HBase简介:
HBase---Hadoop DataBase,是一个高可靠、高性能、面向列、可存储、实时读写的分布式数据库
利用HBase HDFS作为其文件存储系统
HBase数据模型:
(1)RowKey:
决定一行数据,按照字典顺序排序,RowKey只能存储64K字节数据
(2)Column Family列族 & qualifier列:
HBase表中某个列都归属某个列族,列族必须作为表模式(schema)定义的一部分预先给出。
列名以列族作为前缀,每个列族都可以有多个列成员(cloumn)
HBase把同一列族里面的数据存储在统一目录下,由几个文件保存
(3)Timestamp时间戳
在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面;
时间戳的类型是64位整型
时间戳可以由HBase(在数据写入时自动赋值)此时时间戳是精确到毫秒的当前系统时间
时间戳也可以由客户显示赋值,如果应用程序之间要避免数据版本冲突,就必须自己生成具有唯一性的时间戳
(4)Cell单元格
由行和列的坐标交叉决定;单元格是有版本的;单元格的内容是未解析的字节数组
(5)HLog(WAL Log)
HLog文件就是一个普通的Hadoop Sequence File,Sequence File的key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了Table和Region名字外,同时还包括sequence number和timestamp,“timestamp”是写入时间;
sequence number的起始值为0,或者是最近一次存入文件系统中sequence number
HLog SequenceFile的Value是HBase的keyValue是HBase的KeyValue对象,即对应HFile中的KeyValue
HBase体系架构
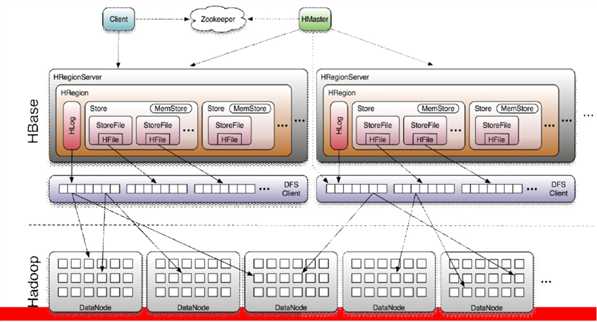
(1)Client
包含访问HBase的接口并维护cache来加快对HBase的访问
(2)Zookeeper
保证任何时候,集群中只有一个Master处于active状态
存储所有Region的寻址入口
实时监控Region Server的上下线信息,并实时通知Master
存储HBase的schema和table元数据信息
(3)Master
为Region Server分配region
负责Region Server的负载均衡
发现失效的Region Server,并重新分配失效Region Server上的Region
管理用户对table的增删改操作
(6)Region Server
Region Server维护region,处理对这些region的IO请求
Region Server负责切分在运行过程中变得过大的Region
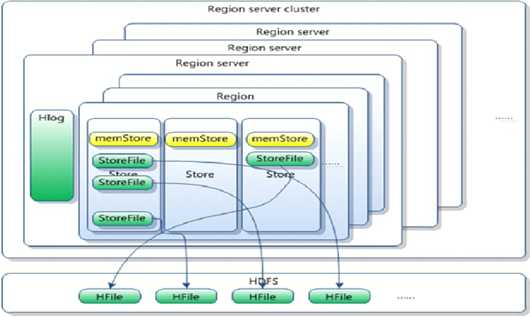
(7)Memstore和storefile
一个region由多个store组成,一个store对应一个CF;
store包括内存中的memstore和位于磁盘的storefile,写操作先写入memstore,当memstore中的数据达到某个阈值时,hregionserver会启动flushcache进程写入storefile,每次写入形成一个单独的storefile
当storefile文件数量增长到一定阈值的时候,系统会进行minor、major compaction,在合并过程中会进行版本合并和删除工作,形成更大的storefile
当一个region中所有storefile的大小和数量超过一定阈值的时候,会把当前的region分割为两个,并由hmaster分配到相应的regionserver上,实现负载均衡
客户端检索数据,先在memstore上找,找不到再去storefile中找
HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同HRegion可以分布在不同HRegion Server上面
HBase Compaction
主要有Minor Compaction和Major Compaction
Minor Compaction:指选取一些小的、相邻的storefile将他们合并成更大的StoreFile,在这个过程不会处理Delete或者Expired的Cell
