1.行的开始和结束
元素组成部分:metacharacters & literal (元字符和普通字符)。
1.1 ^: 一行的开头。
1.2 &: 一行的结束。
1.3 ^cat&:行开头, 然后匹配cat, 行结尾(没有多余的单词、空白字符 )。
1.4 ^&:空行(没有任何字符,包括空白字符)。
1.5 ^:行开头。
2.字符组
2.1 [···]:中括号内部列出期望匹配的字符。
2.2 [123456]:匹配1到6,里面匹配是或的意思。
2.3 [1-6]:同样匹配1-6,其中的-是字符组元字符(在字符组内部-->字符组元字符)。
注意:只在字符组内部且不是第一个元素,连字符才是元字符,否则它就只能普通的连字符号。
3.排除型字符组
3.1 用[^123]取代[123],代表除了123以外的其他元素,其中的^代表排除的意思。
3.2 q[^u]是匹配字母q后不是u的情况,但是我们要考虑到一些问题,就是q可能是大写的Q,所以建议我们直接用[Qq][^u]。还有就是q正好位于行尾,紧跟着的会是换行符,如果正则没有保留换行符,那么q之后就没有元素,同样匹配不到(一个字符组,就算是排除型字符组,也需要匹配一个字符)。
3.3 [^x]:匹配一个不是x的字符,而不是说,只有当这个位置不是x时才能匹配(刚刚说的正好在行尾的情况)。
注意:这里的^表示排除之意,与之前在字符组外部表示行锚点的^不同,这里的^是一个元字符(在字符组内部且紧跟首个方括号之后)。
4.点符号匹配任意字符
4.1 .:匹配任意字符
比如03/19/76,03-19-76,03.19.76,要匹配这些,我们不嫌麻烦可以这样 03[-./]19[-./]76,其实可以简单这样匹配 03.19.76。但是这样还会出现问题,他甚至会匹配到03319 76,这一点上显然没有前者精确,这就需要我们在检索精确度和文档了解度之前权衡。其实可以通过转义字符把元字符转化为普通的字符,从而更精确的匹配,后文会讲到。
注意:点符号并不是元字符,因为它在字符组内部。在字符组里面和外面,元字符的定义和意义是不一样的,这里的-同样不是连字符,因为它虽然位于字符组内,但是是在首个元素位置。
如果这样写[.-/],那就代表元字符了,用来表示范围,但是这样写明显是错误的用法。
5.多选结构
5.1 |:元字符,或的意思。依靠该字符可以把任意的正则表达式组合成一个总的表达式,并且总表达式可以匹配其中的任意子表达式。
例如gr[ea]y可以写作grey|gray或gr(e|a)y,其中括号用来划定多选结构的范围(正常情况下,括号也是元字符 )。
注意:gr[e|a]y不符合我们的要求,因为在这里|只是一个普通字符。
在这里,gr[ea]y和gr(e|a)y表示的意思一样,不要认为多选结构和字符组一样,一个字符组只能匹配目标文本中的单个字符,但是多选结构自身都可以是完整的正则表达式,都可以匹配任意长度的文本。
还有一点需要注意,就是多选结构和^和$一起使用的时候。
5.2 ^From|Subject|Data:*:匹配的是^From,Subject,Data:*。
5.3 ^(From|Subject|Data):*:匹配一行的起始位置,然后是From,Subject,Data任意一个,最后匹配:*。
6.忽略大小写
6.1 egrep命令中加入-i参数即可,比如我们不对From区分大小写,那总不能这样写[Ff][Rr][Oo][Mm],这样显然繁琐,只需要忽略大小写即可。
7.单词分界符
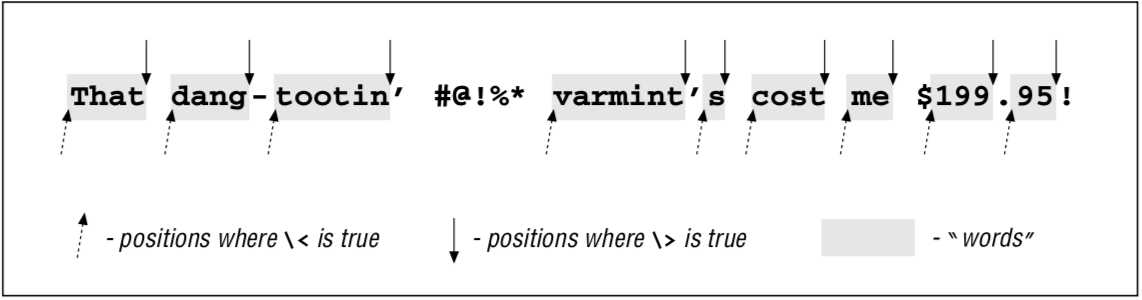
7.1 \<和\>:单词分界符,匹配单词分界的位置。由于单个<和>并不是元字符,因此类似这种称为metasequences(元字符序列)。
