1. 如果不缺内存,如何使用一个具有库的语言来实现一种排序算法以表示和排序集合?
任何排序算法都可以,通常用快速排序。
2. 如何使用位逻辑运算 (如与、或、移位)来实现位向量?
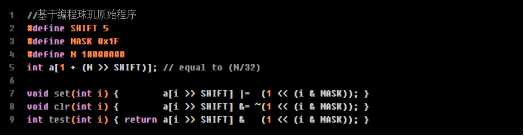
假如需要对N个不重复整数(最大值为N)进行排序,可以定义布尔类型的数组bool a[N]。当然本题目中使用Int[1+n/4]的思路与Bool类型数组的思想是完全一致的,只是置位和复位操作有些不同。使用位向量排序整数的方法通常用于不存在重复整数,且整数的最大值比较小(小于N)的情况下,比基于比较的排序算法O(NlogN)复杂度要好很多,为O(n)。
值得注意的是,这里int a[1+(n>>SHIFT)]是有一点点问题的,比如若n为0仍然会开辟一个Int,这是一种浪费。不仅如此,只要n为32的位数,就会多浪费一个Int空间。这是不必要的,所以可以改写为
3. 运行时效率是设计目标的一个重要组成部分,所得到的程序需要足够高效。在你自己的系统上实现位图排序并度量其运行时间。该时间与系统排序的运行时间以及习题1中排序的运行时间相比如何?假设n为1000000,且输入文件包含1000000个整数。
4. 如果认真考虑了习题3,你将会面对生成小于n且没有重复的k个整数的问题。最简单的方法就是使用前k个正整数。这个极端的数据集合将不会明显地改变位图方法的运行时间,但是可能会歪曲系统排序的运行时间。如何生成位于0至n-1之间的k个不同的随机顺序的随机整数?尽量使你的程序简短且高效。
生成随机数据,不必要真的通过随机生成,对于本题目正确的做法是打乱本来有序的数据。
5.那个程序员说他有1MB的可用存储空间,但是我们概要描述的代码需要1.25MB的空问。他可以不费力气地索取到额外的空间。如果1MB空问是严格的,你会推荐如何处理呢?你的算法的运行时间又是多少?
使用位图表示1000万个数需要1000万个位,或者说125(1000/8)万个字节Byte,由于1MB=1024*1024=1048576约为104万字节,所以实际上125万个字节Byte需要内存为大概1.25MB。
由于内存被严格限制在1MB以下,所以我们使用多路归并排序的思路来分解问题。把1000万分为前500万和后500万个数字,这样内存只需要大小约为0.52MB的空间来存储位向量,只不过重复两次来完成所有1000万个数字的排序任务。
此外,针对不同的范围可以使用k趟算法,每趟完成一定小范围区间内数字的排序任务后,再进行下一个小区间的数字排序,如此重复直到第k区间完成。这样能以近乎1/k的空间开销和k倍的时间开销,完成所有数字的排序。
注:原始待排序数据存储在外部文件中,第k趟的排序中,每次从文件读取一个数字判断其是否属于当前区间,若属于则进行当前区间的位向量置位操作,否则忽略它而直接读入下一个数字。第k趟的排序完成后,根据当前位向量将已排序后的数字信息输出到屏幕或者输出到排序后文件中。
6、如果那个程序员说的不是每个整数最多出现一次,而是每个整数最多出现10次,你又如何建议他呢?你的解决方案如何随着可用存储空问总量的变化而变化?
如果输入的数据是有重复的,那么有三种处理方案:(1)出错,如果发现当前输入的整数对应的位向量的位已经被置为1,意味着此前已经读入该数字,则此时报告出错。(2)忽略,如果发现当前输入的整数对应位向量的位置为1,则忽略当前数字。(3)统计该数字重复出现的次数:仅用一位二进制只能表示两种状态0和1,分别用于表示该数字出现与否,而不能标识该数字重复出现的次数。如果要记录重复次数,需要多于一位的二进制位数。
若每个整数最多重复出现10次,采用统计重复次数的方案,我们需要至少4位二进制(即半个byte)来记录每个输入整数的重复次数,因为4位二进制能记录0~15个数值而3个二进制位只能记录0~7数值。
这意味着每个数字在内存中不再是仅以1位来表示,而是需要4位,这需要腾出更多的内存用来存储重复的次数。设共有1000万个数字,则内存总空间需要4*1000万bit大约等于5MB内存。设内存仍被限制在1Mb,这样需要划分为5趟来完成。
7. [R.Weil]本书 1.4 节中描述的程序存在一些缺陷。首先是假定在输入中没有出现两次的整数。如果某个数出现超过一次的话,会发生什么?在这种情况下,如何修改程序来调用错误处理函数?当输入整数小于零或大于等于n时,又会发生什么?如果某个输入不是数值又如何?在这些情况下,程序该如何处理?程序还应该包含哪些明智的检查?描述一些用以测试程序的小型数据集合,并说明如何正确处理上述以及其他的不良情况。
如果某个数出现超过一次的话, 默认的算法会被忽略掉, 因为原来的程序只用1位二进制存储相应整数是否已经读入,1位二进制只能用来处理只出现一次或者一次都没出现的情况。
当输入整数小于零时,需要注意负数的移位运算中符号的变化情况,这可能与机器有关。设输入-1,那么a[-1]会访问越界。当输入整数大于等于n时,可能出现不同情况,假设N==30,这意味着需要4个int元素的数组,共32bits,此时读入一个整数值为31,31>N,但此时会访问第4个int的最后1位,不会导致明显的异常情况;若此时读入的是整数值35,则会导致int数组a[]访问越界。
如果某个输入不是数值,那么可能是字符、浮点数、字符串。如果是字符串,可以通过先读入字符串再通过atoi转换为整数,若失败则报告出错。当然,对于不合理的输入,我们可以直接报告出错,或者进行错误输入的忽略而读取下一个合法的输入整数。
for each i in input file Assert(i>=0 && i <= n) if(bit[i] = 1) error("duplicate data!"); bit[i] = 1; for i = [0,n] if(bit[i] == 1) write i to output file
8. 当那个程序员解决该问题的时候,美国所有免费电话的区号都是800。现在免费电话的区号包括800、877和888,而且还在增多。如何在1MB空间内完成对所有这些免费号码的排序?如何将免费电话号码存储在一个集合中,要求可以实现非常快速的查找以判定一个给定的免费电话号码是否可用或者己经存在?
