# -*- coding: utf-8 -*- # coding:utf-8 必须在第一行才能支持中文注释 #!/usr/bin/python # android-build.py # Build android from selenium import webdriver import io import sys import time # Keys 是用作关键词输入 from selenium.webdriver.common.keys import Keys #键盘操作 from selenium.webdriver.common.action_chains import ActionChains #鼠标操作 # 首先指定driver的浏览器,官方使用的是firefox driver = webdriver.Firefox() driver.set_page_load_timeout(10) #设置页面加载超时时间,超时抛出错误 driver.set_script_timeout(10) #设置页面js加载超时时间,超时抛出错误 # 驱动的get方法即为打开这个网页 driver.get("http://www.baidu.com") # driver.find_element_by_name("wd").send_keys(u‘我是谁‘) #time.sleep(3) #driver.get("http://www.taobao.com") # driver.find_element_by_name("wd").clear() driver.find_element_by_name("wd").send_keys(u‘python selenium api‘) #driver.find_element_by_name("wd").clear() # time.sleep(3) le = driver.find_elements_by_tag_name(‘a‘) cd = len(le) print cd mylist = [] for i in range(0,cd): links = driver.find_elements_by_tag_name(‘a‘) linkhref = links[i].get_attribute(‘href‘) linktarget = links[i].get_attribute(‘target‘) linkonclick = links[i].get_attribute(‘onclick‘) if linkhref and ( ‘http‘ in linkhref) and (not ‘_blank‘ in linktarget) and ( not linkonclick or (not ‘return‘ in linkonclick) ) and (not ‘https‘ in linkhref): print linkhref mylist.append(linkhref) print mylist time.sleep(1) # ActionChains(driver).double_click(links[i]).perform() # time.sleep(5) # driver.back() # time.sleep(5) for n in mylist: print n try: driver.get(n) except: #打开页面超时报错,三秒后跳出本次循环 time.sleep(3) continue time.sleep(3) #print el.get_attribute(‘href‘) # 确定python在网页源码的title中,即没有打开错网页 # assert "Python" in driver.title # # 找到name为"q"的元素 # elem = driver.find_element_by_name("q") # # 清除框内内容 # elem.clear() # # 在框中填入关键词"pycon"并且发送 # elem.send_keys("pycon") # # 获得返回值 # elem.send_keys(Keys.RETURN) # # 确定返回值并不是没有找到结果 # assert "No results found." not in driver.page_source # # 关闭浏览器驱动,非常重要,不然相当于打开了一个网页没有关闭 # print ‘123‘ #time.sleep(5) driver.close()
一、浏览器操作
1、浏览器最大化
driver.maximize_window() #将浏览器最大化显示
2、设置浏览器宽、高
driver.set_window_size(480, 800)#设置浏览器宽480、高800显示
3、控制浏览器前进、后退
driver.back()#浏览器后退 driver.forward()#浏览器前进
二、简单对象的定位
webdriver 提供了一系列的元素定位方法,常用的有以下几种:
- id
- name
- class name
- tag name
- link text
- partial link text
- xpath
- css selector
分别对应python webdriver 中的方法为:
- find_element_by_id()
- find_element_by_name()
- find_element_by_class_name()
- find_element_by_tag_name()
- find_element_by_link_text()
- find_element_by_partial_link_text()
- find_element_by_xpath()
- find_element_by_css_selector()
