线性表有两种,一种是顺序表,一种是链接表
在C语言中,顺序表通常通过数组或者申请一块内存来实现。在python中有列表和元组的结构可供使用,但由于元组一旦申请后无法改变空间大小和值,因此只有列表可以完成线性表的作用
线性表的优点和缺点都在于元素存储的集中方式和连续性,由于连续因此进行访问和删除都很容易找到位置,但也由于连续性,这样的表结构不够灵活,不容易调整和优化,尤其是在C语言中,在添加和删除的时候,必须要随时申请和注销内存。在python的list中,虽然有内置函数完成了这些动作,但其实在底层也是大量的内存申请和注销。因此对于经常修改数据的话。线性表就不太合适。如果表中的元素很固定,很少去改动,那么线性表就是一个比较好的选择。
而链接表正好能弥补线性表的缺点。链接表的组织方式有点类似即插即用的设备,不要需要提前申请内存大小。也不要求数据的内存连续。每个结点都分别存储在一批独立的存储块。每个节点都能找到与其相关的下一个节点。
在C语言中实现链表设计到内存申请,指针的调用等细节,实现起来比较麻烦。但在python中实现这些要方便很多,下面就开始看下具体的实现
一 单链表
单链表是链表中最简单的方式。组织结构如下。每个节点都指向后面的节点,通过前面的节点能够很方便的找到后面的节点。
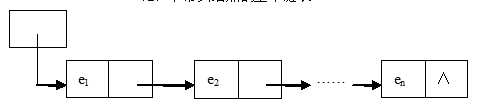
下面来看下具体的实现,首先定义一个类,类似与c语言中的struct。并在初始化的时候初始化elem(具体的值),next指向下一个元素,初始化为None.
class Lnode(object):
def __init__(self,elem,next_=None):
self.elem=elem
self.next=next_
下面开始创建链表。
node=Lnode(1) #首先创建首节点
p=node #并使得p指向首节点
for i in range(2,11): # 创建多个节点,并将各个节点链接起来
p.next=Lnode(i)
p=p.next
p=node #重新回到首节点,开始遍历各个节点。
while p is not None:
print p.elem,p.__class__
p=p.next
输出结果如下:
1 <class ‘__main__.Lnode‘>
2 <class ‘__main__.Lnode‘>
3 <class ‘__main__.Lnode‘>
4 <class ‘__main__.Lnode‘>
5 <class ‘__main__.Lnode‘>
6 <class ‘__main__.Lnode‘>
7 <class ‘__main__.Lnode‘>
8 <class ‘__main__.Lnode‘>
9 <class ‘__main__.Lnode‘>
10 <class ‘__main__.Lnode‘>
这个例子只是简单的一个链接表生成的例子,其中只有链接表的初始功能,也就是将各个节点链接起来。但是在这个例子中并没有实现插入和删除的操作。
首先来看下在表头插入。为了实现表头的插入。前面的代码需要修改下:
定义一个initnode方法来初始化链表,并且返回头节点的位置,也就是head
class Lnode(object):
def __init__(self,elem,next_=None):
self.elem=elem
self.next=next_
def initnode():
node = Lnode(1)
p = node
head=node
for i in range(2, 11):
p.next = Lnode(i)
p = p.next
return head
#在定义一个打印函数来打印所有的节点,传入的参数是头节点head
def print_all_node(head):
p=head
while p is not None:
print p.elem,p.__class__
p=p.next
if __name__=="__main__":
ret=initnode()
head=ret
q=Lnode(12)
q.next=head #将数据插入到头节点。注意没有空的头节点,因此初始化的时候没有空头节点,如果有空的头节点的话那么插入语句应该是q.next=head.next, head.next=q
head=q
print_all_node(head)
最终的结果:
12 <class ‘__main__.Lnode‘>
1 <class ‘__main__.Lnode‘>
2 <class ‘__main__.Lnode‘>
3 <class ‘__main__.Lnode‘>
4 <class ‘__main__.Lnode‘>
5 <class ‘__main__.Lnode‘>
6 <class ‘__main__.Lnode‘>
7 <class ‘__main__.Lnode‘>
8 <class ‘__main__.Lnode‘>
9 <class ‘__main__.Lnode‘>
10 <class ‘__main__.Lnode‘>
下面看另外一直插入,也就是在指定位置的插入。要在指定位置进行插入,首先要找到插入的位置,然后在后面插入,因此需要添加一个查找位置的函数。如果找到需要插入的元素位置则返回,如果没找到,则返回’not found’
def find_node(head,elem):
p=head
while p is not None:
if p.elem == elem:
return p
else:
p=p.next
return ‘not found
if __name__=="__main__":
ret=initnode()
head=ret
q=Lnode(12)
pos=find_node(head,8) #在elem=8的节点后插入Lnode(12)
if pos != ‘not found‘:
q.next = pos.next
pos.next = q
print_all_node(head)
输出如下:
1 <class ‘__main__.Lnode‘>
2 <class ‘__main__.Lnode‘>
3 <class ‘__main__.Lnode‘>
4 <class ‘__main__.Lnode‘>
5 <class ‘__main__.Lnode‘>
6 <class ‘__main__.Lnode‘>
