操作系统:Win7 64位
Hadoop:2.7.4
中文分词工具包IKAnalyzer: 5.1.0
开发工具:Intellij IDEA 2017 Community
准备中文分词工具包
项目需要引入中文分词工具包IKAnalyzer,故第一步是对中文分词工具包的打包并安装到本地库,在这过程中参考研究了以下文章及博客,非常感谢:
http://blog.csdn.net/zhu_tianwei/article/details/46607421
http://blog.csdn.net/cyxlzzs/article/details/7999212
http://blog.csdn.net/cyxlzzs/article/details/8000385
https://my.oschina.net/twosnail/blog/370744
1:下载中文分词工具包,源代码地址: https://github.com/linvar/IKAnalyzer
2:下载的源代码工程的pom.xml文件有点小问题,字典文件不能打包进jar,后面在运行时会报错误,需要修改一下
增加 properties节点:
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <jdk.version>1.8</jdk.version> </properties>
增加dependency节点,加入lucene-analyzers-common库:
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>5.1.0</version> </dependency>
修改build节点,加入resources及maven-jar-plugin:
<build> <resources> <resource> <directory>src/main/java</directory> <includes> <include>**/*.dic</include> </includes> </resource> </resources> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <source>${jdk.version}</source> <target>${jdk.version}</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>2.4</version> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <classpathPrefix>lib/</classpathPrefix> </manifest> </archive> <!--过滤掉不希望包含在jar中的文件 --> <excludes> <exclude>${project.basedir}/xml/*</exclude> </excludes> </configuration> </plugin> </plugins> </build>
完成修改后,可以打包安装到本地库了,使用mvn install 命令,可以在本地库中看到
中文词频统计及排序:
1. 创建maven工程hdfstest,将前面中文分词工具包的配置文件拷贝到放在resources目录内,结构如下:
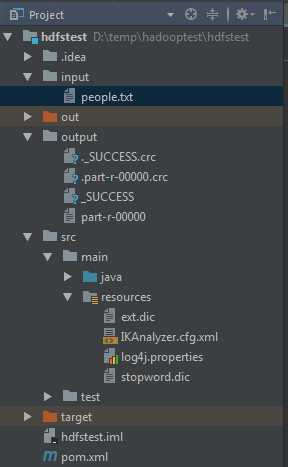
在分词扩展字典 ext.dic中保存的是需要分词的中文短语,在src同级目录下创建input目录,用于保存本地的测试输入文件,在resources目录下需要添加日志配置文件log4j.properties,否则会有如下所示警告信息,无法在窗口输出mapreduce内容,

将以下行添加到log4j.properties配置文件后,在Idea中调试时,可以在底部Console窗口中输出调试及mapreduce信息:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ISO8601} %-5p %c{1} - %m%n
2. 修改pom.xml 配置文件,引入分词工具包及hadoop库