Major Compaction:指将所有的StoreFile合并成一个StoreFile,在这个过程中会有清理三类无意义数据:被删除的数据,TTL过期的数据,版本号超过设定版本的数据,整个过程会消耗大量的系统资源
Compaction就是使用短时间的IO消耗以及带宽消耗换取后续查询的低延迟
Compaction流程:
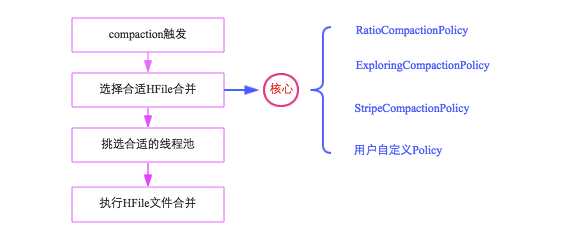
Compaction出发时机始于特定的触发条件,比如flush、周期性的Compaction检查操作或手动触发,一旦触发,HBase会将该Compaction交由一个单独的线程去操作
Memstore Flush:memstore flush 会产生一个hfile文件,文件越来越多就需要compact,一旦文件数大于设定值就会进行compact
后台线程周期性检查:手动触发,一般不会做过多的检查,直接执行合并
sanpshort流程:
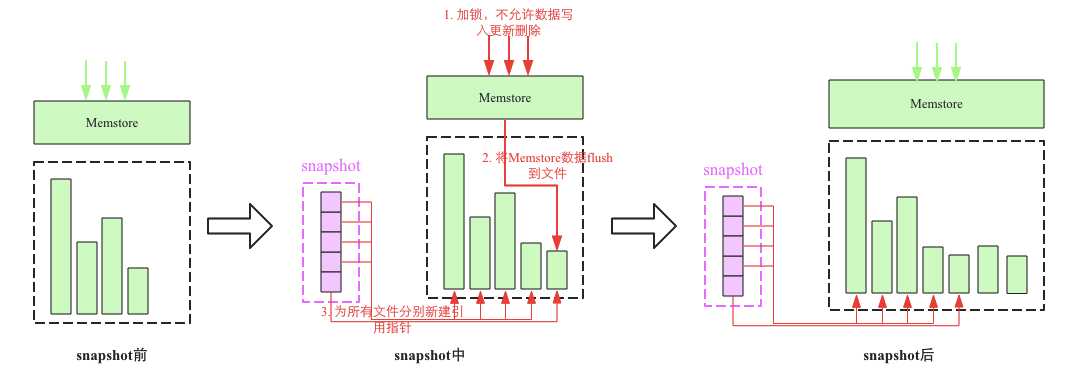
主要分为以下几个步骤:
(1)加一把全局锁,此时不允许任何数据写入更新以及删除操作
(2)将memstore中缓存的数据flush(可选)
(3)为所有hfile文件分别新建引用指引,这些指针元数据就是snapshort
功能:
(1)全量/增量的备份
(2)对重要数据业务进行快照,如果发生错误后可回滚之前的快照点
(3)数据迁移,使用ExportSnapshot功能将快照到另一个集群
snapshort使用:
(1)为表‘sourceTable‘打一个快照‘snapshotName‘,快照并不涉及数据移动,可以在线完成
hbase> snapshot ‘sourceTable‘,‘snapshotName‘
(2)恢复指定快照,恢复过程会替代原有数据,将表还原到快照点,快照点之后的所有更新数据将会丢失,需要注意的是原有表需要先disable,然后才能恢复操作
hbase> restore_snapshot ‘snapshotName‘
(3)根据快照恢复出一个新表,恢复过程不涉及数据移动,可以在秒级完成
hbase> clone_snapshot ‘snapshotName‘,‘tableName‘
使用ExportSnapshot命令可以将A集群的快照数据迁移到B集群,ExportSnapshot是HDFS层面的操作,会使用MR进行数据的并行迁移,因此需要在开启MR的机器上进行迁移。HMaster和HRegionServer并不参与这个过程,因此不会带来额外的内存开销以及GC开销。唯一的影响是DN在拷贝数据的时候需要额外的带宽以及IO负载,ExportSnapshot也针对这个问题设置了参数-bandwidth来限制带宽的使用。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot MySnapshot -copy-from hdfs://srv2:8082/hbase -copy-to hdfs://srv1:50070/hbase -mappers 16 -bandwidth 1024\
HBase优化:
(1)表的设计:
- 表的预分区 可解决热点问题
- RowKey设计 最大长度64kB,越小越好(可散列性,取反或hash)
- Column Family 一般设计1~3个,不宜太多
- Compact&Split 一般对于major做优化
- 设置最大版本号 Max Version [ HColumnDescriptor.setMaxVersions(int maxVersions) ]
- 设置表中数据的生命周期 Time To Live [ HColumnDescriptor.setTimeToLive(int timeToLive) ]
- 创建表的时候将表放入到缓存 In Memory [ HColumnDescriptor.setInMemory(true) ]
(2)写表操作:
- Auto Flush 避免每put一条数据就刷新一次 [ HTable.setAutoFlush(false) ]
- Write Buffer 可以设置HTable客户端写Buffer大小 [ HTable.setWriteBufferSize(writeBufferSize) ]
- 批量写
(3)读表操作
- Scanner Caching 使用scan时候设置一次从服务端拉取的数据条数,可以减少scan过程中next()的时间开销
- scan指定column family
- close resultscanner
- Blockcache 读缓存