import torch
import torch.nn.functional as F
from torch.autograd import variablex = Variable(torch.Tensor([1]), requires_grad = True)
w = Variable(torch.Tensor([2]), requires_grad = True)
b = Variable(torch.Tensor([3]), requires_grad = True)requires_grad = False(default)
默认是不对其求梯度的,除非声明为True
y = w * x + b
# y = 2 * 1 + 3
y.backward()y.backward就是自动求导
print(x.grad)
print(w.grad)
print(b.grad)Variable containing:
2
[torch.FloatTensor of size 1]
Variable containing:
1
[torch.FloatTensor of size 1]
Variable containing:
1
[torch.FloatTensor of size 1]x = Variable(torch.Tensor([0]), requires_grad = True)
w = Variable(torch.Tensor([2]), requires_grad = True)
b = Variable(torch.Tensor([5]), requires_grad = True)
y = w*x*x + b
y.backward(torch.FloatTensor([1]))
print(x.grad)Variable containing:
0
[torch.FloatTensor of size 1]x = Variable(torch.randn(3), requires_grad = True)
print(x)Variable containing:
-0.9882
-1.1375
-0.4344
[torch.FloatTensor of size 3]y = 2*x
y.backward(torch.FloatTensor([1,1,1]))
print(x.grad)Variable containing:
2
2
2
[torch.FloatTensor of size 3]grad can be implicitly created only for scalar outputs you have to explicitly write torch.FloatTensor([1,1,1])
y.backward(torch.FloatTensor([0.1, 0.2, 0.3]))
print(x.grad)Variable containing:
2.2000
2.4000
2.6000
[torch.FloatTensor of size 3]gradient will accumulate somehow
two ways of saving a model
save both the model and the parameters
torch.save(model, ‘./model.poth‘)save only the parameters (save the state of the model)
torch.save(model.state_dict(), ‘./model_state.pth‘)
two ways of loading a model
- load both model and parameters
load_model = torch.load(‘model.pth‘) - load only parameters
????
import matplotlib.pyplot as plt
import numpy as npx_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)plt.scatter(x_train, y_train, )<matplotlib.collections.PathCollection at 0x10b695f28>
#首先把numpyarray类型的数据转换成torch.tensor,使用torch.from_numpy方法
x_train = torch.from_numpy(x_train)
y_train = torch.from_numpy(y_train)class LinearRegression(torch.nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1)
# basicly this is x*w+b=y
def forward(self, x):
out = self.linear(x)
return out# class LinearRegression(torch.nn.Module):
# def __init__(self, input_num, hidden_num, output_num):
# super(LinearRegression, self).__init__()
# self.linear1 = nn.Linear(input_num, hidden_num)
# self.linear2 = nn.Linear(hidden_num, output_num)
# # basicly this is x*w+b=y
# def forward(self, x):
# x = F.relu(self.linear1(x))
# out = (self.linear2(x))
# return outif torch.cuda.is_available():
model = LinearRegression().cuda()net = LinearRegression()
print(net)LinearRegression(
(linear): Linear(in_features=1, out_features=1)
)criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr = 1e-3)num_epochs = 100
for epoch in range(num_epochs):
if torch.cuda.is_available():
inputs = Variable(x_train).cuda()
target = Variable(y_train).cuda()
else:
inputs = Variable(x_train)
target = Variable(y_train)
# forward
out = net(inputs)
loss = criterion(out, target)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if(epoch + 1) % 20 == 0:
print(‘epoch[{}/{}], loss: {:.6f}‘.format(epoch+1, num_epochs, loss.data[0]))
# loss is a Variable, by calling data, we get the data of the Variableepoch[20/100], loss: 0.300034
epoch[40/100], loss: 0.298694
epoch[60/100], loss: 0.297367
epoch[80/100], loss: 0.296054
epoch[100/100], loss: 0.294755net.eval() # evaluate mode
