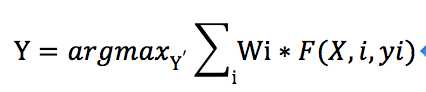引自Fabian Suchanek的讲义。
总结:主要讲了NERC的四种方式, NERC Feature,NERC rules, NERC ML和statistical NERC。NERC Feature主要讲在一个窗口中,其他token可以根据三种不同的features定下自己是什么分类,从而定义主token是什么分类。NERC rules主要讲述一种建立rules来判断token分类的方法,若某个句子或某个部分中的词满足该rule中的特征,那么就可以知道主token是哪一类,当然在面对非常大型的语料库也应该有自动建立rules的算法,本文中也有提到;NERC ML讲述的是使用机器学习做NERC,主要讲述了KNN对NERC的应用,即找到该token附近的token的分类,定义好K的值,看K个最近邻居主要在哪一类则该token就在哪一类;statistical NERC主要要知道如何找到使语料库权重最大的Y向量,若面对大型语料库时,我们无法手动定义权重,则需要有算法去计算权重,主要讲述了两个步骤,如何根据给定的语料库向量X和分类向量Y来计算W,计算了W的概率分布,用到了梯度上升,即计算使该概率分布最大的W,然后根据W的值在去判断新的语料库的标签,也是机器学习的过程,学习+测试。
NERC:找到语料库中entity名字并把它们分类
例如:在tsv中,41,tower,Other
41是句子号码,tower是单词,Other是类
做NERC遇到的困难:
- 同一个词有不同的意思
n 例如:MTV可以使音乐电视,也可以是大屏幕
- 二义性
文章中讲了四种NERC的方式:
1 - NERC Feature
代币Token:一系列字母组成的一个个体
窗口Window:宽度为a,代表在此窗口里,主代币前有a个单词,后面有a个单词,则整个窗口宽度2*a+1
例如:主token的前一个单词位置为-1
NERC特征NERC Feature:一个代币的属性可以指出窗口内主token的类
主要有这么几种Feature:
- 句法特征Syntactic Feature:例如大小写,数字,空格,正则
- 字典特征Dictionary Feature:例如城市,国家
- 形态特征Morphological Features:例如:-ist,-isme,……
n POS:part of speech,代表有相同语法角色的词
2 - NERC by rules
规定Rules:f1……fn=>c , f是指定特征designated feature
若一个window中的token们可以满足rule里的feature,那么主token就会被分到c类
小练习:自己建立rules来找到文章中的planet
Lamuella is the nice planet where Arthur Dent lives. Santraginus V is a planet with marble-sanded beaches. Magrathea is an ancient planet in Nebula. The fifty-armed Jatravartids live on Viltvodle VI.
[CapWord] is the nice planet
[CapWord] is a planet
[[CapWord]] is an ancient planet
The fifty-armed Jatravartids live on [CapWord RomanNumeral]
若两个rule都找到了对应的字符串,该如何选择:
- 使用较长匹配的规则
- 手动定义顺序
如何写NERC rules:
- 比较难编程的rules
- 用正则
NERC rules一般是手动定义,但是也是可以学习的
- 有一个已被注释的训练语料库
- 对于里面的每一个注释都建立一个rule
- 把rules合并,用一个更泛化的特征来代替
n 例如: [Author]… [Ford]… => [Capword]…
- 把rules合并并删掉一个feature
n 例如:[Capword] says Hello ; [Capword] says bye
n => [Capword] says
- 删掉重复的rules
- 重复这个过程
NERC rules要实现起来还是很困难的,因为句子成分很复杂
NERC rules的目标:
- 学习所有已注释的规则
- 忽略未注释的规则
- 不需要太多rules,因为并不需要一个注释一个rules
3 - NERC by ML
NERC可以被机器学习实现:
- 给出训练实例,即一个已经被备注好的语料库
- 给语料库中未注释的单词预测tag
KNN:根据该词的最近邻居决定该词属于哪一类
K是被固定的,为了减小噪声;一般为奇数odd
原始距离函数Na?ve distance function:说明第i个feature应用于第j个位置上的与住token相关的token
例如: = upper case
Everyone loves <per> Fenchurch </per> because
= 1; = 0
附近K个邻居属于哪一类那此token属于哪一类
使用欧几里得距离Euclidien distance
4 - NERC by statistical methods
统计NERC语料库NERC by statistical corpus:是一个token构成向量,输出是一个class向量,分别对应之前向量中的tokens
特征Feature:是一个函数,长这样:f(X,i ,y)
X是token向量,i是在向量中的位置,y为class向量
例如:f1(X,i,y) := 1if xi?1 is title∧y=“pers”
f1(<Mr., Arthur>,1,pers) = 0 f1(<Mr., Arthur>,2,pers) = 1 f1(<Mr., Arthur>,1,loc) = 0
统计NERC的目标是根据给出的tokens向量X,给出的Features向量,权重向量,来计算分类向量Y=[y1,y2,…],尽可能使,即对于每个位置i,每个feature j,我们计算权重乘以1/0.