7 <class ‘__main__.Lnode‘>
8 <class ‘__main__.Lnode‘>
12 <class ‘__main__.Lnode‘>
9 <class ‘__main__.Lnode‘>
10 <class ‘__main__.Lnode‘>
接下来看下删除的操作:对于删除来说同样也是需要找打需要删除的位置。但是对于单链表来说,需要找到的是删除位置的前一个节点。因此需要对位置的查找函数重新定义。在这里通过p.next is not None 作为循环的条件。目的是防止到了最后一个元素。
通过p.next.elem == elem的判断找到了需要删除元素的前一个节点。
def find_node_for_delete(head,elem):
p=head
while p.next is not None:
if p.next.elem == elem:
return p
else:
p=p.next
return ‘not found‘
if __name__=="__main__":
ret=initnode()
head=ret
q=Lnode(12)
pos=find_node_for_delete(head,8)
if pos != ‘not found‘: #删除的时候直接通过让删除元素的前一个节点指向删除元素的后一个节点来达到删除的目的。
tmp=pos.next
pos.next=tmp.next
print_all_node(head)
运行结果:
1 <class ‘__main__.Lnode‘>
2 <class ‘__main__.Lnode‘>
3 <class ‘__main__.Lnode‘>
4 <class ‘__main__.Lnode‘>
5 <class ‘__main__.Lnode‘>
6 <class ‘__main__.Lnode‘>
7 <class ‘__main__.Lnode‘>
9 <class ‘__main__.Lnode‘>
10 <class ‘__main__.Lnode‘>
基于以上的实现,我们可以这些功能都封装在一个类里面
class LList(object):
def __init__(self):
self._head=None
def prepend(self,elem):
self._head=Lnode(elem,self._head)
def append(self,elem):
if self._head is None:
self._head=Lnode(elem)
return
p=self._head
while p.next is not None:
p=p.next
p.next=Lnode(elem)
def printall(self):
p=self._head
while p is not None:
print p.elem,p.__class__
p=p.next
append函数就是在链表末尾添加节点。
if __name__=="__main__":
mlist=LList()
for i in range(10):
mlist.append(i)
mlist.printall()
运行结果:
0 <class ‘__main__.Lnode‘>
1 <class ‘__main__.Lnode‘>
2 <class ‘__main__.Lnode‘>
3 <class ‘__main__.Lnode‘>
4 <class ‘__main__.Lnode‘>
5 <class ‘__main__.Lnode‘>
6 <class ‘__main__.Lnode‘>
7 <class ‘__main__.Lnode‘>
8 <class ‘__main__.Lnode‘>
9 <class ‘__main__.Lnode‘>
同样的我们也可以在类中添加删除,计算长度的函数。
二 双向链表
前面介绍的单向链表,在查找的时候其实不太方便,因为只有从前到后的进行查找。如果我们想基于某个节点往前查找的话就做不到了,因此为了更加灵活的操作节点。需要用到双向链表。为了实现双链表,需要在链表中添加一个pre指向前向节点。
class DulNode(object):
def __init__(self,elem,next_=None,pre_=None):
self.elem=elem
self.next=next_
self.pre=pre_-
#初始化节点
def initDulnode():
node=DulNode(1)
p=node
head=node
for i in range(2,11):
tmp=DulNode(i)
tmp.pre=p
p.next=tmp
p=tmp
return head
#打印所有的节点
def print_all_dulnode(head):
p=head
while p is not None:
print p.elem,p.__class__
p=p.next
#找到对应节点的前向节点
def find_dulnode_before(head,elem):
p=head
while p is not None:
if p.elem == elem:
return p.pre
else:
p=p.next
return ‘not found‘
#找到对应节点的后向节点
def find_dulnode_next(head,elem):
p=head
while p is not None:
if p.elem == elem:
return p.next
else:
p=p.next
return ‘not found‘
#删除节点,这里的删除方式和单向链表不太一样,增加了判断是否是末节点的判断。普通节点和末节点的删除方式不一样
def find_dulnode_for_delete(head,elem):
p=head
while p is not None:
if p.elem == elem:
if p.next != None:
before = p.pre
next = p.next
before.next = next
next.pre = before
return ‘delete‘
else:
before=p.pre
before.next=None
p=p.next
return ‘not found‘
同样的我们也可以将这些功能封装在一个类中。实现方法和单链表是一样的。