标签:信息 计算机 文本搜索 alpha after vpd proc contex 总数
文本处理工具在用户在使用计算机时极大程度的为用户提供了便利。让用户可以轻松的整理文本,以及从中找出自己想要得到的信息。下面将简单介绍一下一些常用的文本处理工具。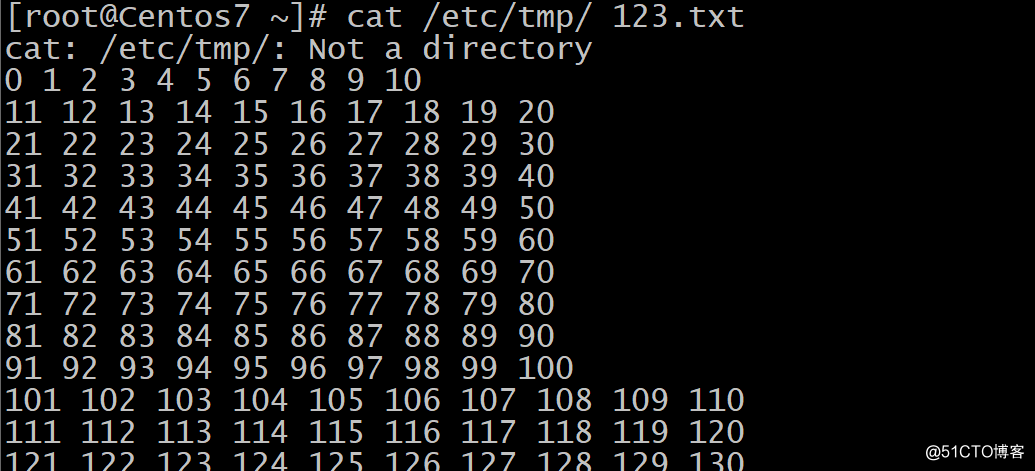

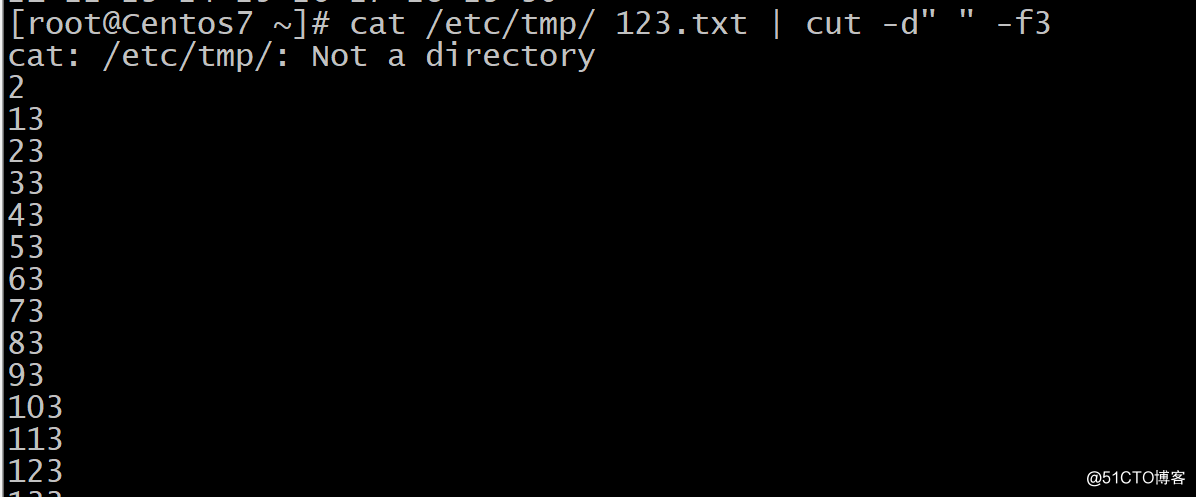
wc 计数总单词数’,总行数,总字节数,总字符数。例如:统计文本总单词数 反向数字大小排序:
反向数字大小排序: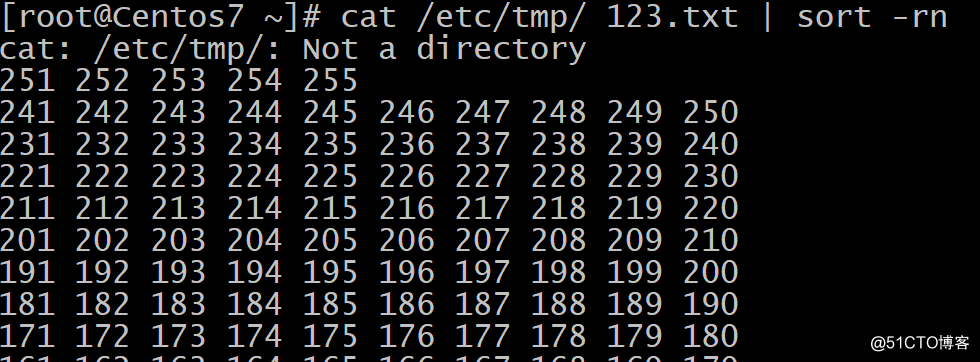
-| 计数行数
-w 计数单词数
-c 计数字节数
-m 来只计数字符总数
sort 对文本进行整理排序(不改变原始文件)
-r 执行反方向整理
-n 执行按数字大小整理
-f 忽略字符串中的字符大小写
-u选项删除输出中的重复行
-t c 选项使用c作为字段界定符
-k X 选项按照用c字符分隔的X列来整理能够使用多次
uniq 从输入中删除前后相接的重复的行
-c:显示每行重复出现的次数
-d:仅显示重复过的行
-u:仅显示不曾重复的行
(常在sort整理后使用)
4.从文本或文件中按条件或者关键字获取信息:**grep
作用:文本搜索工具,根据用户指定的“模式”对目标文 本逐行进行匹配检查;打印匹配到的行 模式:由正则表达式字符及文本字符所编写的过滤条件 。例子 匹配带有9的单词: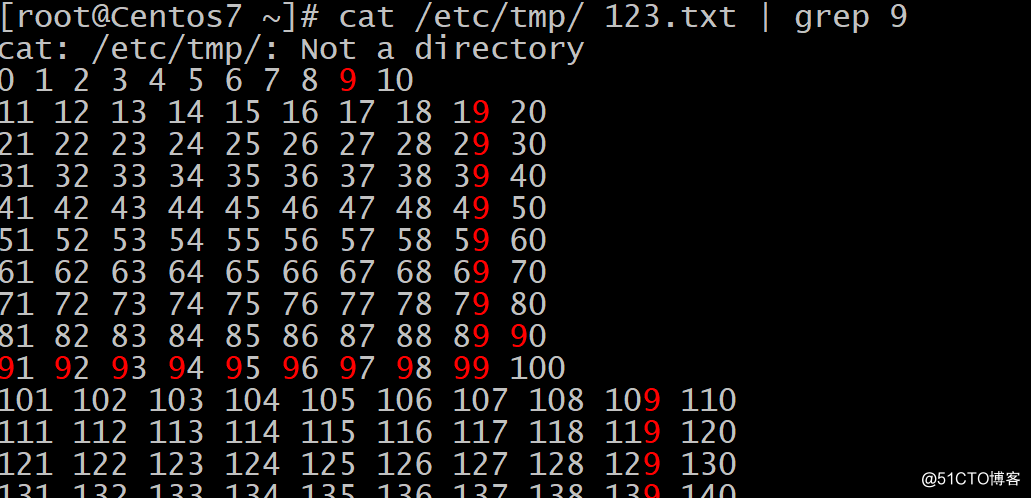 只显示9结尾的单词:
只显示9结尾的单词: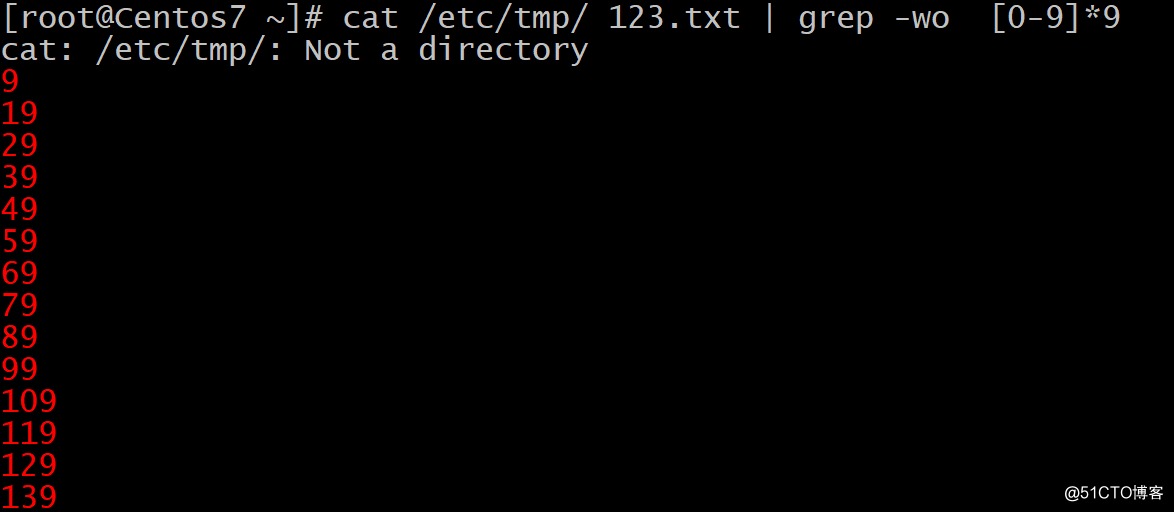
--color=auto: 对匹配到的文本着色显示
-v: 显示不被pattern匹配到的行
-i: 忽略字符大小写
-n:显示匹配的行号
-c: 统计匹配的行数
-o: 仅显示匹配到的字符串
-q: 静默模式,不输出任何信息
-A #: after, 后#行
-B #: before, 前#行
-C #:context, 前后各#行
-e:实现多个选项间的逻辑or关系
grep -e “abc” -e“asd”
-w:匹配整个单词
-E:使用ERE
-F:相当于fgrep,不支持正则表达式
正则表达式常用字符:锚定用法例子 只显示百位数为1个位数为9的三位数: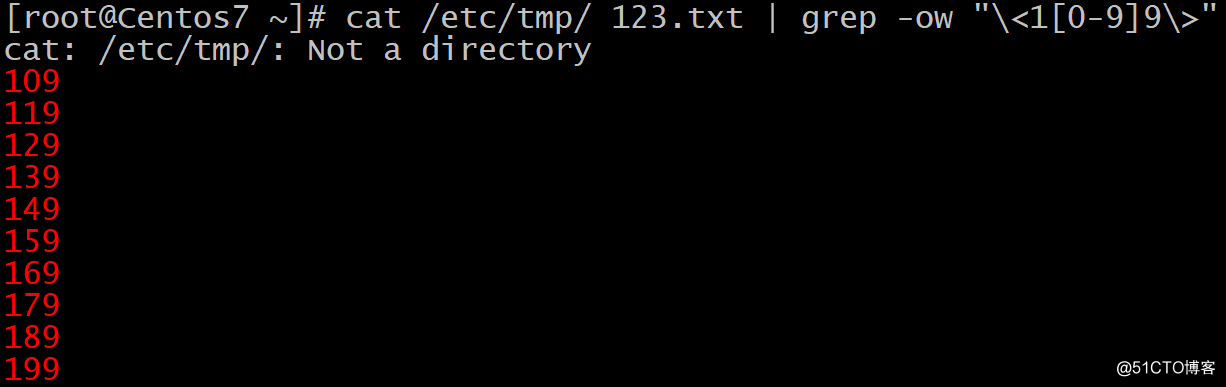
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母 [:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字 [:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
* 匹配前面的字符任意次,包括0次
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次
\+ 匹配其前面的字符至少1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次位置锚定:定位出现的位置
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定;用于单词模式的右侧
\<PATTERN\> 匹配整个单词
分组:() 将一个或多个字符捆绑在一起,当作一个整体进 行处理,如:(root)+
或者:| 示例:a|b: a或b C|cat: C或cat (C|c)at:Cat或cat
标签:信息 计算机 文本搜索 alpha after vpd proc contex 总数
原文地址:http://blog.51cto.com/13572749/2063434