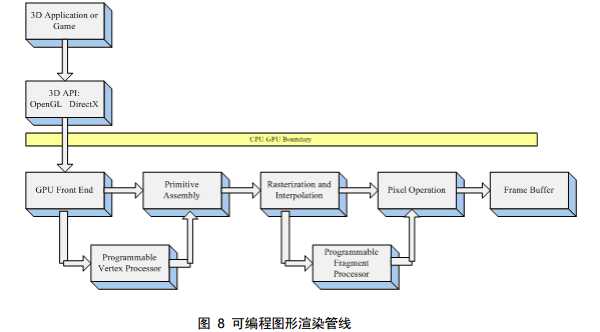
Graphics Processing Unit(GPU),即可编程图形处理单元, 通常也称之为可编程图形硬件。
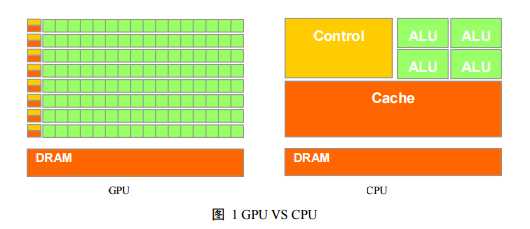
由于 GPU 具有高并行结构(highly parallel structure),所 以 GPU 在处理图形数据和复杂算法方面拥有比 CPU 更高的效率。图 1 GPU VS CPU 展示了 GPU 和 CPU 在结构上的差异,CPU 大部分面积为控制器和寄存器, 与之相比,GPU 拥有更多的 ALU(Arithmetic Logic Unit,逻辑运算单元)用于 数据处理,而非数据高速缓存和流控制,这样的结构适合对密集型数据进行并行 处理。CPU 执行计算任务时,一个时刻只处理一个数据,不存在真正意义上的 并行(请回忆 OS 教程上的时间片轮转算法),而 GPU 具有多个处理器核,在一 个时刻可以并行处理多个数据。
GPU 采用流式并行计算模式,可对每个数据进行独立的并行计算,所谓“对 数据进行独立计算”,即,流内任意元素的计算不依赖于其它同类型数据,例如, 计算一个顶点的世界位置坐标,不依赖于其他顶点的位置。而所谓“并行计算” 是指“多个数据可以同时被使用,多个数据并行运算的时间和 1 个数据单独执行 的时间是一样的”。图 2 中代码目的是提取 2D 图像上每个像素点的颜色值,在 CPU 上运算的 C++代码通过循环语句依次遍历像素;而在 GPU 上,则只需要一 条语句就足够。

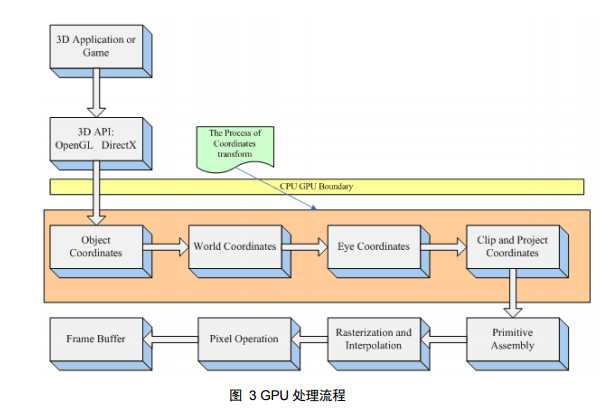
其一,object space coordinate 就是模型文件中的顶点值,这些值是在模型建模时得到的,例如,用 3DMAX 建 立一个球体模型并导出为.max 文件,这个文件中包含的数据就是 object space coordinate;其二,object space coordinate 与其他物体没有任何参照关系,注意, 这个概念非常重要,它是将 object space coordinate 和 world space coordinate 区分 开来的关键。无论在现实世界,还是在计算机的虚拟空间中,物体都必须和一个 固定的坐标原点进行参照才能确定自己所在的位置,这是 world space coordinate 的实际意义所在。