1、id 和name 定位
id 和name 是我们最常用的定位方式,因为大多数元素都有这两个属性,而且在对控件的id 和name
命名时一般使其有意义也会取不同的名字。通过这两个属性使我们找一个页面上的属性变得相当容易。
比如:
#id=”gs_htif0”
find_element_by_id("gs_htif0")
#name=”btnK”
find_element_by_name("btnK")
2、tag name 和class name 定位
比如:
#<div id="searchform" class="jhp_big" style="margin-top:-2px">
#<form id="tsf" onsubmit="return name="f" method="GET" action="/search">
find_element_by_class_name("jhp_big")
find_element_by_tag_name("div")
tag name 定位应该是所有定位方式中最不靠谱的一种了,因为在一个页面中具有相同tag name 的元
素极其容易出现。
3、link text 与partial link text 定位
有时候需要操作的元素是一个文字链接,那么我们可以通过link text 或partial link text 进行元素
定位。比如:
#<a href="http://news.baidu.com" name="tj_news">新闻</a>
#<a href="http://tieba.baidu.com" name="tj_tieba">贴吧</a>
#<a href="http://zhidao.baidu.com" name="tj_zhidao">一个很长的文字连接</a>
#通过link text 定位元素:
find_element_by_link_text("新闻")
find_element_by_link_text("贴吧")
find_element_by_link_text("一个很长的文字连接")
#通partial link text 也可以定位到上面几个元素:
find_element_by_partial_link_text("新")
find_element_by_partial_link_text("吧")
find_element_by_partial_link_text("一个很长的")
当一个文字连接很长时,我们可以只取其中的一部分,只要取的部分可以唯一标识元素。一般一个页
面上不会出现相同的文件链接,通过文字链接来定位元素也是一种简单有效的定位方式。
4、XPath 定位
XPath 是一种在XML 文档中定位元素的语言。因为HTML 可以看做XML 的一种实现,所以selenium 用
户可是使用这种强大语言在web 应用中定位元素。
以下面一段html代码为例:
<html class="w3c">
<body>
<div class="page-wrap">
<div id="hd" name="q">
<form target="_self" action="http://www.so.com/s">
<span id="input-container">
<input id="input" type="text" x-webkit-speech="" autocomplete="off" suggestwidth="501px" >
(1)使用绝对路径定位:
当我们所要定位的元素很难找到合适的方式时,都可以通这种绝对路径的方式位,缺点是当元素在很
多级目录下时,我们不得不要写很长的路径,而且这种方式难以阅读和维护。
find_element_by_xpath("/html/body/div[2]/form/span/input")
(2)使用相对路径定位:
find_element_by_xpath("//input[@id=’input’]") #通过自身的id 属性定位
find_element_by_xpath("//span[@id=’input-container’]/input") #通过上一级目录的id 属性定位
find_element_by_xpath("//div[@id=’hd’]/form/span/input") #通过上三级目录的id 属性定位
find_element_by_xpath("//div[@name=’q’]/form/span/input")#通过上三级目录的name 属性定位
通过上面的例子,我们可以看到XPath 的定位方式非常灵活和强大的,XPath 可以做布尔逻辑运算,例如://div[@id=’hd’ or @name=’q’]。
当然,它的缺陷也非常明显:
1、性能差,定位元素的性能要比其它大多数方式差;
2、不够健壮,XPath会随着页面元素布局的改变而改变;
3. 兼容性不好,在不同的浏览器下对XPath 的实现是不一样的。
下面插播一下xpath的知识:
(1)路径表达式:
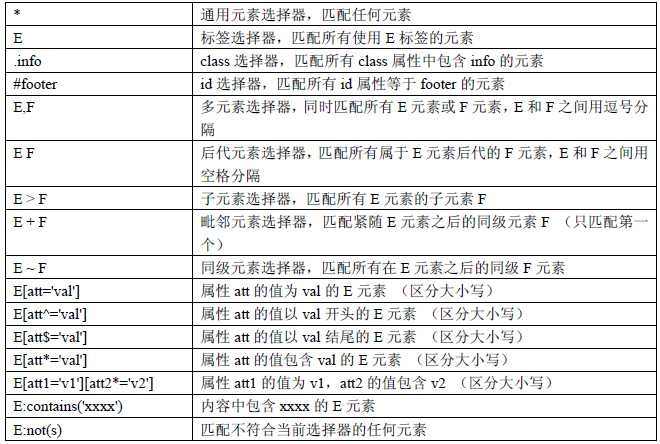
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=‘eng‘] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
(2)选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
5、CSS 定位
CSS(Cascading Style Sheets)是一种语言,它被用来描述HTML 和XML 文档的表现。CSS 使用选择器来为页面元素绑定属性。这些选择器可以被selenium 用作另外的定位策略。CSS 可以比较灵活选择控件的任意属性,一般情况下定位速度要比XPath 快,但对于初学者来说比较难以学习使用,下面我们就详细的介绍CSS 的语法与使用:
例如下面一段代码:
<div class="formdiv"> <form name="fnfn"> <input name="username" type="text"></input> <input name="password" type="text"></input> <input name="continue" type="button"></input> <input name="cancel" type="button"></input> <input value="SYS123456" name="vid" type="text"> <input value="ks10cf6d6" name="cid" type="text"> </form> <div class="subdiv"> <ul id="recordlist"> <p>Heading</p> <li>Cat</li> <li>Dog</li> <li>Car</li> <li>Goat</li> </ul> </div> </div>
通过CSS 语法进行匹配的实例:

关于自动化的定位问题:
自动化测试的元素定位一直是困扰自动化测试新手的一个障碍,因为我们在自动化实施过程中会碰到
各式各样的对象元素。虽然XPath 和CSS 可以定位到复杂且比较难定位的元素,但相比较用id 和name 来
说增加了维护成本和学习成本,相比较来说id/name 的定位方式更直观和可维护,有新的成员加入的自动
化时也增加了人员的学习成本。所以,测试人员在实施自动化测试时一定要做好沟通,规范前端开发人员
对元素添加id/name 属性,或者自己有修改HTML 代码的权限。
三、操作测试对象
一般来说,所有有趣的操作与页面交互都将通过WebElement 接口,包括上一节中介绍的对象定位,
以及本节中需要介绍的常对象操作。
webdriver 中比较常用的操作元素的方法有下面几个:
- clear 清除元素的内容,如果可以的话
- send_keys 在元素上模拟按键输入
- click 单击元素
- submit 提交表单
例如:
driver.find_element_by_id("user_name").clear()
driver.find_element_by_id("user_name").send_keys("username")
driver.find_element_by_id("user_pwd").clear()
driver.find_element_by_id("user_pwd").send_keys("password")
driver.find_element_by_id("dl_an_submit").click()
#通过submit() 来提交操作
#driver.find_element_by_id("dl_an_submit").submit()
- clear() 用于清除输入框的默认内容
- send_keys("xx") 用于在一个输入框里输入xx 内容
- click() 用于单击一个按钮、连接等
- submit() 提交表单
1、WebElement 接口常用方法
WebElement 接口除了我们前面介绍的方法外,它还包含了别一些有用的方法。下面,我们例举例几
个比较有用的方法。
- size #返回元素的尺寸
- text #获取元素的文本
- get_attribute(name) #获得属性值
- is_displayed() #检查该元素是否用户可见
例如:
size=driver.find_element_by_id("kw").size#返回百度输入框的宽高
text=driver.find_element_by_id("cp").text #返回百度页面底部备案信息
#返回元素的属性值,可以是id、name、type 或元素拥有的其它任意属性
attribute=driver.find_element_by_id("kw").get_attribute(‘type‘)
#返回元素的结果是否可见,返回结果为True 或False
result=driver.find_element_by_id("kw").is_displayed()
四、鼠标事件
前面例子中我们已经学习到可以用 click()来模拟鼠标的单击操作,而我们在实际的 web 产品测试中发现,有关鼠标的操作,不单单只有单击,有时候还要和到右击,双击,拖动等操作,这些操作包含在ActionChains 类中。
ActionChains 类鼠标操作的常用方法:
- context_click() 右击
- double_click() 双击
- drag_and_drop() 拖动
- move_to_element() 鼠标悬停在一个元素上
- click_and_hold() 按下鼠标左键在一个元素上
1、右击操作
#引入 ActionChains 类
from selenium.webdriver.common.action_chains import ActionChains
...
#定位到要右击的元素
right =driver.find_element_by_xpath("xx")
#对定位到的元素执行鼠标右键操作
ActionChains(driver).context_click(right).perform()
ActionChains 用于生成用户的行为;所有的行为都存储在 actionchains 对象中。通过 perform()执行存储的行为。
2、鼠标双击操作
#引入 ActionChains 类
from selenium.webdriver.common.action_chains import ActionChains
...