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>hadoop.mapreduce</groupId> <artifactId>hdfstest</artifactId> <version>1.0</version> <repositories> <repository> <id>apache</id> <url>http://maven.apache.org</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.7.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>2.7.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>2.7.4</version> </dependency> <dependency> <groupId>org.wltea.analyzer</groupId> <artifactId>IKAnalyzer</artifactId> <version>5.1.0</version> </dependency> </dependencies> <build> <resources> <resource> <directory>src/main/resources</directory> <includes> <include>**/*</include> </includes> </resource> </resources> <plugins> <plugin> <artifactId>maven-dependency-plugin</artifactId> <executions> <execution> <id>copy-dependencies</id> <phase>prepare-package</phase> <goals> <goal>copy-dependencies</goal> </goals> <configuration> <!-- ${project.build.directory}为Maven内置变量,缺省为target --> <outputDirectory>${project.build.directory}/classes/lib</outputDirectory> <!-- 表示是否不包含间接依赖的包 --> <excludeTransitive>false</excludeTransitive> <!-- 表示复制的jar文件去掉版本信息 --> <stripVersion>true</stripVersion> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
3. 添加java工程代码 ChineseWordSplit
- 引入hadoop及中文分词包:
package examples; import java.io.IOException; import java.io.StringReader; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat; import org.apache.hadoop.mapreduce.lib.map.InverseMapper; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; import org.wltea.analyzer.core.IKSegmenter; import org.wltea.analyzer.core.Lexeme;
- 在ChineseWordSplit类中添加一个内部mapper类:TokenizerMapper, 从hadoop的Mapper类继承,实现中文分词的功能
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { StringReader input = new StringReader(value.toString()); IKSegmenter ikSeg = new IKSegmenter(input, true); for (Lexeme lexeme = ikSeg.next(); lexeme != null; lexeme = ikSeg.next()) { this.word.set(lexeme.getLexemeText()); context.write(this.word, one); } } }
- 在ChineseWordSplit类中添加一个内部Reducer类:IntSumReducer,从hadoop的Reducer类继承
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } this.result.set(sum); context.write(key, this.result); } }