号码由3位区号+7位号码组成,每个7位的十进制数字表示一个小于1000万的整数。区号为800,878,888等的是免费号码,每个免费号码前缀对应的号码共有1000万个,都可能是免费号码,对1000万个号码进行排序至少需要1.25MB内存空间。
若只给出空间限定而没给时间限定,则容易实现免费号码排序,可以分别对800,878,888等前缀对应的1000万个数进行排序(k趟),然后依次输出。这样需要分别存储多个位向量,每个向量保存一个免费号码前缀对应的1000万个号码的使用情况。这样做的弊端是可能某些前缀只有很少的免费号码,但是仍然开辟了4个int来存储位向量,造成浪费。
要求快速判定一个给定的号码是否为免费号码,首先根据区号快速定位到该区号对应的位向量,若果不能成功映射到位向量意味着该区号不是免费号码区号,这里使用的是散列的思想。若能成功定位到该前缀对应的位向量,则直接使用test(i)操作检查7位整数号码对应位是否被置位,实际上也是一种散列的思想,只不过是由位图实现的散列。
9. 使用更多空间来换取更少的运行时间存在一个问题:初始化空间本身需要消耗大量的时间。说明如何设计一种技术,在第一次访问向量的项时将其初始化为0。你的方案应该使用常量时间进行初始化和向量访问,使用的额外空间应正比于向量的大小。因为该方法通过进一步增加空间来减少初始化的时间,所以仅仅在空间上很便宜、时问很宝贵且向量很稀疏的情况下才考虑使用。
不会
10. 在成本低廉的隔日送达时代之前,商店允许顾客通过电话订购商品,并在几天后上门。商店的数据库使用客户的电话号码作为其检索的主关键字 (客户知道他们自己的电话号码,而且这些关键字几乎都是唯一的)。你如何组织商店的数据库,以允许高效的插入和检索操作?
电话号码从大到小进行编号,最前面数字可能代表运营商,次之可能代表城市之类。所以越靠前越可能重复,很多电话号码的前面都是一样的,比如手机号码都是以1开头的。根据电话号码的最后一位或者最后两位进行分类,位于最后的这些位数字分布是相当随机、均匀的,可以依靠这个性质对号码进行划分。
本题目中,为了加速查找需要对用户进行分组,需要考虑顾客用户数量来决定分组的数目和大小,这里我们设定分为100组,所以根据电话号码的后两位(每一位可以取0~9,所以两位数共10×10=100个可能的值)来决定某个号码唯一的属于某个组。这相当于根据电话号码的最后两位作为客户的哈希索引值,对号码进行分类,当顾客打电话下订单的时候,它被放置在对应类中。每个加入该类中的所有号码按照添加的顺序依次存储在合适的数据结构中(如链表或数组),这完全等同于使用散列的链表法来解决碰撞冲突,而100个值相当于100散列桶,每个桶内由链表顺序存储。当客户来取商品时,销售人员根据号码定位到散列桶,顺序搜索对应桶中的订单——这就是经典的 “用顺序搜索来解决冲突的开放散列”。
12. 载人航天的先驱们很快就意识到需要在外太空的极端环境下实现顺利书写。民间盛传美国国家宇航局(NASA)花费100万美元研发出了一种特殊的钢笔来解决这个问题。那么,前苏联又会如何解决相同的问题呢?
书中答案: 根据该传间,前苏联人用铅笔解决了这个问题。有关这个真实故事的背景请查看www.spacepen.com。Fisher Space Pen公司成立于1948年,其书写设各被俄国航天局、水底探测人员和喜马拉雅登山探险队使用过。
PS: 就算前苏联人使用铅笔,也不会是普通的铅笔。普通的铅笔使用石墨作为笔芯,写字的时候会出现粉尘或者笔芯会折断。这样石墨粉尘或者断了的笔芯在真空中漂浮,进入宇航员的眼睛或者仪器中(石墨会导电),有可能会引起一系列事故。
我们总是推崇小聪明,而不是从根本解决问题,这是不可取的。关于小聪明还有个流传很久的故事,工厂有条生产线,将肥皂放进盒子中,有时肥皂放不进盒子,就需要检测出空盒子。美国公司的做法是研制一些科技,比如扫描盒子是否为空,跟着使用机器人手臂将空盒子检出来。中国小工厂的做法是,在生产线中放个风扇,吹走空盒子。很多根据这个,就得出美国公司的做法太浪费钱,太笨。
我不知道那个故事是不是真的。美国公司的做法有个好处,是从根本解决了问题。当不是生成肥皂,改成生产其它东西,比如生成电饭锅了,它之前的解决方案可以移过来用。而中国那种小聪明做法作为权宜之计是很好的,但不值得过分推崇。
小聪明不是很通用,宁愿要一种笨笨的感觉。