#定位到要双击的元素
double =driver.find_element_by_xpath("xxx")
#对定位到的元素执行鼠标双击操作
ActionChains(driver).double_click(double).perform()
3、鼠标拖放操作
drag_and_drop(source, target)
在源元素上按下鼠标左键,然后移动到目标元素上释放。
source: 鼠标按下的源元素。
target: 鼠标释放的目标元素。
#引入 ActionChains 类
from selenium.webdriver.common.action_chains import ActionChains
...
#定位元素的原位置
element = driver.find_element_by_name("xxx")
#定位元素要移动到的目标位置
target = driver.find_element_by_name("xxx")
#执行元素的移动操作
ActionChains(driver).drag_and_drop(element, target).perform()
4、鼠标移动上元素上
#引入 ActionChains 类
from selenium.webdriver.common.action_chains import ActionChains
...
#定位到鼠标移动到上面的元素
above = driver.find_element_by_xpath("xxx")
#对定位到的元素执行鼠标移动到上面的操作
ActionChains(driver).move_to_element(above).perform()
5、按下鼠标左键
#引入 ActionChains 类
from selenium.webdriver.common.action_chains import ActionChains
...
#定位到鼠标按下左键的元素
left=driver.find_element_by_xpath("xxx")
#对定位到的元素执行鼠标左键按下的操作
ActionChains(driver).click_and_hold(left).perform()
五、键盘事件
from selenium.webdriver.common.keys import Keys #在使用键盘按键方法前需要先导入 keys 类包。
下面经常使用到的键盘操作:
- send_keys(Keys.BACK_SPACE) 删除键(BackSpace)
- send_keys(Keys.SPACE) 空格键(Space)
- send_keys(Keys.TAB) 制表键(Tab)
- send_keys(Keys.ESCAPE) 回退键(Esc)
- send_keys(Keys.ENTER) 回车键(Enter)
- send_keys(Keys.CONTROL,‘a‘) 全选(Ctrl+A)
- send_keys(Keys.CONTROL,‘c‘) 复制(Ctrl+C)
- send_keys(Keys.CONTROL,‘x‘) 剪切(Ctrl+X)
- send_keys(Keys.CONTROL,‘v‘) 粘贴(Ctrl+V)
六、获取页面的title和url
有时间需要通过页面的title和url去判断页面的状态。比如测试登录是否成功和重定向是否成功。
#获得前面 title,打印 title = driver.title print title #获得前面 URL,打印 now_url = driver.current_url print now_url
七、设置等待时间
有时候为了保证脚本运行的稳定性,需要脚本中添加等待时间。
设置等待时间有以下几种方法:
- sleep(): 设置固定休眠时间。 python 的 time 包提供了休眠方法 sleep() , 导入 time包后就可以使用 sleep()进行脚本的执行过程进行休眠。
- implicitly_wait():是 webdirver 提供的一个超时等待。隐的等待一个元素被发现,或一个命令完成。如果超出了设置时间的则抛出异常。
- WebDriverWait():同样也是 webdirver 提供的方法。在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常。
- driver.set_page_load_timeout(10) #设置页面加载超时时间,超时抛出错误
driver.set_script_timeout(10) #设置页面js加载超时时间,超时抛出错误
1、sleep()休眠方法
当执行到sleep()方法时会固定休眠一定的时长,然后再往下执行。sleep()方法以秒为单位,假如休眠时间小于 1 秒,可以用小数表示。
import time .... time.sleep(5) time.sleep(0.5)
当然,也可以直接导入 sleep()方法,使脚本中的引用更简单
from time import sleep .... sleep(3) sleep(30)
2、implicitly_wait()
