1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
ArrayList是实现了基于动态数组的数据结构,根据源码来了解下为什么随机get/set快 add/remove慢


public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable { transient Object[] elementData; //动态数组 public boolean add(E e) { // 检查数组的大小是否足够,如果不够将创建一个尺寸扩大一倍新数组, //将原数组的数据拷贝到新数组中,原数组丢弃,这里会很 ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; } private void ensureCapacityInternal(int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity); } private void ensureExplicitCapacity(int minCapacity) { modCount++; if (minCapacity - elementData.length > 0) grow(minCapacity); } /** *尺寸不够扩大创建新数组尺寸扩大一倍,数据拷贝到新数组,原数组丢弃 **/ private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); } public E remove(int index) { rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work return oldValue; } }
以下两点可以体现慢
1,扩容
ArrayList里面维护了一个数组,add时:
检查数组的大小是否足够,如果不够将创建一个尺寸扩大一倍新数组, 将原数组的数据拷贝到新数组中,原数组丢弃,这里会很慢
调用数组方法:
Arrays.copyOf(elementData, newCapacity)
2,多个元素发生移动
remove时:
将指定索引的元素移除是通过数组移动调用
System.arraycopy(elementData, index+1, elementData, index,numMoved);
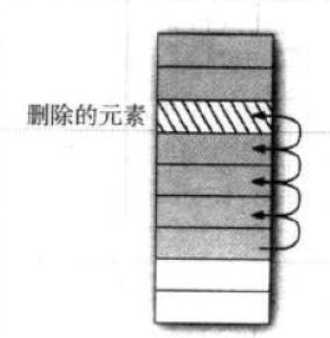
一次删除会有多个元素发生移动如图
同理,add(int,E)向一个指定的位置加元素也会发生多个元素移动,
get/set则直接从数组中根据索引取出元素
public E get(int index) { rangeCheck(index); return elementData(index); } public E set(int index, E element) { rangeCheck(index); E oldValue = elementData(index); elementData[index] = element; return oldValue; } E elementData(int index) { return (E) elementData[index]; }
数组在内存中是连续存储的,所以它的索引速度非常快,而且赋值与修改元素也很简单
一、数组 数组在内存中是连续存储的,所以它的索引速度非常快,而且赋值与修改元素也很简单。 1、一维数组 声明一个数组: int[] array = new int[5]; 初始化一个数组: int[] array1 = new int[5] { 1, 3, 5, 7, 9 }; //定长 声明并初始化: int[] array2 = { 1, 3, 5, 7, 9 }; //不定长 2、多维数组 int[,] numbers = new int[3, 2] { {1, 2}, {3, 4}, {5, 6} }; 但是数组存在一些不足的地方。在数组的两个数据间插入数据是很麻烦的,而且在声明数组的时候必须指定数组的长度,数组的长度过长,会造成内存浪费,
过短会造成数据溢出的错误。如果在声明数组时我们不清楚数组的长度,就会变得很麻烦。 针对数组的这些缺点,.net中最先提供了ArrayList对象来克服这些缺点。
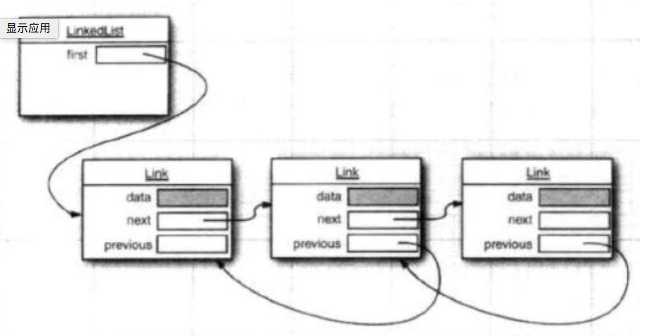
LinkedList基于链表的数据结构
每个元素都包含了 上一个和下一个元素的引用,所以add/remove 只会影响到上一个和下一个元素,
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable { public boolean add(E e) { linkLast(e); return true; } void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; } public E remove() { return removeFirst(); } public E removeFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return unlinkFirst(f); } private E unlinkFirst(Node<E> f) { // assert f == first && f != null; final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; } }
链表
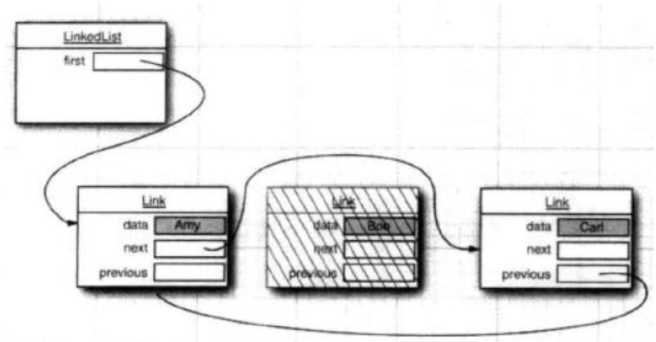
删除时只要改变下,周围2个元素的引用
linkedList get/set就慢了
get(int) 传入索引与 size的1/2比较,大于一半则从最后一个元素开始遍历挨个查找,小于一半则从第一个元素开始遍历挨个查找
public E get(int index) { checkElementIndex(index); return node(index).item; } Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } } public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal; }