下图所示,单词开头位置用向上的箭头标识,单词结束的位置用向下的箭头标识。
8.小结
我们总结一下到目前为止学到的元字符
| 元字符 | 名称 | 匹配对象 |
|---|---|---|
| . | 逗号 | 单个任意字符 |
| [···] | 字符组 | 列出的任意字符 |
| [^···] | 排除型字符组 | 未列出的任意字符 |
| ^ | 脱字符 | 行的起始位置 |
| $ | 美元符 | 行的结束位置 |
| < | 反斜杠-小于 | 单词的起始位置(某些版本的egrep可能不支持) |
| \> | 反斜杠-大于 | 单词的结束位置(某些版本的egrep可能不支持) |
| | | 竖线 | 匹配分隔两边的任意一个表达式 |
| (···) | 括号 | 限制竖线的作用范围,其他功能下文论述 |
9.可选元素
9.1 x?:代表x元素可有可无,不会匹配失败。
9.2 colou?r:匹配color或则colour。
假如匹配英语中的7月4日(July fourth),7可以是July,也可以简写为Jul,4可以是fourth、4th和4。我们可以使用(July;Jul) (fourth;4th;4)也可以使用July? (fourth|4(th)?)
10.其他量词:重复出现
10.1 +:之前紧邻的元素出现一次或多次,如果连一次都没有匹配成功,就匹配失败。
10.2 *:前紧邻的元素出现任意多次或不出现,和?一样,不会匹配失败。
像?、+、*这些统称为量词,因为他们限定了所作用元素的匹配次数。
表示重复的元字符总结
| ···· | 次数下限 | 次数上限 | 含义 |
|---|---|---|---|
| ? | 无 | 1 | 可以不出现,也可以只出现一次(单词可选) |
| * | 无 | 无 | 可以出现无数次,也可以不出现(任意次数均可) |
| + | 1 | 无 | 可以可以出现无数次,但至少要出现一次(至少一次) |
规定重现次数的范围:区间
10.3 ···{min,max}:区间量词。问号对应的区间量词是{0,1}。
10.4 [a-zA-z]{1,5}:匹配美国的股票代码(1到5个字母)。
当然并不是所有的egrep都支持。
11.括号及反向引用
到目前为止,我们见识过括号的两种用途:限制多项式的范围;将如干个字符组合为一个单元,受问号和星号之类量词的作用。现在介绍另外一种用途,反向引用。比如我们匹配重复的单词,使用the the,这样可能还是会匹配到the theory这种,其实使用\<the the\>倒是可以解决这个问题。但是重复单词就不止这一个,穷举显示不现实。于是我们想着匹配所有重复单词,首先匹配一个单词,让后面匹配的单词和先前匹配同样的单词即可。
11.1 \<([A-Za-z]+) +\1\>:匹配重复单词(记得加上-i参数忽略大小写),其中第一个单词使用括号括起来,再跟上一个特殊的元字符序列\1。
当然,在一个表达式中我们可以使用多个括号。\1、\2、\3等来表示第一、第二、第三组括号匹配的文本。括号是按照开括号(从左至右的出现顺序进行的,所以([a-z])([0-9])\1\2中的\1代表[a-z]匹配的内容,而\2代表[0-9]匹配的内容。
另外,该表达式虽然很有用,但是,我们要知道它的局限性,重复的单词第一个位于某行末尾,第二个在下一行的开头,这个表达式就无法找到。
12.转义
12.1 ega\.att\.com:匹配ega.att.com,把本来是元字符的.转化为普通字符。
12.2 \([a-zA-Z]+\):用来匹配一个括号内的单词。