后的结果,注意,此处的延迟不是log
2
(n),因为每经过一级CSA,就多了一位进位,最后的延迟应该是log
2
(m-2+n)。所以使用进位存储加法器计算m个加数,时间复杂度为
O(m+log
2
(m+n))
加法器
标签:
style
blog
http
color
使用
ar
strong
2014
sp
原文地址:http://www.cnblogs.com/huhou/p/3965487.html
踩
(
0
)
赞
(
0
)
举报
评论
一句话评论(
0
)
登录后才能评论!
分享档案
更多>
2021年07月29日 (22)
2021年07月28日 (40)
2021年07月27日 (32)
2021年07月26日 (79)
2021年07月23日 (29)
2021年07月22日 (30)
2021年07月21日 (42)
2021年07月20日 (16)
2021年07月19日 (90)
2021年07月16日 (35)
周排行
更多
分布式事务
2021-07-29
OpenStack云平台命令行登录账户
2021-07-29
getLastRowNum()与getLastCellNum()/getPhysicalNumberOfRows()与getPhysicalNumberOfCells()
2021-07-29
【K8s概念】CSI 卷克隆
2021-07-29
vue3.0使用ant-design-vue进行按需加载原来这么简单
2021-07-29
stack栈
2021-07-29
抽奖动画 - 大转盘抽奖
2021-07-29
PPT写作技巧
2021-07-29
003-核心技术-IO模型-NIO-基于NIO群聊示例
2021-07-29
Bootstrap组件2
2021-07-29
友情链接
兰亭集智
国之画
百度统计
站长统计
阿里云
chrome插件
新版天听网
关于我们
-
联系我们
-
留言反馈
© 2014
mamicode.com
版权所有 联系我们:gaon5@hotmail.com
迷上了代码!