构建参考: [ Rabbitmq cluster setup with HAproxy ] [ python demo ]
RabbitMQ Cluster 遇到的问题
python pika 作为consumer 连接 rabbitmq cluster 的时候, 事实上连接的是 cluster 的一个 node, 当连接数过多的时候, 这个节点的处理性能会成为一个瓶颈, 可能会遇到这样的报错 [ connection reset by peer ].
对于 [ connection reset by peer ] 这个问题的处理, [ 这里 ] 提供了一个方案:
Client --> Load Balancer --> RabbitMQ Cluster Instances
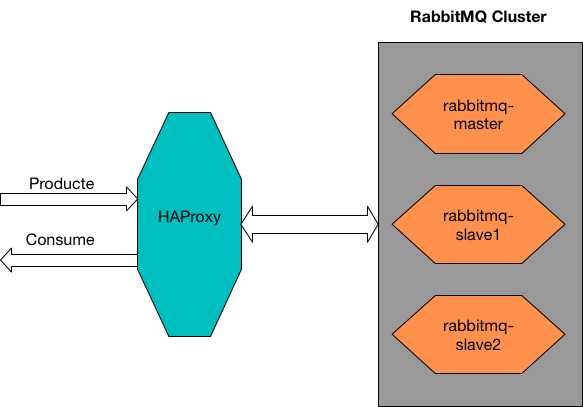
RabbitMQ 集群构建
集群环境
系统: CentOS 7.x x64
haproxy-server : 172.16.0.100
rabbitmq-master : 172.16.0.10
rabbitmq-slave1 : 172.16.0.11
rabbitmq-slave2 : 172.16.0.12
配置 /etc/hosts
172.16.0.10 rabbitmq-master
172.16.0.11 rabbitmq-slave1
172.16.0.12 rabbitmq-slave2
安装 RabbitMQ
在三台 rabbitmq 服务器上面分别执行:
yum install rabbitmq-server配置 Cookie
RabbitMQ 集群通过 /var/lib/rabbitmq/.erlang.cookie 内的 cookie 值来确认各节点是否在同一个集群.
在 rabbitmq-master:
rabbitmq-server -detached在 rabbitmq-master上查看 /var/lib/rabbitmq/.erlang.cookie 值:
cat /var/lib/rabbitmq/.erlang.cookie比如获取的值为: GBNXRROLXDWMMIFZQWHD
在 rabbitmq-slave1 & rabbitmq-slave2 :
echo GBNXRROLXDWMMIFZQWHD > /var/lib/rabbitmq/.erlang.cookie添加 Slave 节点到 master
在 rabbitmq-slave1 & rabbitmq-slave2 上面启动服务:
rabbitmq-server -detached在rabbitmq-slave1 & rabbitmq-slave2 上分别执行:
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbitmq@rabbitmq-master
rabbitmqctl start_app查看集群状态
在 RabbitMQ Cluster 任意一个节点:
rabbitmctl cluster_status启用集群高可用
在 RabbitMQ Cluster 每个节点执行:
rabbitmqctl set_policy ha-all "" ‘{"ha-mode":"all","ha-sync-mode":"automatic"}‘启用 RabbitMQ 组件
在 RabbitMQ Cluster 每个节点执行:
rabbitmq-plugins enable rabbitmq_management添加用户
在 RabbitMQ Cluster 每个节点:
rabbitmqctl add_user <username> <password>
rabbitmqctl set_user_tags <username> <tag>
rabbitmqctl set_permissions -p / <username> ".*" ".*" ".*" 备注: 在 rabbitmqctl set_user_tag
这样, RabbitMQ 集群配置完成.
Web 访问
web 访问的前提是我们启用了 RabbitMQ 的组件: rabbitmq-plugins enable rabbitmq_management
可以在浏览器访问: http://ip_address:15672
登录用户和密码是 : rabbitmqctl add_user username password 设定的.
也可以使用默认添加的用户和密码: guest / guest.
HAProxy
以下所有的配置均在 haproxy-server 上面执行
安装 haproxy
yum install haproxy配置 haproxy
vim /etc/haproxy/haproxy.cfg
global
daemon
defaults
mode tcp
maxconn 10000
timeout connect 5s
timeout client 100s
timeout server 100s
listen rabbitmq 172.16.0.100:5672
mode tcp
balance roundrobin
server rabbit-master 172.16.0.10:5672 check inter 5s rise 2 fall 3
server rabbit-node1 172.16.0.11:5672 check inter 5s rise 2 fall 3
server rabbit-node2 172.16.0.12:5672 check inter 5s rise 2 fall 3启动 haproxy
systemctl start haproxy至此, 用 HAproxy 做RabbitMQ 的 LB 的集群已经配置完成, 在连接 MQ 的时候, 只要将地址配置为 haproxy-server 的 IP 和对应 Port 即可. 接下来会用 python 程序做测试
RabbitMQ Cluster Product & Consume Test
生产者: send.py
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host=‘172.16.0.100‘,port=5672))
channel = connection.channel()
channel.queue_declare(queue=‘hello‘)
channel.basic_publish(exchange=‘‘,
routing_key=‘hello‘,
body=‘Hello World!‘)
print(" [x] Sent ‘Hello World!‘")
connection.close() 消费者: receive.py
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host=‘172.16.0.100‘,port=5672))
channel = connection.channel()
channel.queue_declare(queue=‘hello‘)
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue=‘hello‘,
no_ack=True)
print(‘ [*] Waiting for messages. To exit press CTRL+C‘)
channel.start_consuming() 生产
在同一网络中的机器 CLI 执行:
for i in {1..10};do python send.py;done这可以写10条数据到 RabbitMQ 的队列中.
在 RabbitMQ Cluster 的任意一个节点执行:
rabbitmqctl list_queues可以查看到队列以及队列内消息的数量.
消费
在同一网络中的机器 CLI 执行:
python receive.py即可读取队列中的数据.
btw, 我爱死博客园的 markdown 了!