- 创建主程序入口main:在类ChineseWordSplit中添加main函数
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); //下述3行配置文件用于提交job到本地mapreduce运行,此时无法调试map及reduce函数 //conf.set("mapreduce.framework.name", "yarn"); //conf.set("yarn.resourcemanager.hostname", "localhost"); //conf.set("mapreduce.job.jar", "D:\\temp\\hadooptest\\hdfstest\\target\\hdfstest-1.0.jar"); String inputFile = args[0]; Path outDir = new Path(args[1]); // 临时目录,保存第一个job的结果,用于第二个job的输入 Path tempDir = new Path(args[2] + System.currentTimeMillis()); // first job System.out.println("start task..."); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(ChineseWordSplit.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(inputFile)); FileOutputFormat.setOutputPath(job, tempDir); //second job, 第一个job的输出作为第二个job的输入 job.setOutputFormatClass(SequenceFileOutputFormat.class); if (job.waitForCompletion(true)) { System.out.println("start sort..."); Job sortJob = Job.getInstance(conf, "word sort"); sortJob.setJarByClass(ChineseWordSplit.class); /*InverseMapper由hadoop库提供,作用是实现map()之后的数据对的key和value交换*/ sortJob.setMapperClass(InverseMapper.class); sortJob.setInputFormatClass(SequenceFileInputFormat.class); // 反转map键值,计算词频并降序 sortJob.setMapOutputKeyClass(IntWritable.class); sortJob.setMapOutputValueClass(Text.class); sortJob.setSortComparatorClass(IntWritableDecreasingComparator.class); sortJob.setNumReduceTasks(1); //设定reduce数量,输出一个文件 sortJob.setOutputKeyClass(IntWritable.class); sortJob.setOutputValueClass(Text.class); // 输入及输出 FileInputFormat.addInputPath(sortJob, tempDir); FileSystem fileSystem = outDir.getFileSystem(conf); if (fileSystem.exists(outDir)) { fileSystem.delete(outDir, true); } FileOutputFormat.setOutputPath(sortJob, outDir); if (sortJob.waitForCompletion(true)) { System.out.println("finish job"); System.exit(0); } } }
- 添加降序比较类:在类ChineseWordSplit中添加降序比较类,在main函数中,串联了2个mapreduce job,第一个job使用中文分词工具将中文分词并统计,结果放在中间目录tempDir中,第二个job以前一个job为输入,将K-V反转,然后作降序排列,使用hadoop自带的InverseMapper类作为Mapper类,没有Reducer类,并需要一个排序比较类