小练习1:计算每个Y向量所能得到的权重
X = <Dr. Dent>
F1(X,i,y) = 1 if xi = upcased word and y = loc w1 = 2
F2(X,i,y) = 1 if xi-1 is title and y = pers w2 = 5
Y1 = [oth, loc] 2 * 0 + 5 * 0 (Dr.) + 2 * 1 + 5 * 0 (Dent) = 0
Y2 = [oth, pers] 2 * 0 + 5 * 0 (Dr.) + 2 * 0 + 5 * 1 (Dent) = 5
所以Y2更好
小练习2:计算出大于权重3的Y
X = <in London>
F1(X,i,y) = 1 if xi = upcased and y = pers w1 = 2
F2(X,i,y) = 1 if xi-1 = “in”and y = loc w2 = 5
F3(X,i,y) = 1 if y = oth w3 = 1
Y1 = [oth, pers] 2 * 0 + 5 * 0 + 1 * 1 + 2 * 1 + 5 * 0 + 1 * 0 = 3
Y2 = [oth, loc] 2 * 0 + 5 * 0 + 1 * 1 + 2 * 0 + 5 * 1 + 1 * 0 = 5
Etc……
我们现在的算法是,根据给定的corpus向量X,每个单词在向量中的位置i,和权重向量W来计算分类向量Y,当需要计算的分了向量Y比较复杂时我们该如何做?每条rule的权重该如何得到?
建立NERC模型:
1 - 定义Features向量F = <f1,……,fn>
2 - 生成训练集,由corpus向量X和分类向量Y构成
X = <x1,……,xm>, Y = <y1,…… ,ym>
3 - 根据X,Y,找到每条rule的权重w,使X和Y能够很好的对应
例如好的Features权重高,不好的权重低
根据计算出的w,我们可以算关于w的概率分布,公式如下:
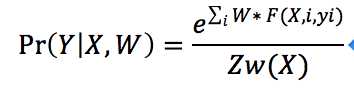
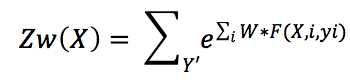
所以Pr的上方是计算每个位置上的feature的权重之和,为了使概率分布在[0,1],下方是除以其他所有注释Y,即在上方里没有用到的Y向量的可能世界。
我们最大化这个概率分布Pr:
因为ln是单调函数,所以我们可以直接在左右两边都套上ln:
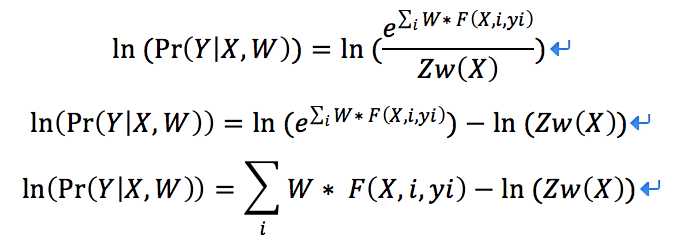
所以我们可以看出在这个式子中,除了w,其余都为constant。所以我们使用梯度上升法使该等式最大化,算法为:
1 - 随机定义一个W
2 - 计算该式子关于W的偏导
3 - 使W在导数方向进行梯度上升,即
4 - 直至该式子达到最大
所以关于statistical NERC,我们给出的变量有:corpus向量X,位置i,用于训练的分类向量Y,特征向量F,我们首先要得到能使概率分布最大的权重向量w (学习):
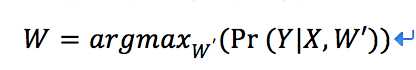
之后我们给出新的语料库,我们根据计算出的W,来计算它的分类向量Y: