一、前述
Storm容错机制相比其他的大数据组件做的非常不错。
二、具体原因
结合Storm集群架构图:
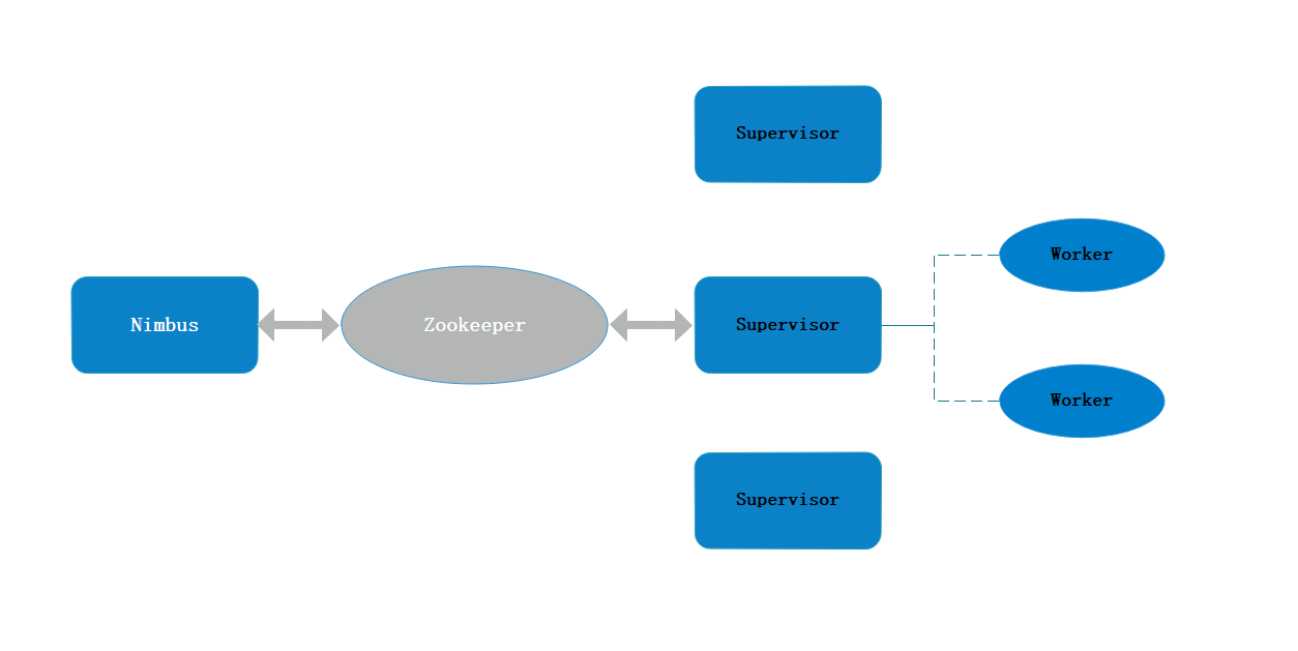
我们的程序提交流程如下:
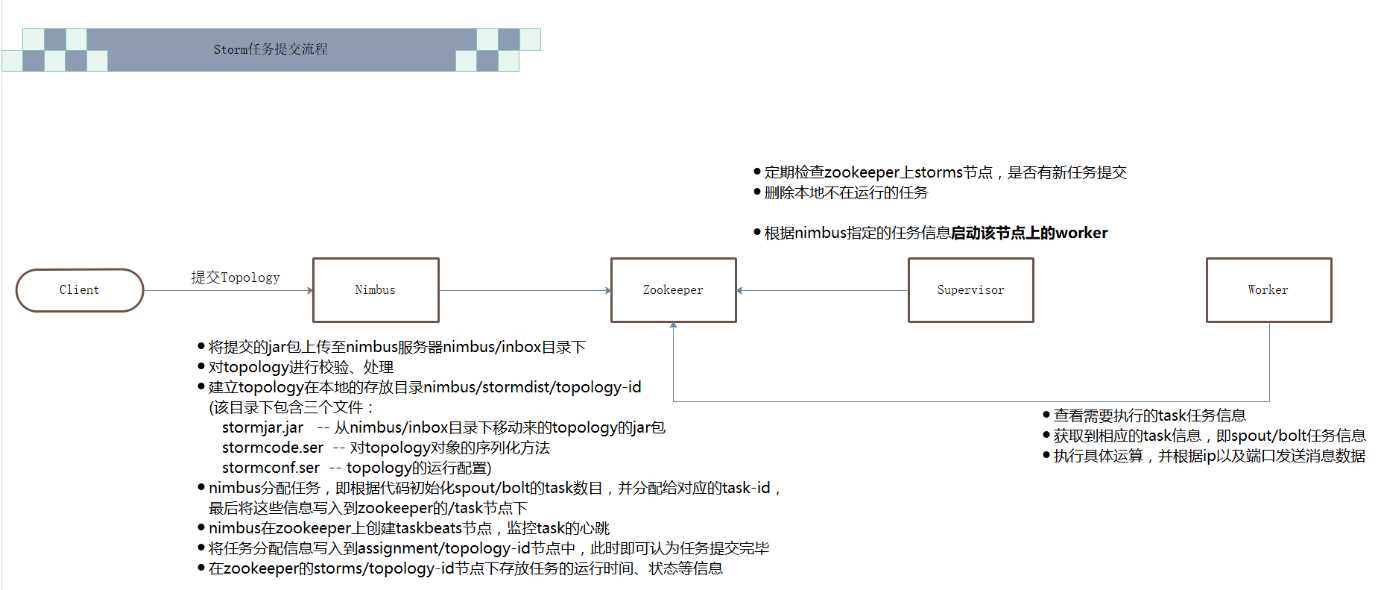
其中各个组件的作用如下:
Nimbus
资源调度
任务分配
接收jar包
Supervisor
接收nimbus分配的任务
启动、停止自己管理的worker进程(当前supervisor上worker数量由配置文件设定)
Worker
运行具体处理运算组件的进程(每个Worker对应执行一个Topology的子集)
worker任务类型,即spout任务、bolt任务两种
启动executor
(executor即worker JVM进程中的一个java线程,一般默认每个executor负责执行一个task任务)
Storm 架构设计与Hadoop架构对比:

