1. 如果 Spark 中 CPU 的使用率不够高,可以考虑为当前的程序分配更多的 Executor, 或者增加更多的 Worker 实例来充分的使用多核的潜能
2. 适当设置 Partition 分片数是非常重要的,过少的 Partition 分片数可能会因为每个 Partition 数据量太大而导致 OOM 以及频繁的 GC,而过多的 Parition 分片数据可能会因为每个 Partition 数据量太小而导致执行效率低下。
3. 提升 Spark 硬件尤其是 CPU 使用率的一个方式 就是增加 Executor 的并行度,但是如果 Executor 过多的话,直接分配 在每个 Executor的内存就大大减少,在内存的操作就减少,基于磁盘的操作就越来越多,导致性能越来越差。
4. 处理 Spark Job 的时候如果发现比较容易内存溢出,一个比较有效的办法是减少并行的 Executor 的数量,这样每个 Executor 就可以分配到更多的内存,进而增加每个 Task 使用的内存数量,降低 OOM 的风险。
5. 处理Spark Job 的时候如果发现比较容易内存溢出,一个比较有效的办法就是增加 Task 的并行度,这样每个 Task 处理的 Partition 的数量就变少了,减少了 OOM的可能性。
6. 处理Spark Job 的时候如果发现某些 Task 运行得特别慢,一个处理办法是增加并行的 Executor 的个数,这样每个 Executor 分配 的计算资源就变少了,可以提升硬件的整体使用效率。另一个办法是增加 Task 的并行度,减少每个 Partition 的数据量来提高执行效率。
7. 处理Spark Job 的时候如果出现特别多的小文件,这时候就可以通过 coalesce 来减少 Partition 的数量,进而减少并行运算的 Task 的数量来减少过多任务的开辟,从而提升硬件的使用效率。
8. 默认情况下 Spark 的 Executor 会尽可能占用当前机器上尽量多的 Core,这样带来一个好处就是可以最大化的提高计算的并行度,减少一个 Job 中任务 运行的批次,但带来一个风险就是如果每个 Task 占用内存比较大,就需要频繁的 spill over 或者有更多的 OOM 的风险。
9. Spark 集群在默认情况每台 host 上只有一个 Worker, 而每个 Worker 默认只会为当前应用程序分配一个 Executor来执行 Task,但实际上通过配置 Spark-env.sh 可以让每台 host 上有若干的 Worker, 而每个 Worker 下面又可以有若干个 Executor。
10。 Spark Stage 内部是一组计算逻辑完全相同但处理数据不同的分布式并行运行的 Task 构成, Stage 内部的计算都以 Pipeline 的方式进行,不同的 Stage之间是产生 Shuffler 的唯一方式。
11. 在Spark 中可以考虑在 Worker 节点上使用固态硬盘以及把 Worker 的 Shuffle 结构保存到 RAMDisk 的方式来极大的提高性能。
12. 当经常发现机器频繁的 OOM 的时候,可以考虑的一种方式就是减少并行度,这样同样的内存空间并行运算的任务 少了,那么对内存的占用就更少了,也就减少了 OOM 的可能性。
Spark 性能优化核心基石:
1. Spark 采用的是 Master-Slaves 的模式进行资源管理和任务 执行的管理:
a) 资源管理: Master-Workers, 在一台机器上可以有多个 Workers
b) 任务执行: Driver-Executors,当在一台机器上分配多个 Workers 的时候那么默认情况下每个 Worker 都会为当前运行的应用程序分配一个 Executor,但是我们可以修改配置来让每个 Worker 为我们当前的应用 程序分配若干个 Executors; 程序运行的时候会被划分成为若干个 Stages(Stages内部没有 Shuffle,遇到 Shuffle 的时候会划分 Stage),每个 Stage里面包含若干个处理逻辑完全一样只是处理数据不一样的 Task, 这些 Task 会被分配到 Executor 上去并行执行。
Spark 性能优化招式:
1. Broadcast。如果 Task 在运行的过程中使用超过 20KB 大小的静态大对象,这个时候一般都要考虑使用 Broadcast。例如一个大表 Join 一个小表,此时如果使用 Broadcast 把小表广播出去,这时候大表就只需在自己的节点等待小表数据的到来。
