MapReduce是什么?
Hadoop MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成地大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别地海量数据集。
MapReduce工作机制
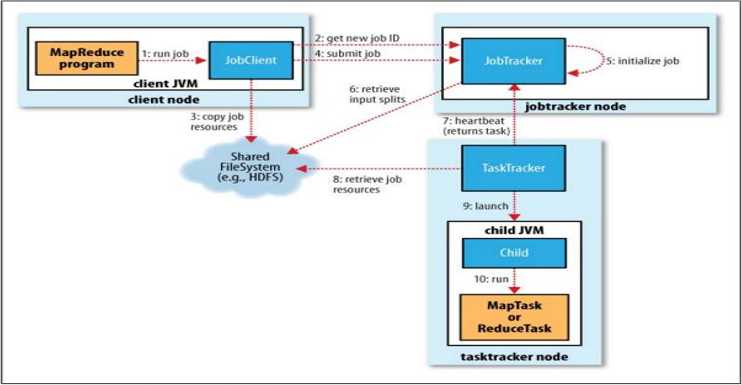
Mapreduce 的4个对象
1、客户端:编写mapreduce程序,配置任务,提交任务。
2、JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行。
3、TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行Map或Reduce任务,TaskTracker和JobTracker的不同有个很重要的方面,就是在执行任务时候TaskTracker可以有n多个,JobTracker则只会有一个(JobTracker只能有一个就和hdfs里namenode一样存在单点故障)。
4、HDFS:保存作业的数据、配置信息等,最后的结果也是保存在HDFS上面。
MapReduce运行步骤:
首先是客户端要编写好mapreduce程序,配置好mapreduce的作业也就是job,接下来就要提交job,提交job是提交到JobTracker上的,这个时候JobTracker就会构建这个job,具体就是分配一个新的job任务的ID值。
接下来它会做检查操作,这个检查就是确定输出目录是否存在,如果存在那么job就不能正常运行下去,JobTracker会抛出错误给客户端,接下来还要检查输入目录是否存在,如果不存在同样抛出错误,如果存在JobTracker会根据输入计算输入计算输入分片(Input Split),如果分片计算不出来也会抛出错误。当这些都做好了JobTracker就会配置Job需要的资源了。
分配好资源后,JobTracker就会初始化作业,初始化主要做的是将Job放入一个内部的队列,让配置好的作业调度器能调度到这个作业,作业调度器会初始化这个job,初始化就是创建一个正在运行的job对象,以便JobTracker跟踪job的状态和进程。
初始化完毕后,作业调度器会获取输入分片信息(input split),每个分片创建一个map任务。
接下来就是任务分配了,这个时候TaskTracker会运行一个简单的循环机制定期发送心跳给JobTracker,心跳间隔是5秒,程序员可以配置这个时间,心跳就是JobTracker和TaskTracker沟通的桥梁,通过心跳,Jobtracker可以监控TaskTracker是否存活,也可以获取TaskTracker处理的状态和问题。同时TaskTracker也可以通过心跳里的返回值获取JobTracker给它的操作指令。
任务分配好后就是执行任务了。在任务执行时候JobTracker可以通过心跳机制监控TaskTracker的状态和进度,同时也能计算出整个job的状态和进度,而TaskTracker也可以本地监控自己的状态和进度。当JobTracker获得了最后一个完成指定任务的TaskTracker操作成功的通知时候,JobTracker会把整个job状态置为成功,然后当客户端查询job运行状态时(这个是异步操作),客户端会查到job完成的通知的。如果job中途失败,mapreduce也会有相应机制处理,一般而言如果不是程序员本身有bug,mapreduce错误处理机制能够保证job能正常完成。