当程序提交后,storm的本地配置的目录架构书如下:

zookeeper目录树如下:

因为zookeeper存储了程序的运行信息,状态,并监控task的心跳状况。所以当程序提交完后,任务信息都存储在zookeeper里面,即使nimbus宕机,程序依然会继续执行。
三、容错机制
从以下三个方面考虑:
1、集群节点宕机(集群角度)
Nimbus服务器
单点故障时可以添加报警,但程序银镜加载到内存中运行了。
非Nimbus服务器
故障时,该节点上所有Task任务都会超时,Nimbus会将这些Task任务重新分配到其他服务器上运行
2、进程挂掉
Worker
挂掉时,Supervisor会重新启动这个进程。如果启动过程中仍然一直失败,并且无法向Nimbus发送心跳,Nimbus会将该Worker重新分配到其他服务器上
Supervisor
无状态(所有的状态信息都存放在Zookeeper中来管理)
快速失败(每当遇到任何异常情况,都会自动毁灭)
Nimbus
无状态(所有的状态信息都存放在Zookeeper中来管理)
快速失败(每当遇到任何异常情况,都会自动毁灭)
3、消息的完整性
通过Acker -- 消息完整性的实现机制
保证消息肯定能被处理一次,但不保证会不会重复。因为假设发出的是一个values被切割后其中一个被发送失败了,那么这一组values都得重新发送。
spout发送的时候同时带上message_id,这样这个tuple发送失败后,就能知道哪一个tuplele.
通过消息的亦或状态确保消息是否发送完整。
acker默认为每一个spout,bolt分别启动一个线程。
如下:
