《Learning Visual Clothing Style with Heterogeneous Dyadic Co-occurrences》论文阅读
Introduction
在推荐场景中,相似商品的i2i推荐一直是重要的基础数据,但只是推荐相似商品还是不够的,用户除了对相似商品的需求外还有对跨类目的搭配商品的需求。这篇文章介绍的就是基于商品图像的搭配推荐。
本文的主要思想是通过学习一个feature transformation将商品的图像信息映射到latent space上,这个latent space就是用于表达搭配特性的。这个latent space即style space,即本文的一个重要前提假设是将计算商品的搭配特性转化为计算商品的style信息,具有相同或相似style的商品是相互搭配的。在这个style space上,搭配的商品即使不属于同一个类目,距离也很接近。
1. feature transformation是使用的Siamese Convolutional Neural Network,training sample是搭配和不搭配的商品pair对。
2. 对搭配特性建模的方式是使用了商品的co-occurrence信息,尤其是co-purchase信息。即本文的另外一个重要假设:如果两个商品被用户同时购买(或者被同一个用户购买)的频率较高则说明他们搭配。即商品的共现信息决定了其在latent space上的分布情况。这是模型训练和评估时的主要思想。但这样做的主要问题在于数据的稀疏性和噪音。
3. 为了进行跨类目的搭配建模,sample时候的正样本pair对采样的是属于不同high-level categories的商品。
Framework
1. input data包括商品的图像、类目、co-occurrence信息。
2. 从input data中采样正样本,即不同类目下co-occurrence高的商品pair。
3. 使用Siamese CNN去学习一个feature transformation将商品的图像信息映射到latent space上。
4. 在预测时将商品图像transform到latent space上,找到nearest neighbors。
Related work
主要有两方面:
1. CNN:Learning visual similarity for product design with convolutional neural networks
2. Learning clothing style:Image-based Recommendations on Styles and Substitutes
Dataset
使用用户的行为数据,包括商品的图像、类目、co-occurrence信息。
只使用了“衣服、鞋子、首饰”这三大类的商品。
对商品的类目信息,选择high-level的,优点一是high-level category是独立于style的,即避免类目划分过细时某些小类目跟style强相关对样本选择情况有影响;二是这样避免商品的类目变换较频繁。最后需要看一下类目的分布情况。
Generating the training set
1. training、validation、test data中的商品类目比例要成正比。
2. negative sample随机采样,正负样本比例1:16。
3. training data中的不同类目的商品数不能差距太大。
4. strategy:CNN倾向于将图像相似的商品映射到相近的向量空间上,为了避免这个问题,强制使用不同high-level类目下的商品pair作为正样本,这样能够使得不同类目图像不相似但style相似的商品closer;负样本需要包含类目相同或不相同的pair,使得能够区分出那些类目相同图像相似但不属于相似style的商品。
Training the Siamese network
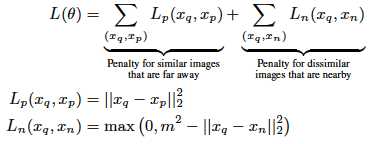
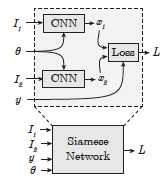

即对于每个category,都聚类成若干个cluster,算最邻近时,先找最邻近的cluster center,再在这个cluster中找最邻近商品。
最后,下图是一些style相似和不相似的例子。