从 object space coordinate 到 world space coordinate 的变换过程由一个四阶矩阵控制,通常称之为 world matrix。需要高度注意的是:顶点法向量在模型文件中属于 object space,在 GPU 的 顶点程序中必须将法向量转换到 world space 中才能使用,如同必须将顶点坐标 从 object space 转换到 world space 中一样,但两者的转换矩阵是不同的,准确的 说,法向量从 object space 到 world space 的转换矩阵是 world matrix 的转置矩阵 的逆矩阵。
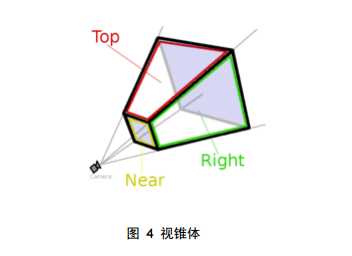
每个人都是从各自的视点出发观察这个世界,无论是主观世界还是客观世 界。同样,在计算机中每次只能从唯一的视角出发渲染物体。在游戏中,都会提 供视点漫游的功能,屏幕显示的内容随着视点的变化而变化。这是因为 GPU 将 物体顶点坐标从 world space 转换到了 eye space。 所谓 eye space,即以 camera(视点或相机)为原点,由视线方向、视角和 远近平面,共同组成一个梯形体的三维空间,称之为 viewing frustum(视锥), 如图 4 所示。近平面,是梯形体较小的矩形面,作为投影平面,远平面是梯形体 较大的矩形,在这个梯形体中的所有顶点数据是可见的,而超出这个梯形体之外 的场景数据,会被视点去除(Frustum Culling,也称之为视锥裁剪)。
从视点坐标空间到屏幕坐标空间 (screen coordinate space)事实上是由三步组成: 26 1. 用透视变换矩阵把顶点从视锥体中变换到裁剪空间的 CVV 中; 2. 在 CVV 进行图元裁剪; 3. 屏幕映射:将经过前述过程得到的坐标映射到屏幕坐标系上。
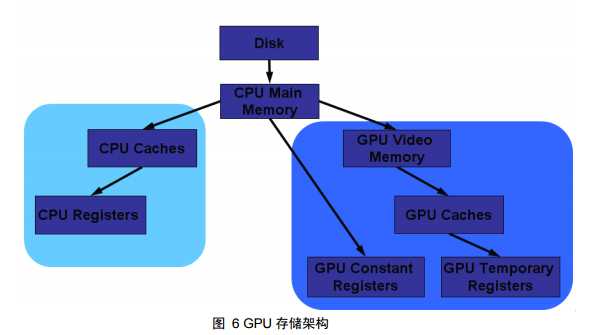
从物理结构而言,寄存器是 cpu 或 gpu 内部的存储单元,即寄存器是嵌入在 cpu 或者 gpu 中的,而内存则可以独立存在;从功能上而言,寄存器是有限存储 容量的高速存储部件,用来暂存指令、数据和位址。Shader 编成是基于计算机图 形硬件的,这其中就包括 GPU 上的寄存器类型,glsl 和 hlsl 的着色虚拟机版本 就是基于 GPU 的寄存器和指令集而区分的。
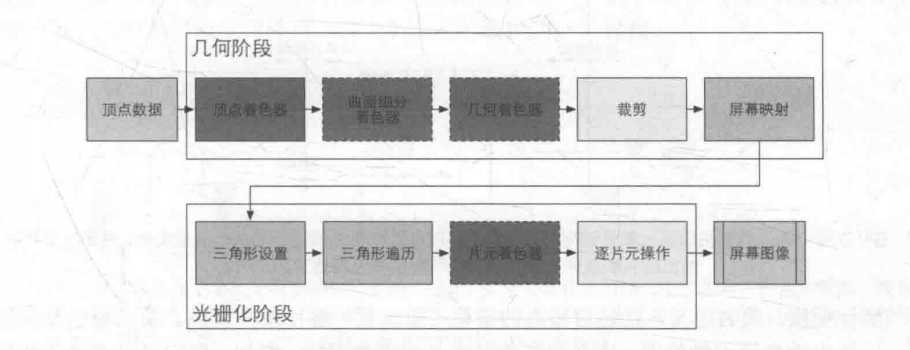
顶点着色器控制顶点坐标 转换过程;片段着色器控制像素颜色计算过程。这样就区分出顶点着色程序和片 段着色程序的各自分工:Vertex program 负责顶点坐标变换;Fragment program 负责像素颜色计算;前者的输出是后者的输入。