Task 性能优化:
1. 慢任务的性能优化:可以考虑减少每个 Partition 处理的数据量。同时建议开启 spark.speculation。
2. 尽量减少 Shuffle, 例如我们要尽量减少 groupByKey 操作,因为 groupByKey 会要求通过网络拷贝(shuffle) 所有的数据,优先考虑使用 reduceByKey。因为 reduceByKey 会首先 reduce locally,然后再拷贝。
数据倾斜
1. 定义更加合理的 Key(或者说自定义 Partitioner)
2. 可以考虑使用 ByteBuffer 来存储 Block
网络
1. 可以考虑 Shuffle 的数据放在 alluxio (前身 Tackyon) 中带来更好的数据本地性,减少网络的 Shuffler
2. 优先采用 Netty (Spark 2.X 的默认方式)的方式进行网络通信
3. mapPartitions 中的函数在一个 Partition 里作用一次
数据结构:
1. Java的对象。对象头是16个字节(例如指向对象的指针等元数据),如果对象中只有一个 int 的 property,则此时会占据 20 个字节,也就是说对象的元数据占用了大部分的空间,所有在封装数据的时候尽量不要使用对象。例如说使用 Json 格式来状封装数据
2. Java 的 String 在实际占用内存方面要额外使用 40 个字节(内部使用 char 数组来保存字符),另外需要注意的是 String 中每个字符是2个字节(UTF-16),如果内部有5个字符的话,实际上会占用50个字节。
3. Java中的集合List、Map 等等,其内部一般使用链表来实现。具体的每个数据使用 Entry 等,这些也非常消耗内存
4. Java 中的基本数据类型会自动封箱操作,这会额外增加对象头的空间占用。
5. 优先使用原生数据,尽可能不要直接使用 ArrayList、HashMap、LinkedList 等数据结构
6. 优先使用 String (推荐使用 JSON),而不是采用 HashMap、List 等来封装数据
内存消耗诊断
1. JVM 自带的诊断工具。例如: JMap、JConsole等
2. 在开发、测试、生产环境下用的最多的是日志。 Driver 端产生的日志,最简单也是最有效的方式就是调用 RDD.cache,当进行 cache 操作的时候, Driver 上的 BlockManangerMaster 会记录该信息并写进日志中。
persist 和 checkpoint
1. 当反复使用某个(些)RDD的时候,建议使用 persist 来对数据进行缓存
2. 如果某个步骤的 RDD 计算特别耗时或者经历了很多步的计算,数据丢失的话则重新计算的代价比较大,此时考虑使用 checkpoint,因为 checkpoint 是把数据写入 HDFS 的,天然具有高可靠性
序列化和反序列化
发送磁盘IO 和网络通信的时候会序列化和反序列化,更为重要的考虑序列化和反序列化的时候有另外两种情况:a) Persist 的时候 b)编程的时候。使用算子的函数操作如果传入了外部数据就必须序列化和反序列化
1. Spark 的序列化机制默认使用 Java 自带的序列化机制(其实现类是 ObjectInputStream 和 ObjectOutputStream)。效率较低,强烈建议使用 Kryo 序列化机制 ,它比 Java 的序列化节省近 10 倍的空间。
2. Spark 中如果我们自定义了 RDD 中的数据元素的类型,则必须实现 Serializable 接口,也可以实现自己的序列化接口(Externalizable)来实现更高效的 Java序列化算法。如果使用 Kryo,则需要把自定义的类注册给 Kryo。
3. Spark 中 Scala 常用的类型自动的能过 AllScalaRegistry 注册给了 Kryo 进行序列化管理。
4. Kryo 在序列化的时候缓存空间默认大小是 2MB,可以根据具体的业务模型调整该大小,通过设置 spark.kryoserializer.buffer
5. 在使用 Kryo 的时候,强烈建议注册时写完整的包名和类名。
数据本地性
1. 如果数据是 PROCESS_LOCAL, 但是此时并没有空闲的 Core 来运行我们的 Task,此时 Task 就要等待。例如等待3000ms, 3000ms 内如果 Task 不能运行,则退而求其次采用 NODE_LOCAL。同样的道理 NODE_LOCAL也会有等待时间。
