1.单表关联
"单表关联"要求从给出的数据中寻找所关心的数据,它是对原始数据所包含信息的挖掘。
实例描述
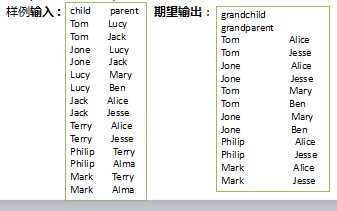
给出child-parent(孩子——父母)表,要求输出grandchild-grandparent(孙子——爷奶)表。
算法思想:
这个实例需要进行单表连接,连接的是左表的parent列和右表的child列,且左表和右表是同一个表。连接结果中除去连接的两列就是所需要的结果——"grandchild--grandparent"表。要用MapReduce解决这个实例,首先应该考虑如何实现表的自连接;其次就是连接列的设置;最后是结果的整理。MapReduce的shuffle过程会将相同的key会连接在一起,所以可以将map结果的key设置成待连接的列,然后列中相同的值就自然会连接在一起了。
1.map阶段将读入数据分割成child和parent之后,将parent设置成key,child设置成value进行输出,并作为左表;再将同一对child和parent中的child设置成key,parent设置成value进行输出,作为右表
2.为了区分输出中的左右表,需要在输出的value中再加上左右表的信息,比如在value的String最开始处加上字符1表示左表,加上字符2表示右表
3. reduce接收到连接的结果,其中每个key的value-list就包含了"grandchild--grandparent"关系。取出每个key的value-list进行解析,将左表中的child放入一个数组,右表中的parent放入一个数组,然后对两个数组求笛卡尔积就是最后的结果了
代码实例:
public class table01 {
static String INPUT_PATH="hdfs://master:9000/input/i.txt";
static String OUTPUT_PATH="hdfs://master:9000/output/singletable01";
static class MyMapper extends Mapper<Object,Object,Text,Text>{ //输入为字符串类型
Text output_key=new Text();
Text output_value=new Text();
protected void map(Object key, Object value, Context context) throws IOException, InterruptedException{
String[] tokens=value.toString().split(","); //以,分割
if(tokens!=null && tokens.length==2){ //判断表分割成两列
output_key.set(tokens[0]); //将child作为右表的key值,右表标记为2
output_value.set(2+","+value);
context.write(output_key, output_value);
output_key.set(tokens[1]); //将parent列作为key值,作为左表,标记为1
output_value.set(1+","+value);
context.write(output_key, output_value); //将一个表分割成了两个表
System.out.println(tokens[0]+"--"+tokens[1]);
}
}
}
static class MyReduce extends Reducer<Text,Text,Text,Text>{ //传入到MapReduce变成这样的格式: lucy , {1,tom,lucy 2,lucy,mary}
Text output_key=new Text();
Text output_value=new Text();
protected void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
List<String> childs=new ArrayList();
List<String> grands=new ArrayList();
for(Text line:values){
String[] tokens=line.toString().split(",");
if(tokens[0].equals("1")){ //判断是左表的话,即parent作为key值的时候,将孩子加入队列中
childs.add(tokens[1]);
System.out.println(1+"--"+tokens[1]);
}
else if(tokens[0].equals("2")){ //右表,childs作为key值,将祖父母加入队列
grands.add(tokens[2]);
System.out.println(2+"--"+tokens[2]);
}
}
for(String c:childs){ //循环输出
for(String g:grands){
output_key.set(c);
output_value.set(g);
context.write(output_key, output_value);
}
}
}
}
public static void main(String[] args) throws Exception{
Path outputpath=new Path(OUTPUT_PATH);
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job,outputpath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.waitForCompletion(true);
}
}
2.多表关联
实例描述
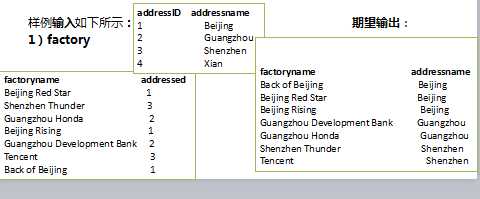
输入是两个文件,一个代表工厂表,包含工厂名列和地址编号列;另一个代表地址表,包含地址名列和地址编号列。要求从输入数据中找出工厂名和地址名的对应关系,输出"工厂名——地址名"表 。
算法思想:
多表关联和单表关联相似,都类似于数据库中的自然连接。相比单表关联,多表关联的左右表和连接列更加清楚。所以可以采用和单表关联的相同的处理方式,map识别出输入的行属于哪个表之后,对其进行分割,将连接的列值保存在key中,另一列和左右表标识保存在value中,然后输出。reduce拿到连接结果之后,解析value内容,根据标志将左右表内容分开存放,然后求笛卡尔积,最后直接输出。
public class table02 {
static String INPUT_PATH="hdfs://master:9000/doubletable";
static String OUTPUT_PATH="hdfs://master:9000/output/doubletable";
static class MyMapper extends Mapper<Object,Object,Text,Text>{
Text output_key=new Text();
Text output_value=new Text();
String tableName=""; //区分表名
protected void setup(Context context)throws java.io.IOException,java.lang.InterruptedException{
FileSplit fs=(FileSplit)context.getInputSplit(); //将多个表格区分开来
tableName=fs.getPath().getName(); //得到表名
System.out.println(tableName);
}
protected void map(Object key, Object value, Context context) throws IOException, InterruptedException{
String[] tokens=value.toString().split(",");
if(tokens!=null && tokens.length==2){
if(tableName.equals("l.txt")){ //如果是表一的话
output_key.set(tokens[1]); //将addressID作为key值连接
output_value.set(1+","+tokens[0]+","+tokens[1]); //1只是一个标记
}
else if(tableName.equals("m.txt")){ //如果是表二的话
output_key.set(tokens[0]); //addressID是第一个属性
output_value.set(2+","+tokens[0]+","+tokens[1]);
}
context.write(output_key, output_value);
}
}
}
static class MyReduce extends Reducer<Text,Text,Text,Text>{
Text output_key=new Text();
Text output_value=new Text();
protected void reduce(Text key,Iterable<Text> value,Context context) throws IOException,InterruptedException{
List<String> factorys=new ArrayList();
List<String> addrs=new ArrayList();
for(Text line:value){
String[] tokens=line.toString().split(",");
if(tokens[0].equals("1")){ //表一取出factory的值
factorys.add(tokens[1]);
}
else if(tokens[0].equals("2")){
addrs.add(tokens[2]); //表二取出address的值
}
}
for(String c:factorys) //循环输出
for(String g:addrs){
output_key.set(c);
output_value.set(g);
context.write(output_key,output_value);
}
}
}
public static void main(String[] args) throws Exception{
Path outputpath=new Path(OUTPUT_PATH);
Configuration conf=new Configuration();
FileSystem fs=outputpath.getFileSystem(conf);
if(fs.exists(outputpath)){
fs.delete(outputpath, true);
}
Job job=Job.getInstance(conf);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job,outputpath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.waitForCompletion(true);
}
}