前言
redis数据存储在内存中, 就会受到内存的限制, 大家都知道, 一台电脑, 硬盘可以有1T, 但是内存, 没有听说有1T的内存吧.
那如果数据非常多, 超过一台电脑的内存空间, 怎么办呢?
正常思维, 都是, 一台电脑不够, 那我再加一台电脑嘛, 不就够了.
redis集群架构图
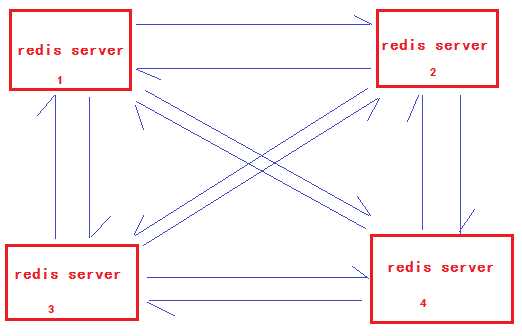
每一台redis server之间都是保持通讯的. 也就是说, 如果 server1 上面没有要查找的值, 会跳转到别的服务器上查找.
注:
如果其中有一个服务器挂了, 如 server4 挂了. redis是怎么处理的呢?
redis集群中, 有一个投票机制, 当server4挂了之后, 会由server1, server2, server3 共同投票, 因为他们都与server4有通讯关系, 当大家都认定server4 确实挂了之后, 大家的投票结果就是, 大家可以休息了, 下班了.
那很明显, 这里有不合理性. 那怎么解决呢?
在集群中, 为了保证一台机子挂了之后, 系统任然正常运行, 一个常用的方法是加备份机.(备胎)
redis中也是这样, 如果给每一台机子上加一台备份机, 那么大家投票认为server4挂了之后, 备胎就有福了. 可以取而代之. 这样就可以保证, 系统还可以正常运行.
搭建集群
根据上面的架构图, 以及投票机制和备胎机制, 一个合格的redis集群, 应该是要6台电脑. 作为我个人来讲, 我去哪里弄6台电脑啊, 装6台虚拟机还差不多. 但是同时跑6台虚拟机, 你累不累啊?
既然没有那么多电脑, 也不想装那么多虚拟机, 那么久来个伪集群吧. 到生产环境中, 需要多台电脑来搭建集群的时候, 步骤是一样的. 结果其实也是一样的, 没差, 甚至更简单点.
一. 搭建多个redis
接着前面的篇幅中的redis文件.
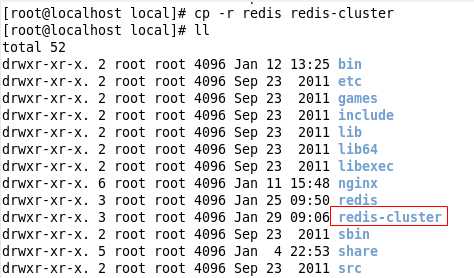
1. 拷贝创建redis-cluster文件夹
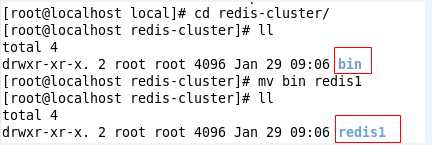
2. 进入redis-cluster, 将bin文件重命名
3. 对redis1下的redis.conf文件进行端口和集群配置
vim ./redis1/redis.conf
3.1 端口修改

3.2 允许集成开关
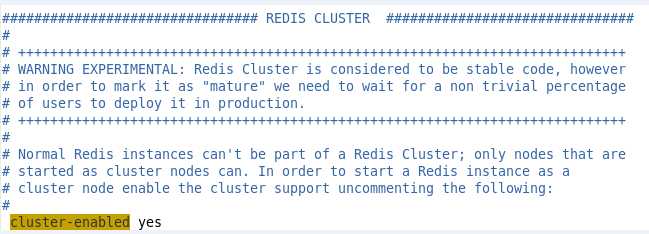
这里默认是被注释掉的. 只要打开注释就可以了
4. 将redis1复制5份出来, 分别命名为redis2,redis3, redis4, redis5, redis6
5. 修改redis2~redis6的端口号, 分别为7002~7006. 修改方式与3.1一样的.
6. 创建一把启动脚本. vim start-all.sh
cd /usr/local/redis-cluster/redis1 ./redis-server redis.conf cd ../redis2 ./redis-server redis.conf cd ../redis3 ./redis-server redis.conf cd ../redis4 ./redis-server redis.conf cd ../redis5 ./redis-server redis.conf cd ../redis6 ./redis-server redis.conf
7. 修改start-all.sh的权限
如果不改权限, 直接运行, 是跑不起来的
[root@localhost redis-cluster]# chmod u+x start-all.sh
修改完之后, 就可以牵出来溜一下, 看看是否都能跑起来
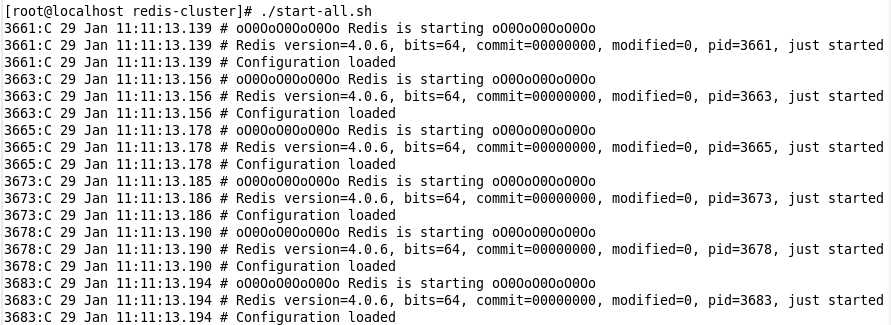
通过ps看一下

8. 创建一把结束脚本 vim shutdown-all.sh
有始有终, 一把开始, 当然也需要一把结束, 总不能一个一个去结束吧, 太麻烦了
cd /usr/local/redis-cluster/redis1 ./redis-cli -p 7001 shutdown cd ../redis2 ./redis-cli -p 7002 shutdown cd ../redis3 ./redis-cli -p 7003 shutdown cd ../redis4 ./redis-cli -p 7004 shutdown cd ../redis5 ./redis-cli -p 7005 shutdown cd ../redis6 ./redis-cli -p 7006 shutdown
同样的, 这个脚本也需要修改访问权限, 与上面是一样的.
chmod u+x shutdown-all.sh
跑一下这个脚本看看
[root@localhost redis-cluster]# ./shutdown-all.sh
这时候, 再通过ps看看

都关掉了.
二. 集群
注:
在开始搭建之前, 有一些概念, 要搞清楚.
在redis-cluster中, 吧所有的物理节点都映射到[0-16383]个slot(槽)上, 由cluster负责维护.
那具体是怎么分配这些槽的呢?
当有一个数据进来需要进行缓存时, redis会先对key使用crc16算法, 计算出一个结果, 然后对16384进行取余, 这样, 每个key都会得到一个在0-16383之间的数, 这个数, 就是他的槽值. 根据这个数, 将数据存入槽所在的电脑里面.
也就是说, 如果有3台电脑A,B,C, A->[0, 5000], B->[5001, 10000], C->[10001, 16383]. 进来一个值, key计算最后结果是5005, 则会将这个值存入B电脑里面. 再进来一个值, key计算是10010, 则会存入C电脑中.
这个槽点, 并不是key的个数, 这里需要注意以下. 理论来说, 可以进行16284台电脑的集群, 每台电脑分一个槽. 但是每个电脑, 肯定会存一堆值.
1. 拷贝redis-trib.rb文件到redis-cluster中
[root@localhost redis-cluster]# cd /usr/java/redis-4.0.6/src/ [root@localhost src]# cp redis-trib.rb /usr/local/redis-cluster/
2. 安装ruby
上面拷贝的文件, 是rb后缀的, 从这个后缀, 应该能看出为啥要安装ruby吧
yum install ruby
yum install rubygems
安装完成之后, 还需要安装一个 gem
gem install redis --version 3.0.0
3. 使用ruby脚本搭建集群
./redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006
在搭建集群的时候, 有可能会报一个错误

这个是为啥呢?
在集群的时候, 需要保证各redis都是空的, 里面不存数据的. 所以, 这里就需要我们手动来清一下数据.
