数据流是由硬件的数据通路决定的,表示数据随着指令的执行而流动的过程。也就是数据和控制之间的关系。
对于数据而言,包括操作码、操作数、存储器地址和内容、跳转目的地址和内容、寄存器地址和内容。
对于控制而言,包括控制各个部件的控制信号、时序控制信号和中断控制信号。
1.指令在数据通路中的执行
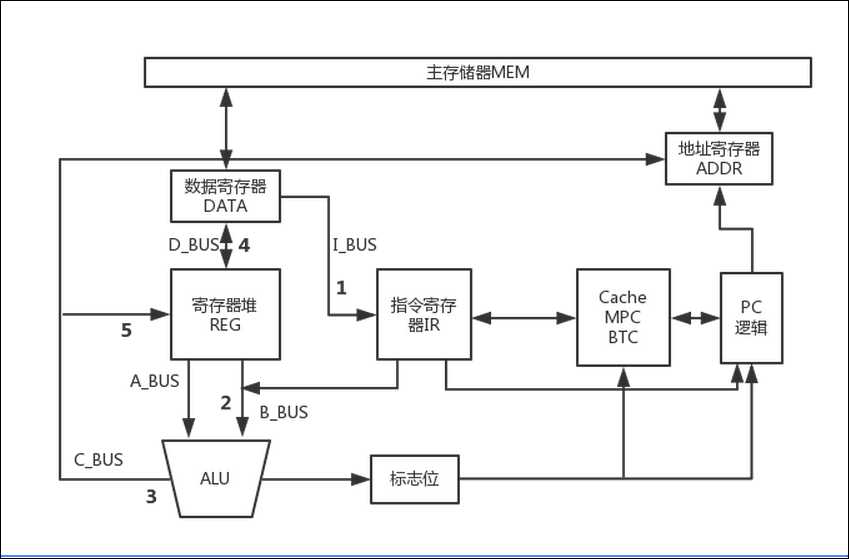
(1)指令装载进指令寄存器IR
指令的地址来自程序计数器PC。在最好情况下,指令来自指令Cache,是由跳转Cache BTC和通用指令Cache MPC共同构成的。
在最坏的情况下,指令来自于外部存储器,即Cache失效,对于给定的地址,Cache中可能包含有效指令(HIT命中),也可能不包含有效指令(MISS不命中)。
在进行Cache访问的同时,PC值也进行准备,包括PC值自动加1,PC值加偏移量,或者装载一个新的跳转地址。
(2)对指令进行译码并准备操作数
对寄存器堆进行寻址,寻址结果送至总线A_BUS和B_BUS,也可能是一个包含在指令中的常数直接送至总线B_BUS。
(3)指令执行
操作数A_BUS和B_BUS送入ALU中进行运算,运算结果送至总线C_BUS。如果需要,标志位被保存到状态寄存器中。
(4)存储器访问
如果需要,计算得出的C_BUS上的结果作为访问存储器的地址,数据从存储器取出后被保存到总线D_BUS上,如果不需要存储器访问,ALU计算的结果只是缓冲到C_BUS总线上。
(5)保存结果
如果需要,运算结果要送入寄存器堆中保存。这个结果可能是数据移动要写入数据寄存器的值,或者缓冲在C_BUS总线上的值。
2.数据通路的流水线
为了有效的平衡数据通路上各个硬件部件的执行,若干条指令可以并行地在硬件上执行。
所以,将整个数据通路嵌入5级流水线之中,这5级分别是取指令级IF、指令译码级ID、执行级EX、访问存储器级MA和回写级WB。
流水线数据通路的划分包括:
(1)IF级包括程序计数器PC、Cache以及存储器的接口DATA和ADDR。
(2)ID级包括寄存器堆REG、指令寄存器IR和保存标志位的处理器状态寄存器。
(3)EX级包括算术逻辑运算单元ALU。
(4)MA级包括缓冲器和连接ALU输出端口到WB级和存储器的接口。
(5)WB级包括缓冲器和连接MA级到寄存器堆的接口。
3.流水线执行方式的特征
