员工信息表程序,主要用到知识点:
1、文件的读写操作
2、程序目录规范化
3、不同目录间文件的调用
本周学习内容:
一、序列化和反序列化
序列化:字典等类型变成字符串存到内存。
a、json.dumps(变量)(字典等简单类型的序列化);
b、pickle.dumps(变量) (只针对本语言的函数等所有类型的序列化)
反序列化:内存的字符串变成字典等类型读出来。
a、可以用eval()针对字典类型;
b、json.loads(f.read());
c、pickle.loads(f.read())。
json 不同语言之间进行交互,简单的;pickle只针对python本语言的所有类型的序列化和反序列化(二进制)。
pickle.dump(info,f)<==>f.write(pickle.dumps(info))
pickle.load(f)<==>pickle.loads(f.read())
注:dump和load一次
- json,用于字符串 和 python数据类型间进行转换。(不同语言不同平台间,简单转换)
- pickle,用于python特有的类型 和 python的数据类型间进行转换。(支持所有的python数据类型)
二、模块和包
1、定义
模块:用来从逻辑上组织Python代码(变量,函数,类,逻辑:实现一个功能),本质就是.Py结尾的python文件。
包:用来从逻辑上组织模块的,本质就是一个目录(必须带一个__init__.py文件)。
2、导入方法
import 模块名 (变量:模块名=所有的代码(赋值))
执行语句:模块名.函数名 或 模块名.变量名
from 模块名 import * 或者 from 模块名 import 变量/函数名 (导入语句)
相当于把代码粘在了当前文件中执行(解释执行,如果有重名冲突,后面的把前面的覆盖掉。不建议用
from 模块名 import logger(函数名) as 别名
3、import本质(路径搜索和搜索路径)
导入模块的本质就是把python文件解释一遍。
导入包的本质就是执行该包下的__init__.py文件。
4、导入优化
from module_name import test(具体的)
5、模块的分类
a、标准库/内置模块(解释器自带的);b、开源模块(第三方模块);c、自定义模块(自己写的.py文件);
三、标准库学习
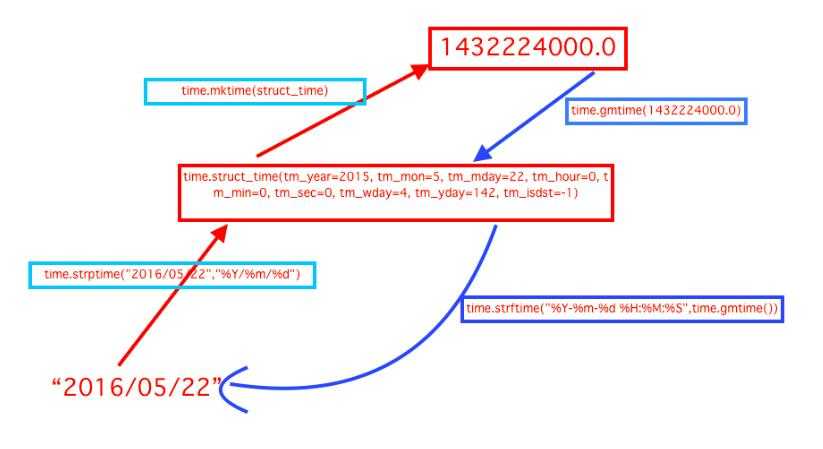
1、time与datetime
2、 shutil模块:高级的文件、文件夹、压缩包处理模块;
3、os模块:主要处理操作系统的相关的功能;
4、sys模块:主要处理系统相关的功能;
5、file模块:主要处理文件操作相关的模块;