程序的要求是将一个csv的数据读出来,转化成为一个字典,最后形成一个可供查询的字典。
首先来看看最终要成的结构:
{‘"1(马官营-四惠站)"‘: [‘马官营‘, ‘六里桥北里‘, ‘公主坟南站‘, ‘公主坟‘, ‘军事博物馆‘, ‘木樨地‘, ‘工会大楼‘, ‘礼士路‘, ‘复兴门‘, ‘西单‘, ‘中山公园‘, ‘天安门‘, ‘东单‘, ‘北京站口‘, ‘日坛路‘, ‘永安里‘, ‘大北窑‘, ‘郎家园‘, ‘八王坟‘, ‘四惠站‘]}
一、分析首先要将数据全部读取出来。这里有三种使用readline(需要用for循环每行),使用readlines(全部读取之后需要分割形成可用的列表),使用csv模块直接读取:
使用readlines读取
#读取csv里面的数据 file =r‘C:\Users\jeep-peng zhang\Desktop\beijing_jt.csv‘ f = open(file,‘r‘,encoding=‘utf-8‘) stat = f.readlines()[1:40] #链接空格拼接获取key值 stat_join = ‘‘.join(stat)#把他们链接起来 stat_split = stat_join.split(‘,‘)#以逗号把他们分开 stat_station = stat_split[-1].split(‘\r\n \r\n‘)#excel 里面特有的换行等 print(stat_split[1])#获得key值
原理:
1.分割key()和value()值
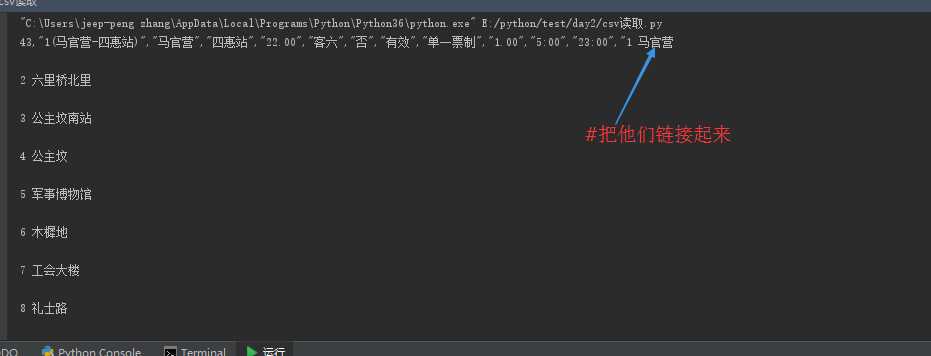
2.使用csv读取,刚开始采用这种方法遍历。发现虽然可以把key()值弄出来,但是无法和value()结合。
import csv with open(file,‘r‘,encoding=‘utf-8‘) as files: reader = csv.reader(files) line = next(reader)#从第二行开始读 lines = [line for line in reader] list = [] for row in lines: list.append(row[1])
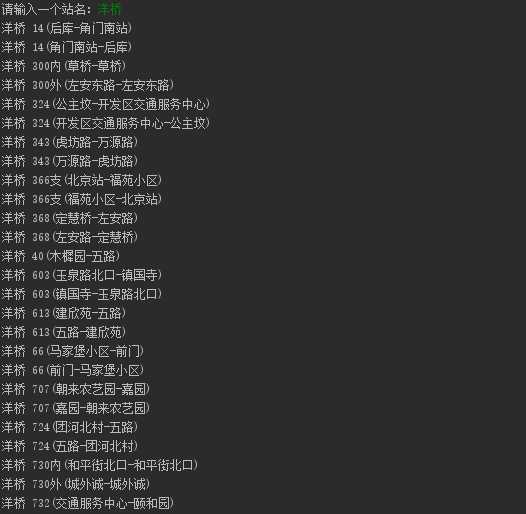
改进后:输入站名查询线路
# #读取csv里面的数据 file =r‘C:\Users\jeep-peng zhang\Desktop\beijing_jt.csv‘ # f = open(file,‘r‘,encoding=‘utf-8‘) # stat = f.readlines()[1:40] # #链接空格拼接获取key值 # stat_join = ‘‘.join(stat)#把他们链接起来 # stat_split = stat_join.split(‘,‘)#以逗号把他们分开 # stat_station = stat_split[-1].split(‘\r\n \r\n‘)#excel 里面特有的换行等 # print(stat_split[1])#获得key值 import csv with open(file,‘r‘,encoding=‘utf-8‘) as files: reader = csv.reader(files) next(reader)#第一行不需要,因此从第二行开始读 result = {} while True: try: lines = next(reader) except: break#读完之后退出 print(lines[1])#获取所有的keys() # # # #获取values值 import re part = (r‘(?P<name>\d+)\s(?P<stion>\D+)‘) end = re.findall(part,lines[-1]) resui = [] for a in end: print(a[0],a[1].strip()) resui.append(a[1].strip()) # # #构建一个字典 result[lines[1]]=resui#字典的写法 files.close() while True: user = input(‘请输入一个站名:‘) for k, v in result.items(): if user in v: print(user,k)
效果: