堆栈溢出
堆栈溢出通常是所有的缓冲区溢出中最容易进行利用的。了解堆栈溢出之前,先了解以下几个概念:
- 缓冲区
- 简单说来是一块连续的计算机内存区域,可以保存相同数据类型的多个实例。
- 堆栈
- 堆 栈是一个在计算机科学中经常使用的抽象数据类型。堆栈中的物体具有一个特性:最后一个放入堆栈中的物体总是被最先拿出来,这个特性通常称为后进先出 (LIFO)队列。堆栈中定义了一些操作。两个最重要的是PUSH和POP。PUSH操作在堆栈的顶部加入一个元素。POP操作相反,在堆栈顶部移去一个 元素,并将堆栈的大小减一。
- 寄存器ESP、EBP、EIP
- CPU的ESP寄存器存放当前线程的栈顶指针,
- EBP寄存器中保存当前线程的栈底指针。
- CPU的EIP寄存器存放下一个CPU指令存放的内存地址,当CPU执行完当前的指令后,从EIP寄存器中读取下一条指令的内存地址,然后继续执行。
现 代计算机被设计成能够理解人们头脑中的高级语言。在使用高级语言构造程序时最重要的技术是过程(procedure)和函数(function)。从这一 点来看,一个过程调用可以象跳转(jump)命令那样改变程序的控制流程,但是与跳转不同的是,当工作完成时,函数把控制权返回给调用之后的语句或指令。 这种高级抽象实现起来要靠堆栈的帮助。堆栈也用于给函数中使用的局部变量动态分配空间,同样给函数传递参数和函数返回值也要用到堆栈。
堆栈由逻辑堆栈帧组成。当调用函数时逻辑堆栈帧被压入栈中,当函数返回时逻辑堆栈帧被从栈中弹出。堆栈帧包括函数的参数,函数地局部变量,以及恢复前一个堆栈帧所需要的数据,其中包括在函数调用时指令指针(IP)的值。
当一个例程被调用时所必须做的第一件事是保存前一个 FP(这样当例程退出时就可以恢复)。然后它把SP复制到FP,创建新的FP,把SP向前移动为局部变量保留空间。这称为例程的序幕(prolog)工 作。当例程退出时,堆栈必须被清除干净,这称为例程的收尾(epilog)工作。Intel的ENTER和LEAVE指令,Motorola的LINK和 UNLINK指令,都可以用于有效地序幕和收尾工作。
下面我们用一个简单的例子来展示堆栈的模样: example1.c:
为了理解程序在调用function()时都做了哪些事情, 我们使用gcc的-S选项编译, 以产生汇编代码输出:
通过查看汇编语言输出, 我们看到对function()的调用被翻译成:
以从后往前的顺序将function的三个参数压入栈中, 然后调用function(). 指令call会把指令指针(IP)也压入栈中. 我们把这被保存的IP称为返回地址(RET). 在函数中所做的第一件事情是例程的序幕工作:
将帧指针EBP压入栈中. 然后把当前的SP复制到EBP, 使其成为新的帧指针. 我们把这个被保存的FP叫做SFP. 接下来将SP的值减小, 为局部变量保留空间. 我 们必须牢记:内存只能以字为单位寻址. 在这里一个字是4个字节, 32位. 因此5字节的缓冲区会占用8个字节(2个字)的内存空间, 而10个字节的缓冲区会占用12个字节(3个字)的内存空间. 这就是为什么SP要减掉20的原因. 这样我们就可以想象function()被调用时堆栈的模样:
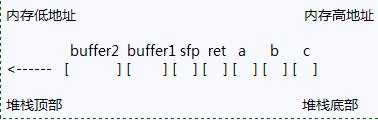
所以,从上图来看,假如我们输入的buffer1超长了,直接覆盖掉后面的sfp和ret,就可以修改该函数的返回地址了。下面来看一个示例吧。
示例
关于如何编写Shell Code,如何在内存中预先准备好一段危险的执行代码以及如何精确计算通过缓冲区溢出执行那段危险代码同时又让返回地址调回原来返回地址……这中间涉及太 多的底层汇编知识,小弟不才也只是走马观花,成不了真正的黑客高手。但从黑客朋友的水平之高看来,提高我们的代码安全性是非常必要的!
因此,在这个例子中,我们假设所谓的危险代码已经在 源代码中,即函数bar。函数foo是正常的函数,在main函数中被调用,执行了一段非常不安全的strcpy工作。利用不安全的strcpy,我们可 以传入一个超过缓冲区buf长度的字符串,执行拷贝后,缓冲区溢出,把ret返回地址修改成函数bar的地址,达到调用函数bar的目的。
用GCC编译上面的程序,同时注意关闭Buffer Overflow Protect开关:
为了找出返回地址,我用gdb调试上面编译出来的程序。
Breakpoint 1, main (argc=2, argv=0xbfe5ab24) at test.c:24 24 foo(argv[1]); //在调用foo函数前,我们查看ebp值 (gdb) info registers ebp ebp 0xbfe5aa88 0xbfe5aa88 //ebp值为0xbfe5aa88 (gdb) n
Breakpoint 2, foo (input=0xbfe5c652 "abc") at test.c:4 4 { (gdb) n 6 printf("My stack looks like:\n%p\n%p\n%p\n%p\n%p\n%p\n%p\n\n"); //执行到foo后,我们再查看ebp值 (gdb) info registers ebp ebp 0xbfe5aa68 0xbfe5aa68 //ebp值变成了0xbfe5aa68 //我们来查看一下地址0xbfe5aa68究竟是啥东东: (gdb) x/ 0xbfe5aa68 0xbfe5aa68: 0xbfe5aa88 //原来地址0xbfe5aa68存放的居然是我们之前的ebp值,其实豁然开朗了,因为这是执行了push %ebp后将之前的ebp保存起来了,和前面说的居然是一样的! (gdb) n My stack looks like: 0xb7ee04e0 0x8048616 0xbfe5aa74 0xbfe5aa74 0xb7edfff4 0xbfe5aa88 //看,在代码中输入堆栈信息中也出现了熟悉的0xbfe5aa88,因此可以断定该处为保存的上一级的ebp值。对应上上面那个图中的sfp。 0x8048499 //假如0xbfe5aa88就是sfp的话,那0x8048499应该就是ret(返回地址)了,下面来验证一下
7 strcpy(buf, input); //查看0x8048499里面是什么东东 (gdb) x/i 0x8048499 0x8048499 <main+108>: movl $0x8048653,(%esp) //这句代码是main函数中的代码,正是我们执行完foo函数后的下一个地址。不信,看看main的assemble: (gdb) disassemble main Dump of assembler code for function main: 0x0804842d <main+0>: lea 0x4(%esp),%ecx 0x08048431 <main+4>: