标签:style blog http color io os 使用 java ar
本文介绍的是在Ubuntu下安装用三台PC安装完成Hadoop集群并运行好第一个Hello World的过程,软硬件信息如下:
Ubuntu:12.04 LTS
Master: 1.5G RAM,奔腾处理器。
Slave1、Slave2:4G RAM,I3处理器。
1 安装Ubuntu : http://cdimage.ubuntu.com/releases/12.04/release/,Ubuntu的安装过程网上有很多,这里不再赘述了,安装之前一定要对Linux的目录树和Mount有所了解。另外i,安装Ubutu过程中,三个用户名必须是一样的,当然你后面建用户也行,但是不方便。另外OpenSSH一定要先装好。
2 安装好后,开启root:
sudo passwd root
sudo passwd -u root
3 开始安装jdk 1.6 ,下载地址 http://www.oracle.com/technetwork/java/javase/downloads/java-se-6u24-download-338091.html:
使用终端进入存放jdk-6u24-linux-i586.bin,我的位置是:/usr/lib。我推荐的终端软件为:XShell和XFTP。存放后后:
第一步:更改权限;默认文件没有可执行权限
chmod g+x jdk-6u24-linux-i586.bin
第二步: 安装
sudo -s ./jdk-6u24-linux-i586.bin
安装完毕,下面配置环境变量
我安装好后java的路径是:/usr/lib/jdk1.6.0_24
配置classpath,修改所有用户的环境变量:
sudo vi /etc/profile
在文件最后添加
#set java environment export JAVA_HOME=/usr/lib/jdk1.6.0_24 export JRE_HOME=/usr/lib/jdk1.6.0_24/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
如果使用sudo提示不在用户组中 则敲命令 su - ,切换到root,继续敲 visudo ,然后
在root ALL=(ALL:ALL) ALL下
添加
hadoop ALL=(ALL:ALL) ALL (ps:hadoop是我建的用户名。)
重新启动计算机,用命令测试jdk的版本
java -version
显示如下信息:成功安装
java version "1.6.0_12" Java(TM) SE Runtime Environment (build 1.6.0_12-b04) Java HotSpot(TM) Server VM (build 11.2-b01, mixed mode)
5 hadoop安装和运行
下载地址:http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-1.2.1/
存放目录:/home/hadoop(hadoop是用户名)
解压: tar -zxvf hadoop-1.2.1.tar.gz
6 Hadoop集群配置:
1 修改三台主机的hosts文件 :
vi /etc/hosts
加入如下四行,分别修改为你的master机器和slave机器的ip地址即可
127.0.0.1 localhost
192.168.1.1 master
192.168.1.2 slave1
192.168.1.3 slave2
2 修改主机名 vi /etc/hostname
各自改为master,slave1,slave2.
3 配置master免SSH登录slave
在master上生成密钥:
ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
然后用xftp将~/.ssh文件下的所有文件拷贝到两台slave机器即可。然后输入命令。
cd ~/.ssh scp authorized_keys slave1:~/.ssh/ scp authorized_keys slave2:~/.ssh/
4 修改三台主机的配置文件
vi /home/hadoop/hadoop-1.2.1/conf/hadoop-env.sh
加入:export JAVA_HOME=/usr/lib/jdk1.6.0_24 (更改为你们自己的目录)
vi /home/hadoop/hadoop-1.2.1/conf/core-site.xml
加入:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
继续:
vi /home/hadoop/hadoop-1.2.1/conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
继续:
vi /home/hadoop/hadoop-1.2.1/conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
在master机器上修改:
vi /home/hadoop/hadoop-1.2.1/conf/masters
加入master
vi /home/hadoop/hadoop-1.2.1/conf/slaves
加入
slave1
slave2
5 启动hadoop:
cd /home/hadoop/hadoop-1.2.1 bin/hadoop namenode -format --这里是格式化 一次即可 bin/start-all.sh

6 Hello World-经典的wordcount程序
cd ~ mkdir file cd file echo "Hello World" > file1.txt echo "Hello Hadoop" > file2.txt cd /home/hadoop/hadoop-1.2.1 bin/hadoop fs -mkdir input bin/hadoop fs -ls bin/hadoop fs -put ~/file/file*.txt input bin/hadoop fs -ls input bin/hadoop jar ./hadoop-examples-1.2.1.jar wordcount input output
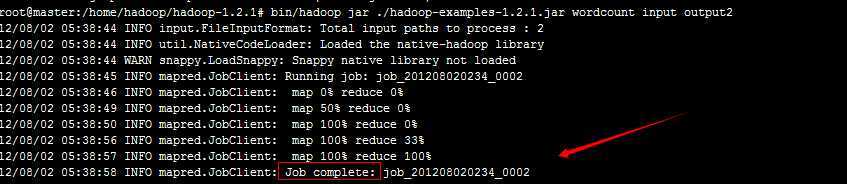
查看输出结果:
bin/hadoop fs -ls output

查看最终结果:

可见,wordCount程序运行完成了。详细执行步骤如下:
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,如图4-1所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。

图4-1 分割过程
2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如图4-2所示。

图4-2 执行map方法
3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如图4-3所示。

图4-3 Map端排序及Combine过程
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如图4-4所示。

图4-4 Reduce端排序及输出结果
这一块:更详细的介绍可以参考:http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html
该文是对《Hadoop实战》最佳阐述。
搭建Hadoop集群网上的文章有很多,遇到问题不断的查找,最终总是可以解决问题的。感觉最繁碎的问题是权限,我后面一概就用root了。改起来烦。然,搭建完一个hadoop根本不算什么。搞懂hadoop适合的业务情形,搞懂Hadoop的设计思想,在写自己程序时,可以灵活运用,达到它山之石可以攻玉的效果,那才是学习Hadoop的最终目的。
标签:style blog http color io os 使用 java ar
原文地址:http://www.cnblogs.com/HouZhiHouJueBlogs/p/3977826.html