今天跟一个朋友在讨论hadoop体系架构,从当下流行的Hadoop+HDFS+MapReduce+Hbase+Pig+Hive+Spark+Storm开始一直讲到HDFS的底层实现,MapReduce的模型计算,到一个云盘如何实现,再到Google分布式史上那最伟大的三篇文章。
这几个名词刚问到初学者的时候肯定会一脸懵逼包括我自己,整个Hadoop家族成员很多,“势力”很庞大,下面画个图,简单概括下。

到这里本文内容已结束,下文是摘自网络上一些比较经典或者浅显易懂的相关文字,有兴趣的继续往下看。对初学者来说,如果上图能大概看懂,那下面的内容能更有利于你理解。
Google的分布式计算三驾马车:
Hadoop的创始源头在于当年Google发布的3篇文章,被称为Google的分布式计算三驾马车。
Google File System(中文,英文)用来解决数据存储的问题,采用N多台廉价的电脑,使用冗余(也就是一份文件保存多份在不同的电脑之上)的方式,来取得读写速度与数据安全并存的结果。
Map-Reduce说穿了就是函数式编程,把所有的操作都分成两类,map与reduce,map用来将数据分成多份,分开处理,reduce将处理后的结果进行归并,得到最终的结果。但是在其中解决了容错性的问题。
BigTable是在分布式系统上存储结构化数据的一个解决方案,解决了巨大的Table的管理、负载均衡的问题。
Doug Cutting:
Doug Cutting之前是一个非常有名的开源社区的人,创造了nutch与lucene(现在都是在Apache基金会下面的),nutch之前就实现了一个分布式的爬虫抓取系统。等Google的三驾马车发布后,Doug Cutting一看,挖靠这么厉害的技术,于是就实现了一个DFS(distributed file system)与Map-Reduce(大牛风范啊),集成进了Nutch,作为Nutch的一个子项目存在。那时,是2004年左右。
在互联网这个领域一直有这样的说法:
“如果老二无法战胜老大,那么就把老大赖以生存的东西开源吧”
当年与Google还是处在强烈竞争关系的Yahoo!于是招了Doug兄进来,把老大赖以生存的DFS与Map-Reduce开源了。开始了Hadoop的童年时期。差不多在2008年的时候,Hadoop才算逐渐成熟。
GFS+MapReduce+Bigtable之间的关系:
知乎上有个回答的很形象:
Hadoop是很多组件的集合,主要包括但不限于MapReduce,HDFS,HBase,ZooKeeper。MapReduce模仿了Google MapReduce,HDFS模仿了Google File System,HBase模仿了Google BigTable,ZooKeeper或多或少模仿了Google Chubby(没有前3个出名),所以下文就只提MapReduce、HDFS、HBase、ZooKeeper吧。
-
HDFS和HBase是依靠外存(即硬盘)的分布式文件存储实现和分布式表存储实现。HDFS是一个分布式的“云存储”文件系统,它会把一个文件分块并分别保存,取用时分别再取出、合并。重要的是,这些分块通常会在3个节点(即集群内的服务器)上各有1个备份,因此即使出现少数节点的失效(如硬盘损坏、掉电等),文件也不会失效。如果说HDFS是文件级别的存储,那HBase则是表级别的存储。HBase是表模型,但比SQL数据库的表要简单的多,没有连接、聚集等功能。HBase的表是物理存储到HDFS的,比如把一个表分成4个HDFS文件并存储。由于HDFS级会做备份,所以HBase级不再备份。
-
MapReduce则是一个计算模型,而不是存储模型;MapReduce通常与HDFS紧密配合。举个例子:假设你的手机通话信息保存在一个HDFS的文件callList.txt中,你想找到你与同事A的所有通话记录并排序。因为HDFS会把callLst.txt分成几块分别存,比如说5块,那么对应的Map过程就是找到这5块所在的5个节点,让它们分别找自己存的那块中关于同事A的通话记录,对应的Reduce过程就是把5个节点过滤后的通话记录合并在一块并按时间排序。MapReduce的计算模型通常把HDFS作为数据来源,很少会用到其它数据来源比如HBase。
-
ZooKeeper本身是一个非常牢靠的记事本,用于记录一些概要信息。Hadoop依靠这个记事本来记录当前哪些节点正在用,哪些已掉线,哪些是备用等,以此来管理机群。
-
Storm本身主要是一个分布式环境下的实时数据计算模型,没有外存存储部分。Storm的应用场景是,数据来的特别快、并且要求随来随处理。比如Twitter服务器自身每秒收到来自全世界的推能达几千条,并且要求收到后还需立即索引,以供查询。这用传统的方法乃至Hadoop都是比较难的,因为外存的使用会带来较大的延迟,这时可以用Storm。Storm节点对内存中的数据进行操作,然后流出数据到下一个节点,以此来维系节点间的协作、达到高速协同处理。
-
Storm有一个总的控制节点Nimbus来与ZooKeeper交流、进行集群管理。
-
Storm还没有做到数据备份,这是它的不足(2013年Update: 较新的Storm已引入了类事务的概念,会有重做的操作来保证数据的处理)。
所以,Hadoop和Storm都是分布式环境下的计算平台,不过前者依赖外存,适应批处理情形,后者依赖内存,适应实时处理、超低延迟、无需大量存储数据情形。前类出现的时间较早(03年GFS的论文),后类出现的时间较晚(10年Yahoo! S4的论文)。我不大赞同“Storm改进了Hadoop的缺点”的说法——这种说法有点像“轮船改进了汽车的哪些缺点”——因为它们本身即不太同类。Storm和Hadoop有很多相似也有很多区别,适用的场景是不一样的,主要取决于使用者自己的需求。
*上面很多叙述方法是为了读者的更好理解,不尽完全准确,比如HBase是有内存缓冲机制的,并非只依赖外存,再比如Nimbus实质上是某个节点上的守护进程,而非节点本身。
大数据技术领域:

大数据平台架构:
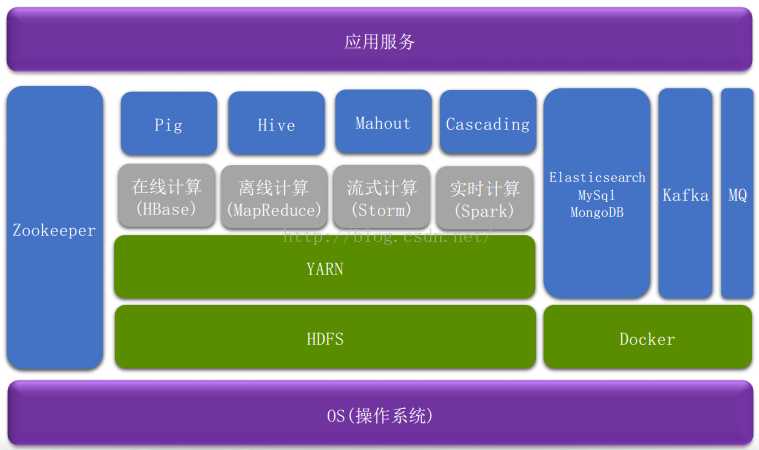
数据处理基础架构

技术架构