隐式等待是通过一定的时长等待页面上某元素加载完成。如果超出了设置的时长元素还没被加载,则抛出NoSuchElementException异常。implicitly_wait()方法比 sleep() 更加智能,后者只能选择一个固定的时间的等待,前者可以在一个时间范围内智能的等待。以秒为单位。注意:它并不针对页面上的某一个元素进行等待,而是从你设定这个隐式等待开始的所有需要定位的元素。当脚本执行到某个元素定位时,如果元素可以定位,则继续执行;如果元素定位不到,则它将以轮询的方式不断判断元素是否定位到。超过设定时间抛出异常
#添加智能等待30秒 driver.implicitly_wait(30)
3、WebDriverWait()
详细格式如下:
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None),参数解释如下:
- driver - WebDriver 的驱动程序(Ie, Firefox, Chrome 或远程)
- timeout - 最长超时时间,默认以秒为单位
- poll_frequency - 休眠时间的间隔(步长)时间,默认为 0.5 秒
- ignored_exceptions - 超时后的异常信息,默认情况下抛 NoSuchElementException 异常。
from selenium.webdriver.support.ui import WebDriverWait .... element = WebDriverWait(driver, 10).until(lambda x: x.find_element_by_id(“someId”)) is_disappeared = WebDriverWait(driver, 30, 1, (ElementNotVisibleException)).until_not(lambda x: x.find_element_by_id(“someId”).is_displayed())
WebDriverWai()一般由 unit()或 until_not()方法配合使用,下面是 unit()和 until_not()方法的说明:
until(method, message=’’)
调用该方法提供的驱动程序作为一个参数,直到返回值不为False。
until_not(method, message=’’)
调用该方法提供的驱动程序作为一个参数,直到返回值为 False。
八、定位一组对象
需要获取页面上的一组元素是的方法:
#find_elements 用于获取一组元素。 find_elements_by_id(‘xx’) find_elements_by_name(‘xx’) find_elements_by_class_name(‘xx’) find_elements_by_tag_name(‘xx’) find_elements_by_link_text(‘xx’) find_elements_by_partial_link_text(‘xx’) find_elements_by_xpath(‘xx’) find_elements_by_css_selector(‘xx’)
可以使用for... in ...对这一组元素进行遍历
for checkbox in checkboxes: checkbox.click()
我们获取到一组元素之后也可以使用pop()方法获得这一组元素中的第几个,然后再对该元素进行操作:
find_elements_by_id(‘xx’).pop().click()
- pop()或pop(-1)默认获取一组元素中的最后一个
- pop(0) 默认获取一组元素的第一个元素
- pop(1) 默认获取一组元素的第二个元素
- ......以此类推
九、层级定位
在实际的项目测试中,经常会有这样的需求:页面上有很多个属性基本相同的元素 ,现在需要具体
定位到其中的一个。由于属性基本相当,所以在定位的时候会有些麻烦,这时候就需要用到层级定位。先
定位父元素,然后再通过父元素定位子孙元素。
比如下拉列表,我们可以先点击弹出下拉框然后再定位下拉列表中的选项
#点击 Link1 链接(弹出下拉列表) driver.find_element_by_link_text(‘Link1‘).click() #在父亲元件下找到 link 为 Action 的子元素 menu = driver.find_element_by_id(‘dropdown1‘).find_element_by_link_text(‘Another action‘)
十、多表单切换
在 web 应用中经常会出现 frame/iframe 表单内嵌套的应用,WebDriver只能在一个页面上进行元素识别定位,对于frame/iframe表单内嵌页面上的元素无法直接定位。这是需要通过switch_to.frame()方法将当前定位的主体切换为frame/iframe表单的内嵌页面中。
driver.switch_to_frame("f2")
switch_to.frame()默认可以直接去表单的id或name属性。如果没有这两个属性,可以通过其他方式定位,比如:
#先通过xpath定位到iframe xf=driver.find_element_by_xpath(‘/*[@class="if"]‘) #再将定位对象传给switch_to.frame()方法 driver.switch_to.frame()
如果完成了在当前表单上的操作,则可以通过switch_to.parent_content()方法跳出当前一集表单。该方法默认对应于离他最近的switch_to.frame()。如果要跳出最外层的页面使用switch_to.default_conent().
十一、多窗口切换
1、相关方法
current_window_handle:获得当前窗口句柄
window_handles:返回所有窗口的句柄到当前对话
switch_to.window(窗口句柄):切换到对应的窗口。
nowhandle=driver.current_window_handle
driver.find_element_by_link_text(u"发表话题").click()
time.sleep(3)
#由于发表新话题会新窗口打开,所以要指向新窗口,即发话题窗口
allhandles=driver.window_handles
for handle in allhandles:
if(handle!=nowhandle):
driver.switch_to.window(handle)
十二、警告窗处理
处理javascript所生成的alert、confirm、prompt,可以使用switch_to_alert()方法定位到alert/confirm/prompt,然后使用text/accept/dismiss/send_keys等方法进行操作
- text 返回 alert/confirm/prompt 中的文字信息。
- accept 点击确认按钮。
- dismiss 点击取消按钮,如果有的话。
- send_keys 输入值,这个 alert\confirm 没有对话框就不能用了,不然会报错。
十三、上传文件
1、查找到input标签,通过send_keys添加文件路径
#通过查找到input标签,然后send进去
driver.find_element_by_id("coverImgSrc").send_keys(u"%s"%tds["coverImgSrc"])
2、使用AutoIt识别flash控件和windows控件实现自动上传文件
十四、调用javascript
当 webdriver 遇到没法完成的操作时,笔者可以考虑借用 JavaScript 来完成。使用webdriver 提供的execute_script() 接口用来调用 js 代码。比如要操作页面上隐藏的元素,可以用javascript来把它设置为可见然后进行操作
比如下面这段代码:
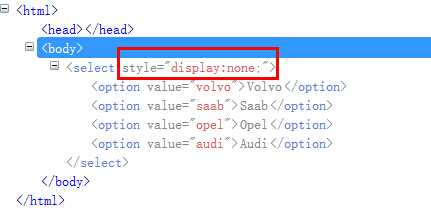
使用javascript:
#修改元素的属性
js = ‘document.querySelectorAll("select")[0].style.display="block";‘
driver.execute_script(js)
sel = driver.find_element_by_tag_name(‘select‘)
Select(sel).select_by_value(‘opel‘)
十五、控制浏览器滚动条
一般用到操作滚动条的会两个场景:
- 注册时的法律条文的阅读,判断用户是否阅读完成的标准是:滚动条是否拉到最下方。
- 要操作的页面元素不在视觉范围,无法进行操作,需要拖动滚动条
用于标识滚动条位置的代码:
<body onload= "document.body.scrollTop=0 "> <body onload= "document.body.scrollTop=100000 ">
如果滚动条在最上方的话, scrollTop=0 , 那么要想使用滚动条在最可下方, 可以 scrollTop=100000 ,
这样就可以使滚动条在最下方。
#将页面滚动条拖到底部 js="var q=document.documentElement.scrollTop=10000" driver.execute_script(js) time.sleep(3) #将滚动条移动到页面的顶部 js1="var q=document.documentElement.scrollTop=0" driver.execute_script(js1) time.sleep(3)
十六、获取元素对象的属性值
有时候我们定位页面上的元素发现常用的id、name等属性是相同的。这个时候我们只能通过常规的定位方法定位出一组元素,然后观察通过元素的属性可以定位出单个元素。可使用.get_attribute()方法。
比如:
# 选择页面上所有的 tag name 为 input 的元素 inputs = driver.find_elements_by_tag_name(‘input‘) #然后循环遍历出 属性data-node值 为594434493的元素,单击勾选 for input in inputs: if input.get_attribute(‘data-node‘) == ‘594434493‘: input.click()
十七、获取验证码问题
关于验证码的处理,网上有几种说法:
1、测试时先去掉验证码
2、使用验证码识别技术
3、使用cookies记录登录用户名密码,下次自动登录免去验证码输入环节
我们自己内部的处理方式是内部提供一个接口获得验证码,然后通过js代码把获取的验证码填写进去:
#自动获取验证码并填写
js="$.getJSON(‘http://xxx.xxx.com/util/getCode.jsonp?callback=?‘,function(data){$(‘.imgcode‘).val(data.code);})"
driver.execute_script(js)