2. 如何配置 Locality呢? 可以统一采用 spark.locality.wait 来设置。也可以分别设置如: spark.locality.wait.node、spark.locality.wait.process 。
RDD 的自定义(以 Spark on HBase 为例)
1. 第一步是定义 RDD.getParitions 的实现
a) createRelation 具体确定 HBase 的链接方式和具体访问的表
b) 然后通过 HBase 的API 来获取 Region 的 List
c) 可以过滤出有效的数据
d) 最后返回 Region 的 Array[Partition],也就是说一个 Partition处理一个 Region 的数据,为更佳的数据本地性打下基础
2. 第二步是 RDD.getPreferredLocations
根据 Split 包含的 Region 信息来确定 Region 具体在什么节点上。这样 Task 在调度的时候就可以优先被分配到 Region 所在的机器上,最大化地提高数据本地性
3. 第三步是 RDD.compute
根据 Split 中的 Region 等信息调用 HBase 的 API 来进行操作(主要是查询)
Shuffle 性能调优
1. 问题: Shuffle output file lost? 真正的原因一般由 GC 导致的。GC 尤其是Full GC 时通常会导致线程停止工作,这个时候下一个 Stage 的 Task 在默认情况下就会尝试重试来获取数据,一般重试3 次,每次重试时间间隔为5S,也就是说默认情况下 15S 内如果还是无法抓到数据的话,就会出现 Shuffle output file lost 等 情况 ,进而导致 Task重试,甚至会导致 Stage 重试,最严重的是会导致 App 失败。在这个时候首先就要采用高效的内存数据结构和序列化机制,JVM 的调优来减少 Full GC 的产生。
2. 在 Shuffle 的时候, Reducer 端获取数据会有一个指定大小的缓存空间,如果内存不够,可以适当的增大该缓存空间(通过调整 spark.reducer.maxSizeInFlight),否则会 Spill 到磁盘上,影响效率
3. 在 Shuffle MapTask 端通常也会增大Map 任务的写磁盘的缓存。默认值是32K.
4. 调整获取 Shuffle 数据的重试次数,默认是3次,通常建议增大重试次数
5. 调整获取 Shuffle 数据的重试时间间隔,默认是5秒。强烈建议提高该时间。
(个人觉得以上两点可以看出,默认情况下会有 15 秒的时间,如果GC需要这么长的时间的话,应该是GC的问题,首先应该是优化GC)
6. 在 Reducer 端做 Aggregation 的时候,默认是 20% 的内存用来做 Aggegation。如果超出了这个大小就会溢出到磁盘上,建议调在百分比来提高性能。
钨丝计划
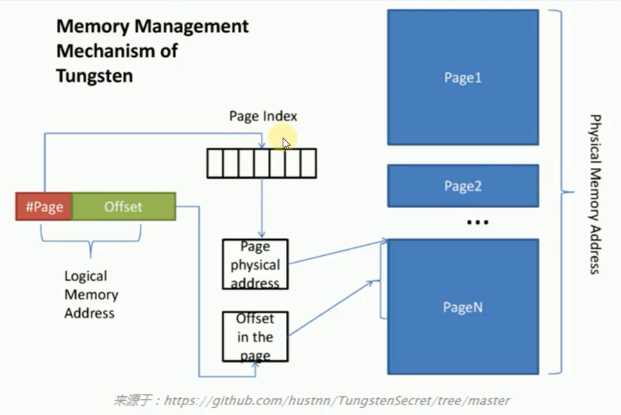
1. Tungsten 的内存管理 机制独立于 JVM, 所以Spark 操作数据的进候具体操作的是 Binary Data,而不是 JVM Object。而且还免去了序列化和反序列化的过程。
2. 内存管理方面: Spark 使用了 sum.misc.Unsafe 来进行 Off-heap 级别的内存分配、指针使用及内存释放。Spark 为了统一管理 Off-heap 和 On-heap 而提出了 Page
3. 如果想让程序使用 Tungsten 功能,可以配置 spark.shuffle.manager=tungsten-sort
4. DataFrame 中自动开启了 Tungsen 功能
5. 写数据在内存足够大的情况下是写到 Page 里面,在 Page 中有一条条的 Record,如果内存不够的话会 Spill 到磁盘上。
如何看内存是否足够?两方面:
a) 系统默认情况下给 ShuffleMapTask 最大准备了多少内存空间。默认情况下是 ExecutorHeapMemory * 0.8 * 0.2
(spark.shuffle.memoryFraction=0.2, spark.shuffle.safetyFraction=0.8)
b) 和 Task 处理的 Partition 大小紧密相关