在将 各 redis 启动之后, 执行flushdb命令
[root@localhost redis-cluster]# ./redis1/redis-cli -h 127.0.0.1 -p 7001 127.0.0.1:7001> flushdb OK 127.0.0.1:7001> [root@localhost redis-cluster]# ./redis1/redis-cli -h 127.0.0.1 -p 7002 127.0.0.1:7002> flushdb OK 127.0.0.1:7002> [root@localhost redis-cluster]# ./redis1/redis-cli -h 127.0.0.1 -p 7003 127.0.0.1:7003> flushdb OK 127.0.0.1:7003> [root@localhost redis-cluster]# ./redis1/redis-cli -h 127.0.0.1 -p 7004 127.0.0.1:7004> flushdb OK 127.0.0.1:7004> [root@localhost redis-cluster]# ./redis1/redis-cli -h 127.0.0.1 -p 7005 127.0.0.1:7005> flushdb OK 127.0.0.1:7005> [root@localhost redis-cluster]# ./redis1/redis-cli -h 127.0.0.1 -p 7006 127.0.0.1:7006> flushdb OK 127.0.0.1:7006>
如果清除之后还不行, 则删除
目录中的dum.rdb, nodes.conf, appendonly.aof 文件, 每一个redis都要删.
做完了这些, 一件很重要的事情别忘了: 重启以下redis , 否则, 在集群的时候, 还是会报错的
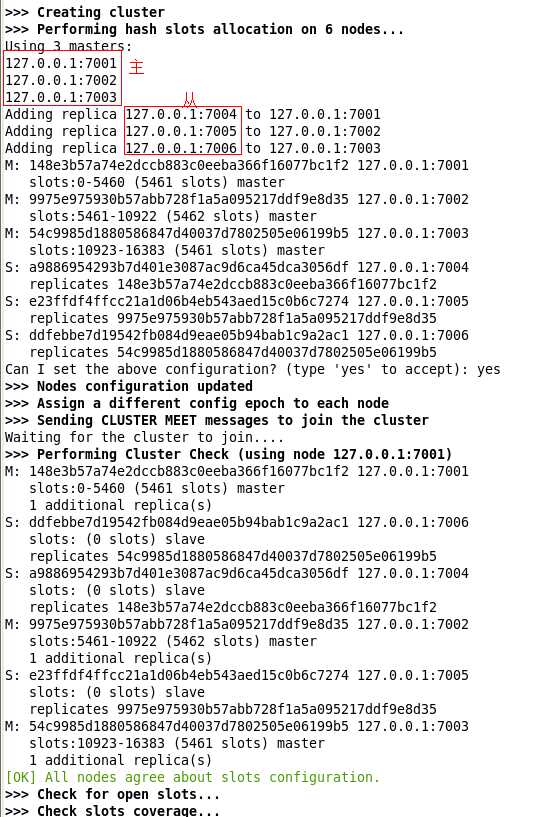
4. 使用
通过以上的步骤, 就将redis集群搭建好了, 接下来, 就是来验证一番.
连接集群的时候和连接单机的时候, 稍有不同, 需要在连接指令后面加上 -c
[root@localhost redis-cluster]# ./redis1/redis-cli -p 7001 -c
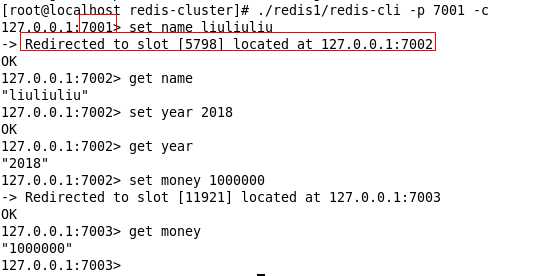
在存储的时候, 会根据key计算, 找到存放的电脑, 跳转过去存放
那现在我存放了三个值, 分别在7002, 7003里面, 7001里面没有存值, 还是看的出来的. 现在我通过7001来取一下, 看看可能取出来
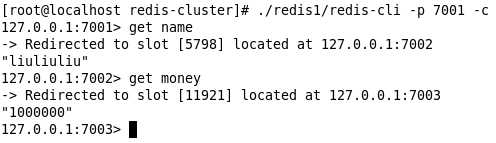
在我取的时候, 也是会跳转到相应的存储服务器取数据.