流水线的引入表示在多个时钟周期内执行一条指令。
因此在应用软件的执行过程中,不希望存在延迟跳转、延迟装载、延迟软件中断。
ALU造成的存储器访问的延迟,可以通过前推机制予以解决。
延迟跳转含义是跳转程序中的指令(控制转移),只有在紧跟在控制转移指令之后的指令也进入流水线并执行后,才能被装载进处理器执行。
由于控制转移指令的识别只有在ID级才能完成,那么下一个地址上紧跟在控制转移指令之后的指令已经进入IF级。
紧跟在控制转移指令的地址空间称为延迟槽,在延迟槽中的指令称为延迟指令。
延迟指令将同正常指令一样执行,流经整个流水线。
执行延迟指令是为了避免无效指令的装载,而这种装载相当于在流水线中插入了一个空操作步骤。
延迟跳转的优点是提高流水线的吞吐率。
由于程序代码在存储器中可能有不同的保存位置,延迟跳转的有效使用取决于编译器设计的好与坏。
如果编译器不能对跳转指令进行优化可以在延迟槽中插入一条NOP指令。
为了进一步减小开销,条件跳转指令的延迟槽可以取消掉。ANNUL参数使得条件跳转指令在跳转不执行的情况下,自动用NOP指令代替延迟指令的执行。
禁止两条控制转移指令相邻执行,会导致跳转目的地址计算混乱。在这种情况下,会产生处理器中断。
延迟装载是在一条Load指令装载寄存器X之后,不允许紧接着的指令使用寄存器X中的值。
LD/ST指令和其他指令的重叠执行时可以的。
软件中断也具有延迟效应,因为软件中断被视为控制转移指令。
对目的寄存器的操作只有在两个流水线级之后才能生效,因为有EX级和WB级之间的延迟。
后续指令读取这个寄存器中的值会发生数据错误。
为了解决这个问题实现较好的流水线装载,将前推机制应用到执行级的两个操作数总线上。
前推机制需要增加额外的总线来抽取流水线不同级的数据值。
一个数据通路中ALU的B操作数上的前推机制。
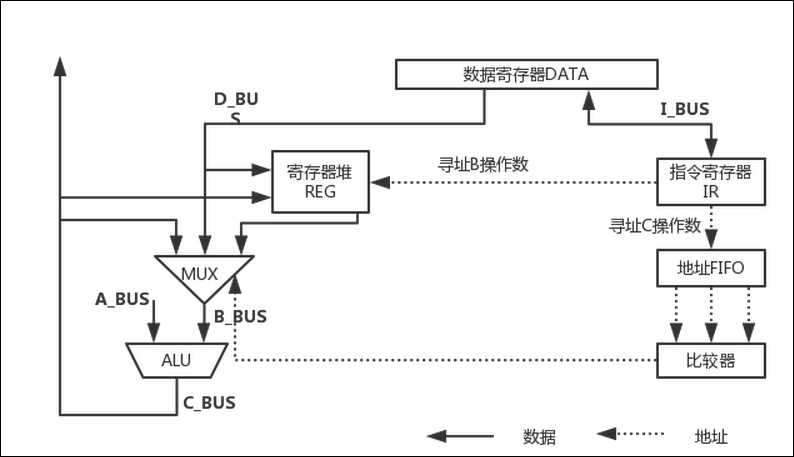
当两个前面的指令不对同一个寄存器赋值时,ALU的B操作数通常来自寄存器堆。如果之前的一条指令把该寄存器作为目的寄存器,当前的ALU运算结果保存在C_BUS总线上。
B操作数也可能来自C_BUS总线。B操作数也可能是MA的输出。
多选器MUX选择合适的源操作数据送入ALU的输入寄存器中。
选择操作数的判决信号是通过一个地址比较器,通过对现在源操作数寄存器地址与前两条指令的目的寄存器地址比较得出。