PySpider
Begin
安装pip install pyspider
在windows系统好像会出现如下问题
Command "python setup.py egg_info" failed with error code 10 in
解决方法:
利用wheel安装
S1: pip install wheel
S2: 进入www.lfd.uci.edu/~gohlke/pythonlibs/,Ctrl + F查找pycurl
S3: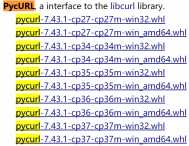
这个包名是pycurl-版本-你下载的python版本(如python3.4,就是cp34)-win32/64操作系统),选择你所需要的进行下载
S4: 安装编译包 pip install 你下载的whl文件的位置如(d:\pycurl-7.43.1-cp34-cp34m-win_amd64.whl)
S5: 继续pip install pyspider
Use
命令行输入pyspider all,启动pyspider(启动的时候可能一直卡在result_worker starting, 这个时候先等等, 然后再Ctrl + C关闭, 再次 pyspider all)
接着进入网站localhost:5000,出现如下页面
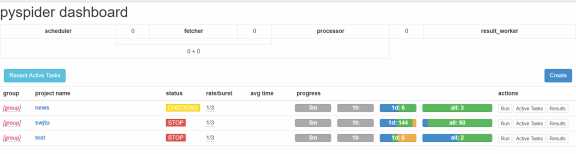
接着点击Create,输入项目名和你所要爬的网站
进入项目后左边是视图区,可以看很多东西;右边是代码编辑区
接着讲讲代码使用
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-01-13 10:23:04
# Project: test
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl(‘https://scrapy.org/‘, callback=self.index_page)#这句代码的意思是爬取‘https://scrapy.org/‘,进入之后回调,触发self.index_page函数,这个时候response就是获取到的页面
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc(‘a[href^="http"]‘).items():#这里的response.doc语法使用的是jQuery的语法,获取属性href前缀为http的a标签(这里使用的CSS选择器语法)
self.crawl(each.attr.href, callback=self.detail_page)#接着爬取所有获取到的a标签链接,每访问一个,触发回调函数self.detail_page,这个时候的response就是访问的当前网站的html页面
@config(priority=2)
def detail_page(self, response):#这里返回一个对象
return {
"url": response.url,
"title": response.doc(‘title‘).text(),
}