private static class IntWritableDecreasingComparator extends IntWritable.Comparator { public int compare(WritableComparable a, WritableComparable b) { return -super.compare(a, b); } public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { return -super.compare(b1, s1, l1, b2, s2, l2); } }
4. 运行:
将项目打包为jar文件,保存到mapreduce目录:D:\Application\hadoop-2.7.4\share\hadoop\mapreduce,进入到bin目录,执行下面命令,3个参数分别表示文件输入,输出及中间目录
hadoop jar /D:\Application\hadoop-2.7.4\share\hadoop\mapreduce\hdfstest-1.0.jar examples/ChineseWordSplit hdfs://localhost:9000/input/people.txt hdfs://localhost:9000/output hdfs://localhost:9000/tmp
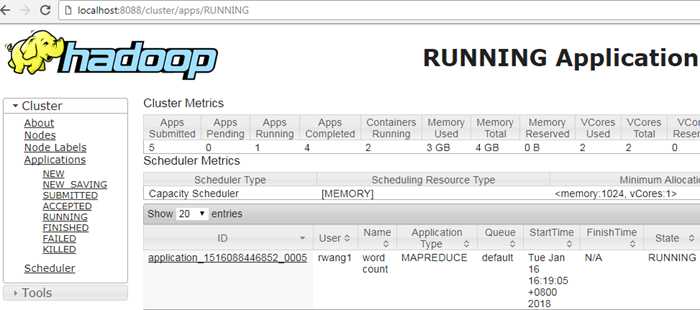
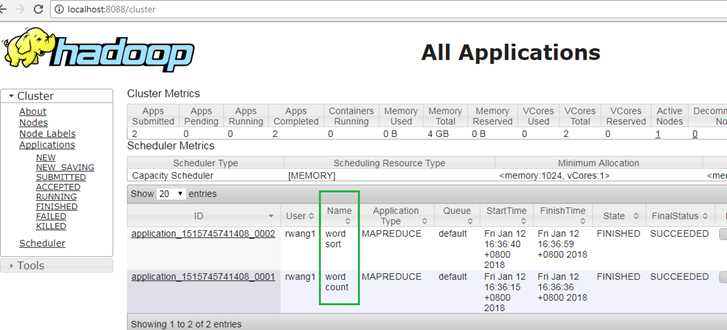
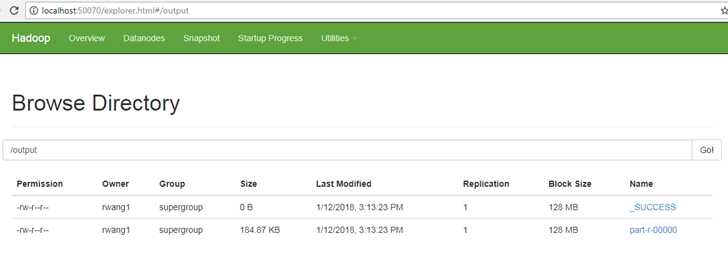
在浏览器中查看运行状态,可以看到有2个job:“word count”,“word sort”, 第二个job完成后,可以在hdfs输出目录看到文件
5:调试
- 方法一:本机MapReduce调试,以本地目录为输入输出
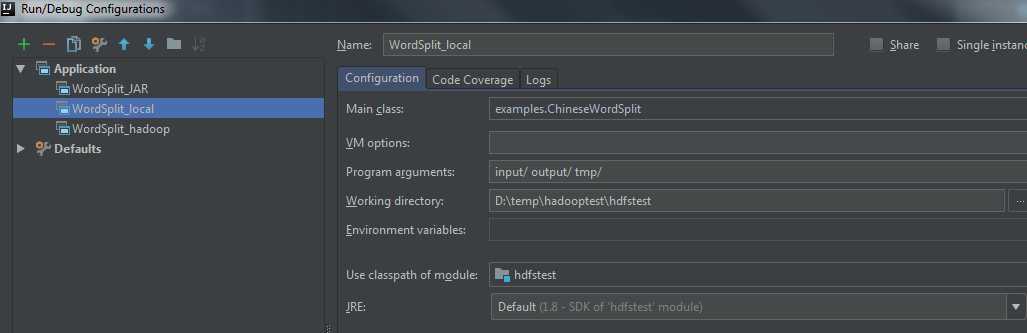
进入菜单 Run->Edit Configurations,添加Application,”WordSplit_local”,如下所示,此时可以直接在Idea中点击运行或调试按钮,不需要启动hadoop mapreduce
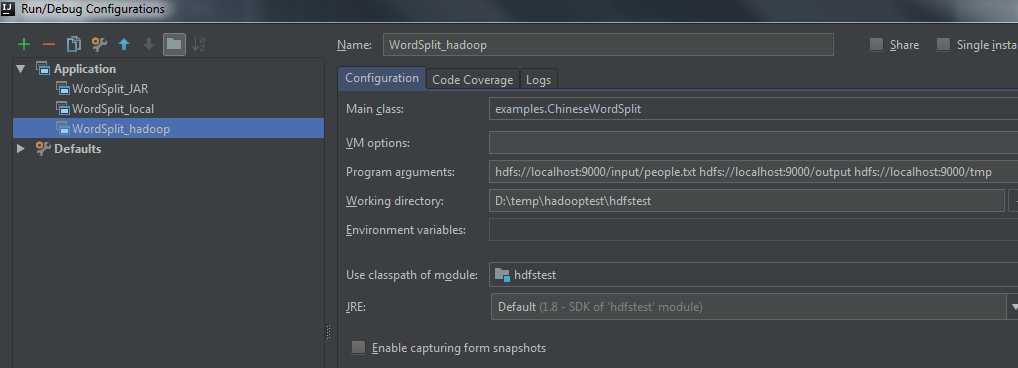
方法二:本机MapReduce调试,以本地hdfs目录为输入及输出
和上面类似,创建一个新的Application,只需修改Program arguments项, 配置为hdfs的文件目录,但运行或调试前,需要启动本地hadoop,在hadoop sbin命令行执行start-all.cmd 命令,这样可以访问并输出到hdfs中
在Mapper类中打上断点,调试时可以进入到map函数,如下图所示(特别注意,要在类中IntWritable行打上断点,我在调试时,如果不打上断点,无法进入到map函数)
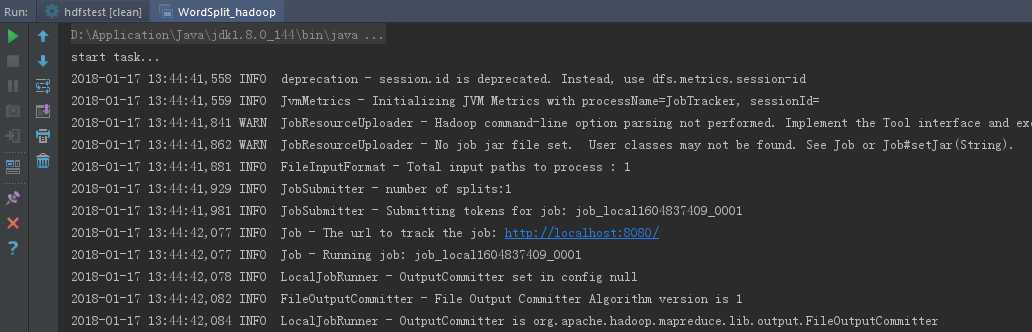
上述2个方法,是无法在浏览器中看到mapreduce job 状态的,只能调试map及reduce,并在输出目录查看运行结果,在控制台中可以看到,job 地址是:Job - The url to track the job: http://localhost:8080/,如果想提交到本地的mapreduce运行,请使用下面第3个方法
- 方法三:本地提交MapReduce,以hdfs目录为输入及输出
如果想在mapreduce中查看job的状态,可以添加如下代码,在代码中需要制定运行的jar包地址,此时,点击运行按钮,可以在mapreduce中看到job状态
Configuration conf = new Configuration(); //下述3行配置文件用于提交job到本地mapreduce运行,此时无法调试map及reduce函数 conf.set("mapreduce.framework.name", "yarn"); conf.set("yarn.resourcemanager.hostname", "localhost"); conf.set("mapreduce.job.jar", "D:\\temp\\hadooptest\\hdfstest\\target\\hdfstest-1.0.jar");