Master-Slave:
读写分离,save复制master的数据。同步复制:保证了强一致性但是会影响高可用性,因为写入的时候要保证slave都写入了才能返回告诉生产者数据写入成功,如果slave过多就是时间过长。异步复制:数据写入master之后不要求所有的slave都写入就返回生产者写入成功,然后由slave异步的同步,同步过程既可以是master去推也可以是slave去拉,master不需要等待slave的完成,减少了响应时间,风险在于数据的不一致性。
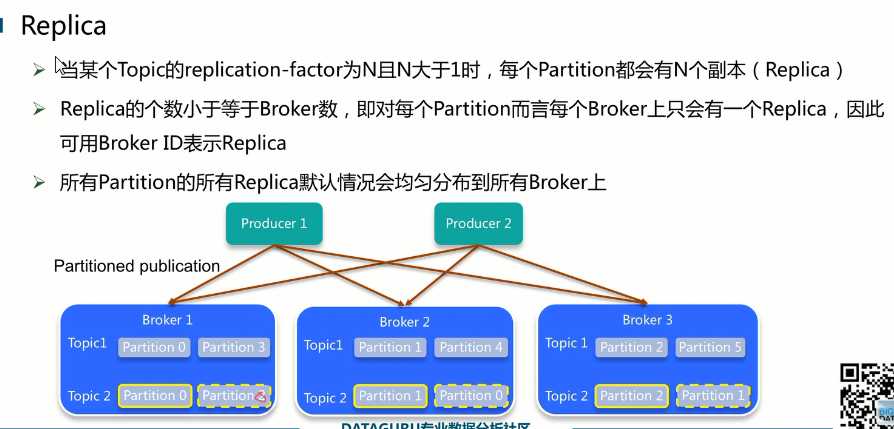
Broker是kafka的server,也可以看成是kafka的进程。
Topic2的Partition0再Broker1上,他的副本再Broker2上,Partition1的主本在Broker2上他的副本在Broker3上,就保证了一个Broker挂了partition还是可用的。
Kafka用的是Master和Slave的方式,每一个Patition有一个主节点leader(Master),还有好几个Follower(Slave)。
下图以Topic1的PAtition1为例,topic1-pation1的leader在broker1上面,follower在brojer2和broker3上面,生产者写消息的时候之后写入broker上面去,然后数据复制进broker2和broker3(拉的方式),消费者读数据也只是从leader读,follower只是保证leader挂了follower可以使用。
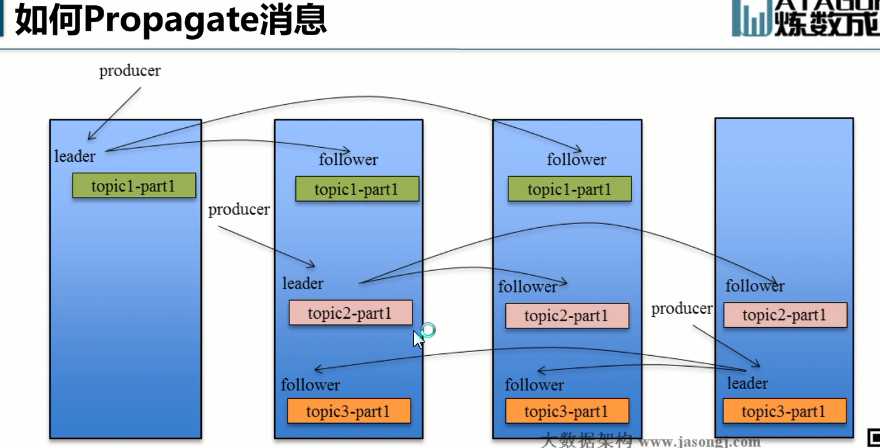
Kafka的主从复制,既不是同步复制也不是异步复制。

主节点会维护一个次节点的列表ISR,如果子节点(挂了)落后太多就会移除次节点,所有存活的次节点都向主节点发送ACk就commit,生产者就认为数据提交了,消费者只能读取commit的数据。
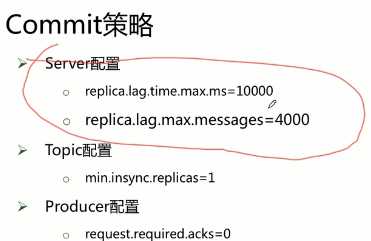
如果10秒还没有发送ack就移除次节点,如果主节点和次节点数据相差4000条就会移除follower。如果次节点后来的差距小于4000了就会把该次节点重新加入ISR。
最小的follower数量是1。
不需要等待follower发送ack。
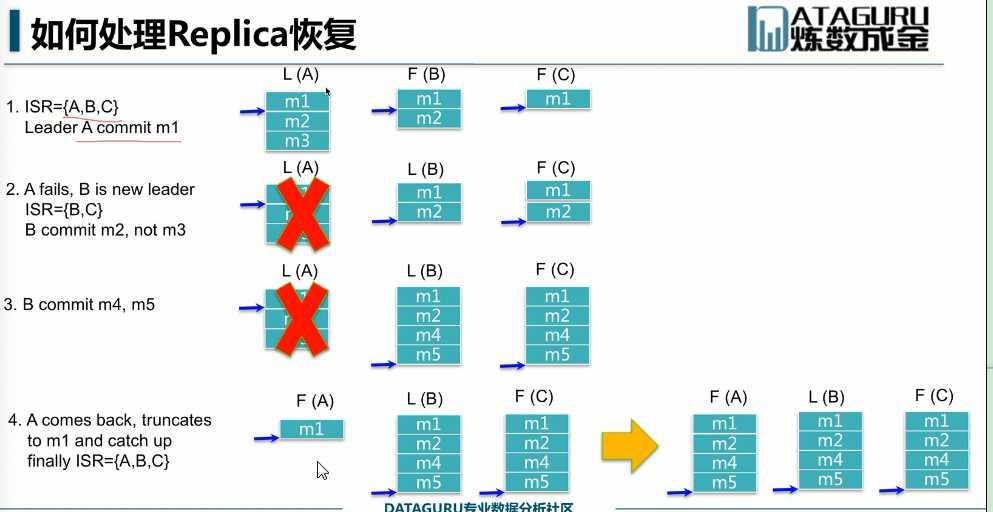
第一步:A是leader,B,C是followe,但是只有m1被commit了,所以消费者只能读到m1,m2,m3不能读到。
第二部:A挂了,B成为Leader,C是Follower, 此时m2被commit。
第三部:m4,m5被commit
第四部:A回来了,A就会去catch up把B里面commit的所有数据都拿过来。M3一直没有commit就丢失了,m3没有commit过,那么生产者就不会认为m3发生成功过,就会retry,retry3次还没有成功就丢失了,retry成功了就会在m5的后面,造成数据的顺序不一致。