在人工智能的浪潮下,现在各类科技领域都要加上一点AI、深度学习、神经网络的概念,以免不落后于潮流。但是产品归产品,技术归技术。就人工智能当下的成熟度而言,笔者认为至少在信息安全领域,由专业的安全专家团队利用庞大的项目经验、客户运维经验组成的各类安全规则库能力依然是优于AI引擎的。类似于Exabeam之流采用机器学习的UEBA产品,无论实在公开案例还是我所了解的客户反馈均表示,客户专业的安全运维部门还是更依赖于基于规则库的SIEM。
当然,本篇文章并不是对比机器学习与传统规则库在安全领域的孰是孰非,而主要是介绍基于规则的安全事件关联分析模型。在这个模型之下,整个系统将以网络安全审计系统、终端安全Agent、服务器/业务系统日志、以及其他安全设备告警信息为基础,将与业务和安全息息相关的数据汇总分析,进而利用规则库将真正具有威胁的事件还原出来。具体的清洗流程如下:
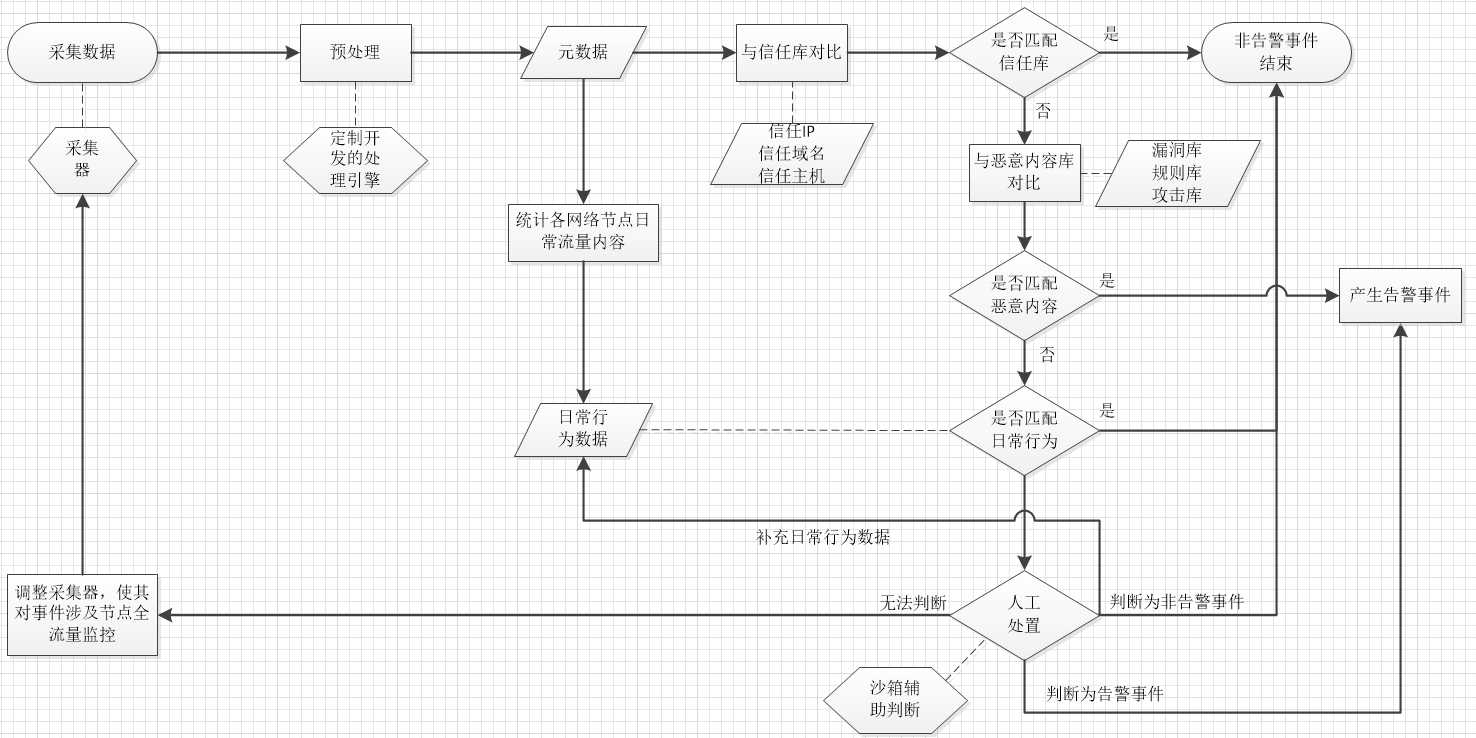
如上图所示,我们的核心目标是从海量审计数据中筛选出真实的、值得关注的告警事件。因此,流程需要执行预处理、日常行为汇总、规则库自动匹配、人工处置等步骤,以确保告警事件等到有效清洗。
整个业务流程第一步是数据采集,只有采集到分析系统关键数据才能有效提取具有威胁的告警事件,因此很多SIEM系统主打全量日志采集,将整个信息系统所有的网络通信以PCAP包采集、留存,将下到终端电脑开机、上到业务系统CPU利用率等日志全部打包。诚然,这样的采集方式必然能够采集足够多的数据进行更精确的分析,但是分析日志量过大导致的系统运行效率问题也是各种安全运维部门不得不面临的问题。笔者认为,安全事件关联分析模型所需的日志数据,以日常安全运维经验为出发,适当设置,分类采集即可。一个好的关联分析模型应具备自我完善机制,能够在分析过程中判断现有数据源是否满足分析需求。而自我完善机制的实现则可使整个分析系统的日志是一个渐进明细的过程,开始的日志采集量可能设置上确实存在偏差或不足,但经过不断完善和补充,将分析所需的日志逐步增加,则即能够满足关联需求,又能够减少日志采集量提高效率。