predict = net(Variable(x_train))
predict = predict.data.numpy()
plt.scatter(x_train.numpy(), y_train.numpy())
plt.plot(x_train.numpy(), predict, )
plt.show()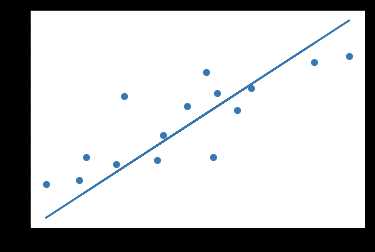
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)
y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)
x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)
y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating
# print(x.numpy().shape)
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integerplt.scatter(x.numpy()[:,0], x.numpy()[:,1], c = y)<matplotlib.collections.PathCollection at 0x10d1b4dd8>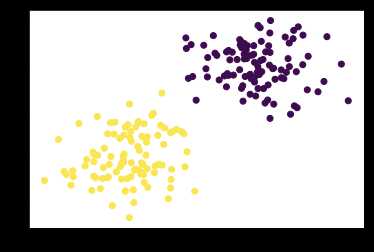
class LogisticRegression(torch.nn.Module):
def __init__(self, input_num, hidden_num, output_num):
super(LogisticRegression, self).__init__()
self.hidden = torch.nn.Linear(input_num, hidden_num)
self.output = torch.nn.Linear(hidden_num, output_num)
def forward(self, x):
x = torch.nn.functional.relu(self.hidden(x))
out = self.output(x)
return xnet = LogisticRegression(2, 10, 2)
print(net)LogisticRegression(
(hidden): Linear(in_features=2, out_features=10)
(output): Linear(in_features=10, out_features=2)
)criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr = 1e-1)if torch.cuda.is_available():
inputx = Variable(x).cuda()
targety = Variable(y).cuda()
else:
inputx = Variable(x)
targety = Variable(y)
num_epochs = 1000
for epoch in range(num_epochs):
# forward
out = net(inputx)
loss = criterion(out, targety)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 40 == 0:
print(‘Epoch[{}/{}], loss: {:.6f}‘.format(epoch, num_epochs, loss.data[0]))
# if epoch % 20 == 0:
# plot and show learning process
plt.cla()
prediction = torch.max(out, 1)[1]
# print(prediction.data.numpy().shape)
pred_y = prediction.data.numpy().squeeze()
# print(pred_y.shape)
target_y = y.numpy()
plt.scatter(x.numpy()[:, 0], x.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap=‘RdYlGn‘)
accuracy = sum(pred_y == target_y)/200.
plt.text(1.5, -4, ‘Accuracy=%.2f‘ % accuracy, fontdict={‘size‘: 20, ‘color‘: ‘red‘})
# plt.pause(0.1)
# plt.ioff()
plt.show()Epoch[0/1000], loss: 3.279978
Epoch[40/1000], loss: 0.165580
Epoch[80/1000], loss: 0.085501
Epoch[120/1000], loss: 0.059977
Epoch[160/1000], loss: 0.047022
Epoch[200/1000], loss: 0.039068
Epoch[240/1000], loss: 0.033637
Epoch[280/1000], loss: 0.029672
Epoch[320/1000], loss: 0.026636
Epoch[360/1000], loss: 0.024226
Epoch[400/1000], loss: 0.022261
Epoch[440/1000], loss: 0.020624
Epoch[480/1000], loss: 0.019237
Epoch[520/1000], loss: 0.018045
Epoch[560/1000], loss: 0.017008
Epoch[600/1000], loss: 0.016096
Epoch[640/1000], loss: 0.015287
Epoch[680/1000], loss: 0.014565
Epoch[720/1000], loss: 0.013916
Epoch[760/1000], loss: 0.013329
Epoch[800/1000], loss: 0.012795
Epoch[840/1000], loss: 0.012310
Epoch[880/1000], loss: 0.011866
Epoch[920/1000], loss: 0.011458
Epoch[960/1000], loss: 0.011080
net.eval()
xx = np.linspace(-4,4,10000).reshape(10000, 1)
yy = 4*np.sin(xx*100).reshape(10000, 1)
xy = np.concatenate((xx, yy), axis = 1)
xy = torch.from_numpy(xy).type(torch.FloatTensor)
xy = Variable(xy)
pred = net(xy)
# print(pred.data.numpy().shape)
# print(pred[:6, :])
pred = torch.max(pred, 1)[1]
# print(len(pred))
# print(len(pred))
# print(pred.data.numpy().shape)
# print(pred[:6])
pred = pred.data.numpy().squeeze()
plt.scatter(xy.data.numpy()[:, 0], xy.data.numpy()[:, 1], c = pred, s = 100, lw = 0, cmap = ‘RdYlGn‘)
plt.show()