讲了一些关于数据采集的方案描述,我们来看下数据采集的后续流程。数据经由采集器采集到位后,先进行预处理,满足系统格式要求。经过完整性校验、数据去重、原始数据格式化等步骤,将采集器获取的数据转化为能够为后续流程所用的元数据信息。元数据信息需要经过两方面处理,一方面通过统计算法,将网络各节点互相通信的协议、端口、子网、源目的IP、物理位置等信息进行综合分析,得出网络中各节点常见访问的应用、传输的协议、所在子网和位置等日常信息,并整理为日常行为数据库。
另一方面,元数据信息需要进行一系列的匹配流程。首先,元数据信息需要和信任库进行匹配。信任库记录了由网络管理员配置的各类合规数据,包括信任协议、信任源目的IP、信任端口、信任主机、信任域名等信息。信任库能描述日常业务中安全、可靠各类行为,因此一旦元数据信息与信任库匹配,则可判定为非告警事件,流程结束。
如果元数据信息未能匹配信任库,则需要与漏洞库、攻击库、病毒库等一系列针对恶意行为的规则库进行匹配,一旦匹配相关内容,则产生适配结果,则判断为告警,将事件确定下来。如果元数据未能匹配规则库,则需要利用之前步骤建立的日常行为数据库进行对比,通过特定算法打分、判定,确认元数据行为与日常行为的匹配度,当匹配度超过阈值时,判研为正常流量,不予处理。
考虑到非日常行为并不能直接断定为网络攻击,因此,不能匹配信任库、规则库和日常行为数据库的元数据需要人工进行判定。人工判定可运用沙箱技术进行辅助,通过将虚拟执行环境中运行的结果展示给管理员,能够更好的辅助人工进行告警判定。如果人工判定结果为告警事件,则元数据成为告警数据之一。如果人工判定为非告警事件,不仅告警判研流程结束,且该元数据通过规则存入日常行为数据库,为后续自动判研做知识储备。
如果人工告警仍不能判定元数据是否为告警事件,则需要调整采集器收集数据的范围,将数据采集类型扩大,以便下次同类型数据能够准确分析出判研结论。这就是前面所说数据采集的自我完善机制。在人工告警判定过程中,免不了安全专家、业务专家的接入,而这些人力分析过程将会根据分析人员实际的知识储备和经验进行分析,如果采集的数据不满足判定条件,相关分析人员也能够判断需要哪些条件和参数才能够进行准确判断。因此在安全运维部门的介入下,可以人工调整相关采集策略,确保相关采集器能够更精准的采集到所需数据。
经过预处理、日常行为汇总、规则库自动匹配、人工处置等步骤后,我们最终可得出真实度较高,噪音较少的,真正具备威胁的告警事件。